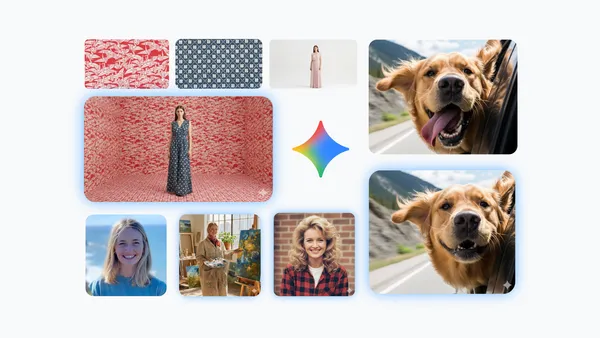
4 tips for using Nano Banana to create amazing images
Get the scoop on how to use Nano Banana, the Gemini app’s viral new image generation and editing model from Google DeepMind.
Get the scoop on how to use Nano Banana, the Gemini app’s viral new image generation and editing model from Google DeepMind.
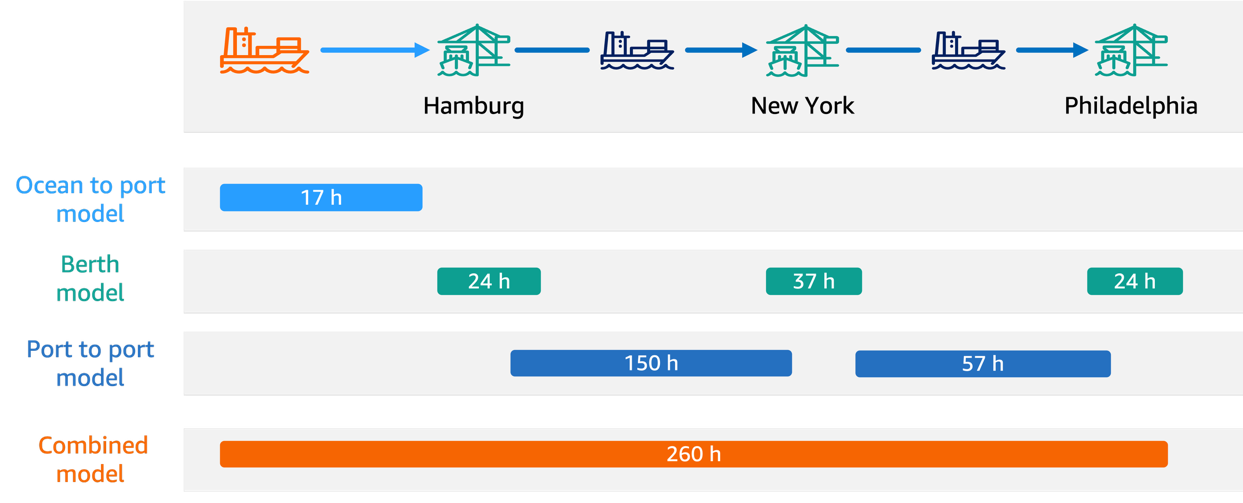
This post is cowritten with Thomas Voss and Bernhard Hersberger from Hapag-Lloyd. Hapag-Lloyd is one of the world’s leading shipping companies with more than 308 modern vessels, 11.9 million TEUs (twenty-foot equivalent units) transported per year, and 