Cost-effective multilingual audio transcription at scale with Parakeet-TDT and AWS Batch
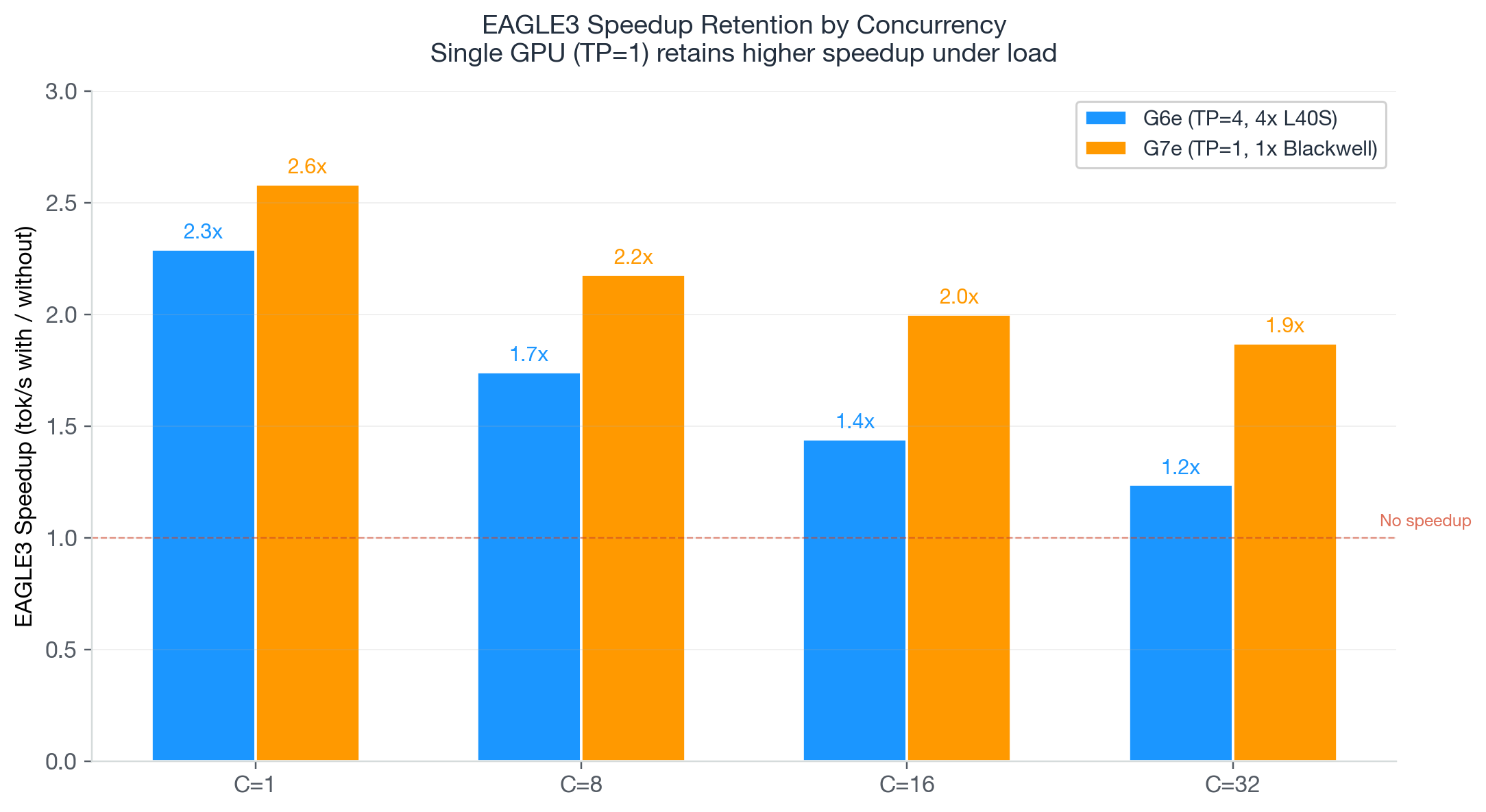
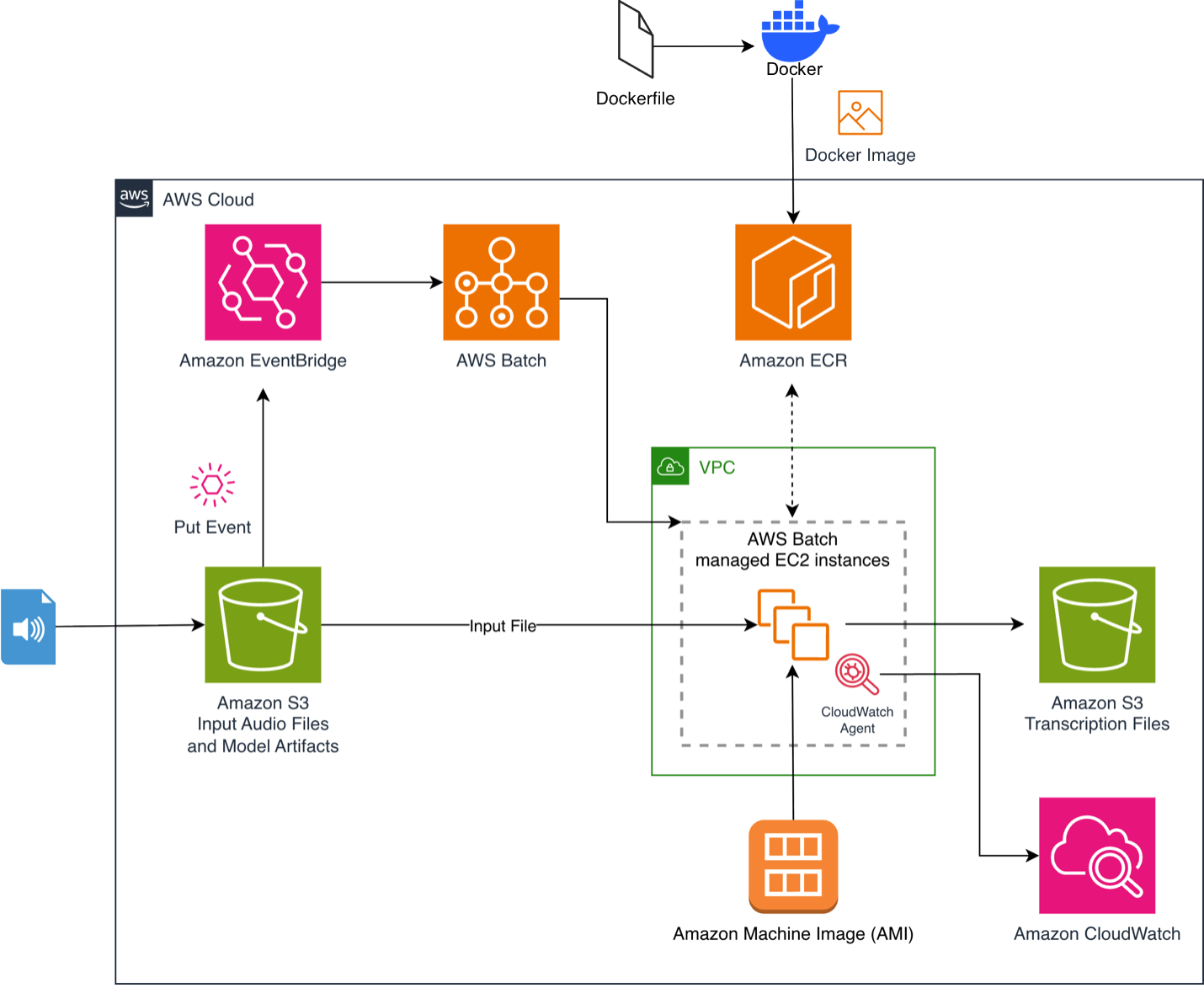
Many organizations are archiving large media libraries, analyzing contact center recordings, preparing training data for AI, or processing on-demand video for subtitles. When data volumes grow significantly, managed automatic speech recognition (ASR) service costs can quickly become the primary constraint on scalability. To address this cost-scalability challenge, we use the NVIDIA Parakeet-TDT-0.6B-v3 model, deployed through […]
Cost-effective multilingual audio transcription at scale with Parakeet-TDT and AWS Batch Read More »