Training a multi-turn agent in Amazon SageMaker AI to resolve support tickets or moderate content means handling a sequence of dependent steps, not a single response. These agents read instructions, make tool calls, read the results, decide the next action, and recover from a mistake before committing to an answer. That flexibility is also what makes agentic reinforcement learning (RL) challenging. More ways to act mean more ways to satisfy the reward without doing the task, and the environment the agent trains against can quietly corrupt the training signal.
In this post, we share best practices for reliable multi-turn RL training. We cover how to build a training environment you can trust, set up an external evaluation, design a reward aligned with the end task, manage what changes once the agent runs for multiple turns, and monitor the metrics that tell you when to iterate. We draw our examples from the SOP-Bench dataset, an Amazon Science benchmark that evaluates agents’ ability to resolve tasks based on complex Standard Operating Procedures (SOP) across 12 business domains.
SageMaker AI multi-turn reinforcement learning
Amazon SageMaker AI multi-turn RL (SageMaker AI MTRL) provides the training loop for agentic tasks. Your agent can run on Amazon Bedrock AgentCore, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Compute Cloud (Amazon EC2), AWS Fargate, or infrastructure of your choice. You connect it through a small adapter that exposes your tool surface to the rollout server, and SageMaker AI MTRL handles the rest:
- A modular agent-environment interface that keeps integration low-code while giving you full algorithmic control. Custom rewards, custom tool loops, and multi-turn conversation shapes are all yours to define.
- Serverless execution that simplifies infrastructure concerns, so you get production-scale agentic RL at per-token pricing without provisioning or managing GPU clusters.
- Asynchronous rollout and trajectory collection with bounded off-policy staleness. Generation and gradient updates run in parallel without drifting too far from the current policy, which speeds up training.
- A native algorithm library spanning Proximal Policy Optimization (PPO), Clipped Importance Sampling Policy Optimization (CISPO), and importance-sampling (IS) losses, paired with multiple group-based advantage estimators (GRPO, GRPO
pass@k, RLOO, and more). These cover the choices most relevant to multi-turn agentic RL. - Sequence-extension training to keep wall-clock down on long multi-turn trajectories.
- Trajectory and reward observability in MLflow managed by Amazon SageMaker AI, so you can read what your agent did turn by turn, and across training steps.
- Evaluation jobs report reward,
pass@k, trajectory metrics, and more before you deploy to a SageMaker AI endpoint or Amazon Bedrock.
The service provides the training loop, hardware, and orchestration. The choices that decide whether you get a reliable agent are yours. You build the environment the agent trains against, measure success outside the reward, design the reward itself, and decide how to iterate when the curve stalls.
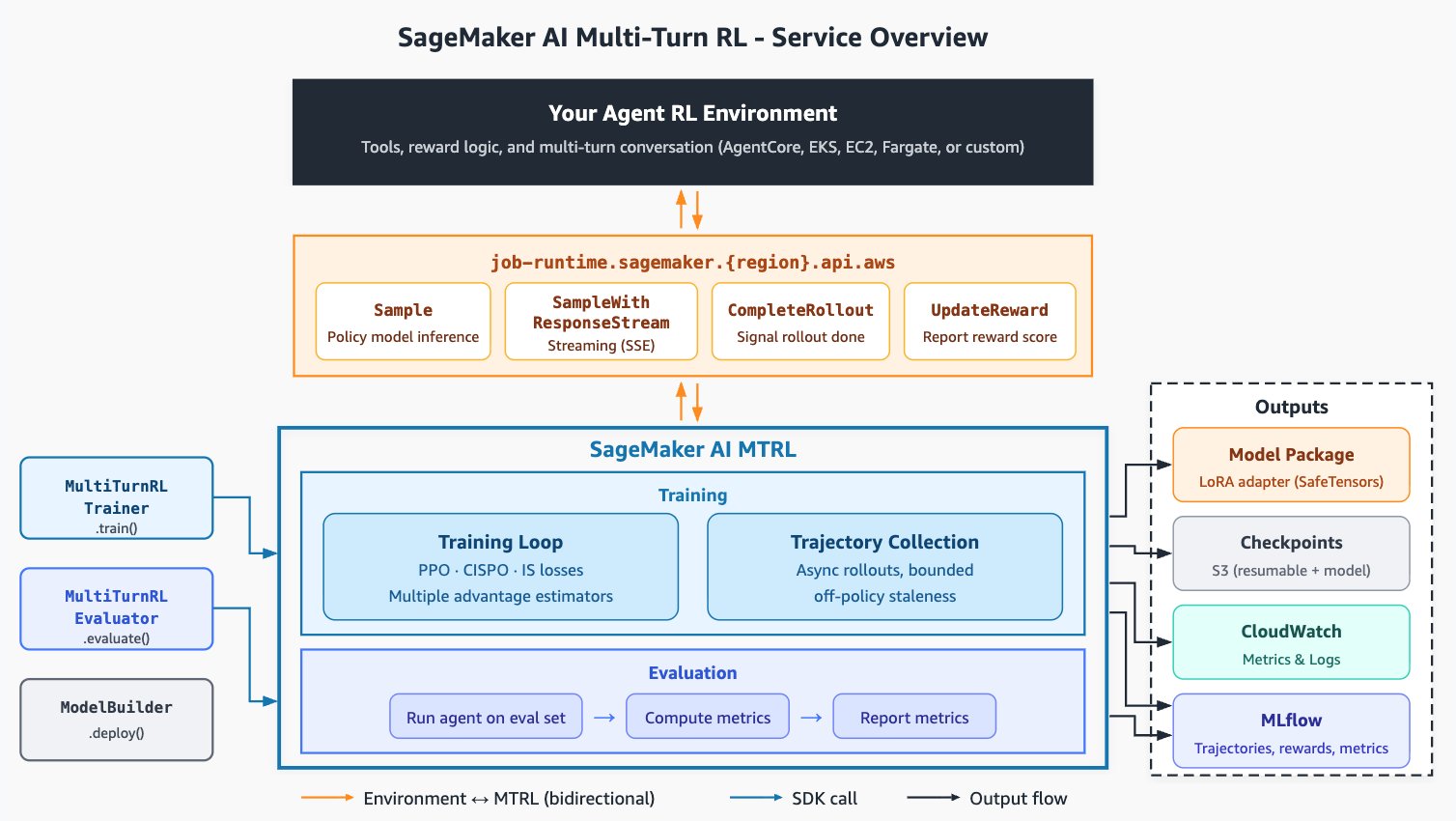
Figure 1: Overview of the SageMaker AI multi-turn RL service
Build a training environment that is cheap, reproducible, and representative
Single-turn RL needs a prompt and a reward function. Multi-turn RL adds an environment for the agent to act in across turns: the tools it calls and the systems behind them. That environment is part of your training setup, and the way you build it shapes both what the model can learn and whether you can trust your metrics.