16,700 motivated employees in more than 400 offices in 139 countries. They connect continents, businesses, and people through …
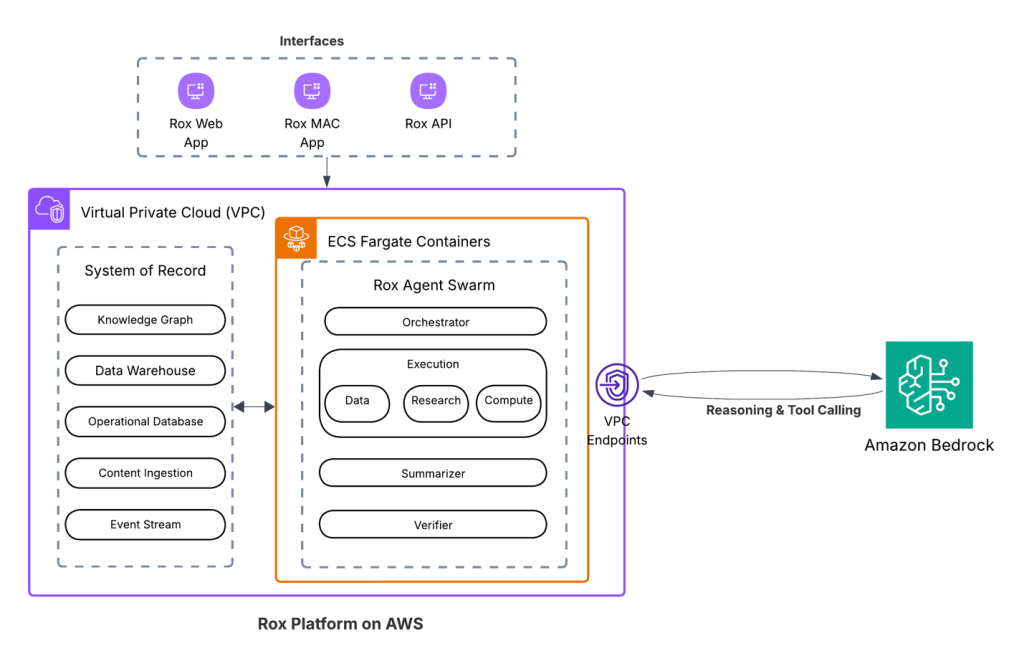
This post was co-written with Shriram Sridharan, Taeuk Kang, and Santhosh Kumar Manavasi Lakshminarayanan from Rox. Rox is building a new revenue operating system for the applied AI era. Modern revenue teams rely on more data than ever before, such as Customer Relationship Management (CRM) systems, marketing automation, finance systems, support tickets, and live product …
Rox accelerates sales productivity with AI agents powered by Amazon Bedrock Read More »

Google DeepMind collaborated with designer Ross Lovegrove and design office Modem.

Google and the University of Waterloo are bringing together their respective expertise in AI and innovative co-op education. This collaboration will fund a new research …

The Global AI Film Award is now accepting applications from creators using Google AI tools, with the winner awarded a prize of USD 1 million by the 1 Billion Followers S…
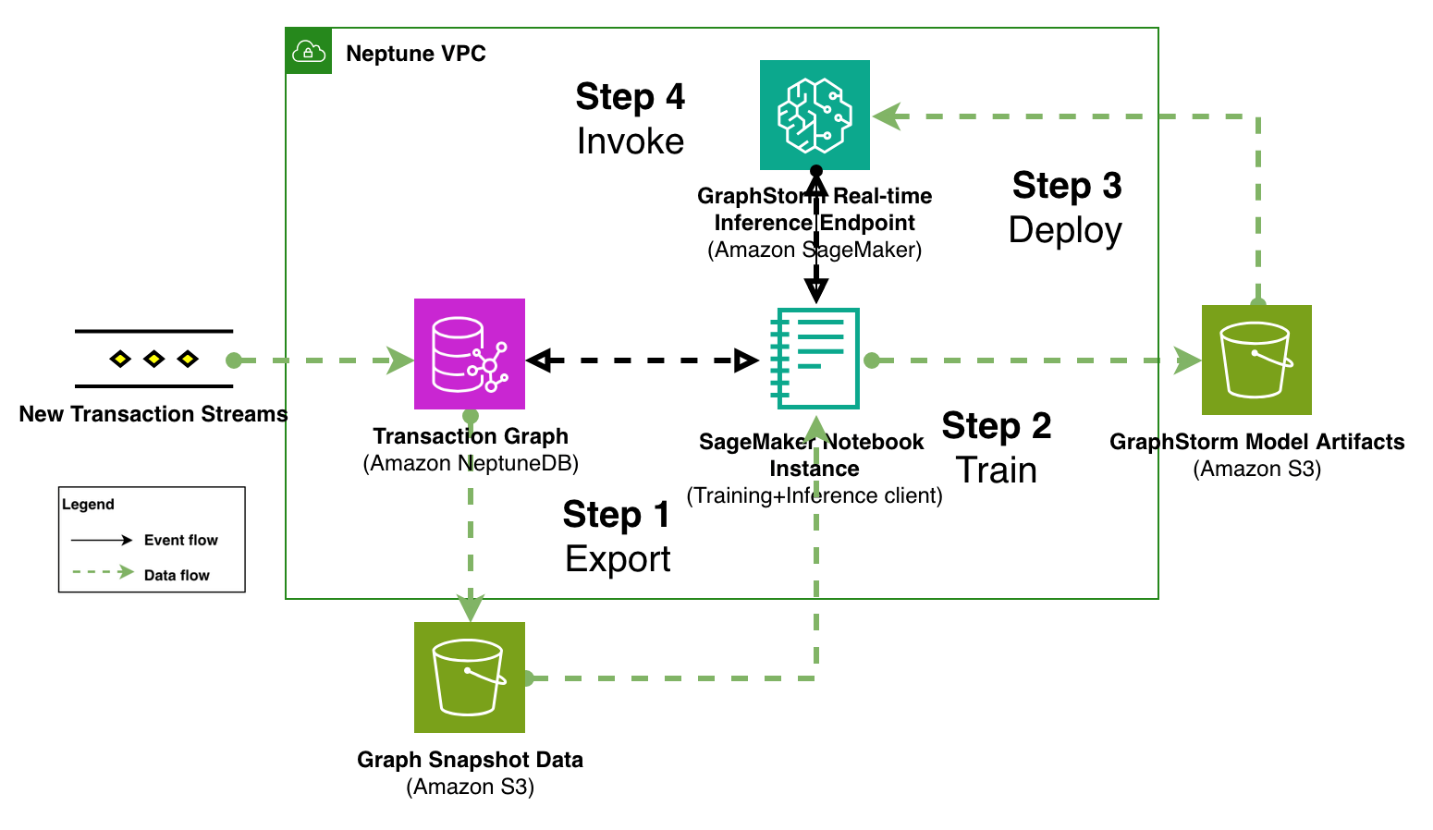
Fraud continues to cause significant financial damage globally, with U.S. consumers alone losing $12.5 billion in 2024—a 25% increase from the previous year according to the Federal Trade Commission. This surge stems not from more frequent attacks, but from fraudsters’ increasing sophistication. As fraudulent activities become more complex and interconnected, conventional machine learning approaches fall short …
Modernize fraud prevention: GraphStorm v0.5 for real-time inference Read More »
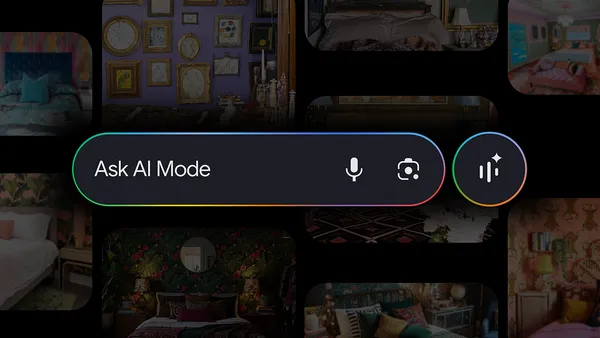
We’re redefining how you imagine, find and shop for just what you’re looking for in Search.

Ten years ago, we introduced Google’s signature four-color G to match the new look and feel of our logo. The design update reflected all the ways people interacted with …

Ten years ago, we introduced Google’s signature four-color G to match the new look and feel of our logo. The design update reflected all the ways people interacted with …