When training an agent, build a sandboxed or simulated environment that resembles production but stays isolated from live traffic. Tool calls and responses keep the same schemas and business logic. They are driven by recorded responses or isolated state instead of live calls.
Simulated environments are the recommended starting point because a typical run produces many thousands of rollouts, each making several tool calls. As an example, a batch size of 128 with group size 8 is 1,024 rollouts per step. Pointing that traffic at live systems can lead to customer impact. Without a simulated environment, exploration can produce real side effects. For example, an agent learning by trial and error will issue refunds, delete records, or trigger workflows that you didn’t intend. Additionally, live data shifts under you, so the same trajectory scores differently across runs. You must know the correct outcome to compute a reward, which means a fixed, labeled set of tasks (or a trustworthy judge model) regardless of where the tool calls go.
How you build the simulated environment depends on what your tools do. Three patterns cover most use-cases you will encounter:
- Read-only tools: Replay recorded responses keyed by their inputs. These tools help the agent retrieve information relevant to a task. For example, in SOP-Bench the customer service task provides ten mocked tools (
validateAccount,getAuthenticationDetails,createSessionAndOpenTicket, and so on), each returning a deterministic response from a fixture, such as a specific row from a CSV file based on the tool call arguments. - Stateful tools: Seeded sandboxes that hold state for the length of an episode. When the agent writes something and reads it back, the environment needs memory. The pattern: allocate per-episode resources at the start of the rollout, and register everything the agent creates. Tear it all down in a
try/finallyblock when the episode ends, whether by reaching a terminal action, hittingmax_turns, or crashing. No state leaks into the next rollout. - Verifiable outcomes: Genuine execution in an isolated simulation environment. When the agent’s output is code, SQL, or math, you can run it in an isolated environment. Use a Docker
execfor code, an in-memory SQLite per rollout for SQL, a pure Python eval for math. Real execution, deterministic per-instance, same input plus same sandbox state equals same result. For example, AgentCore Code Interpreter provides managed isolated environments for code execution.
Whichever pattern fits, hold two properties fixed:
- Reproducibility: the same tool called with the same arguments returns the same result, so the reward for an identical trajectory is stable and your evaluation is comparable across runs.
- Representativeness: build the environment from your real schemas and data distributions so the behavior the model learns transfers to production.
Before you start training, confirm your environment is configured correctly:
Set up an external evaluation before you train
After your environment is in place and verified, build a way to measure success before you write a reward function. That measure should capture your end goal directly. RL optimizes the reward signal literally, so if the reward is the only number you watch, you cannot separate progress on the task from progress on satisfying the reward criteria. You need an external evaluation you can trust to guide your decisions while you iterate on rewards, environment seeding, and hyperparameters.
Pattern
Stand up a held-out evaluation that scores the outcome you care about at deployment, computed independently of the reward. In practice this is a small piece of code that takes a model, runs it through the rollout server on a fixed test split, and returns a single task-success rate. It can be minimal, as long as it is honest.
For SOP-Bench, the evaluation is exact-match on the final JSON object inside <final_output>: every field in the agent’s output has to match the ground-truth field, or the rollout scores zero. The reward function can compute partial credit and weighted components. The evaluation doesn’t.
Before any training, establish a baseline. Run the base model and a reference model (a frontier model hosted on Amazon Bedrock is a good fit) through the same evaluation. This tells you two things: how far the base model has to go, and what good looks like on this task.
Anti-pattern
Treating the training reward, or a metric derived from it, as your measure of success. This might seem intuitive, but to capture reward hacking, you need external evaluation. Multi-turn agents need special consideration: a reward that pays out for tool calls teaches the agent to call as many tools as it can. A reward that penalizes turn count teaches the agent to commit to an answer before it has the information it needs. Either way, the training reward rises but the agent’s real success at its task falls.
Before you start training, confirm your evaluation is trustworthy:
Design a good multi-turn RL reward function
Reward design is one of the more challenging open problems in RL. The same flexibility that lets the agent solve a real task lets it find ways to satisfy the reward without doing the task. Every component you add, every reward weight you tune, every formatting bonus you layer in is another surface where the agent can climb without solving the task. The model optimizes what you wrote down, not what you meant. By default use the same scoring rule for training and evaluation, and only deviate when you have a concrete reason.
Take SOP-Bench. The benchmark expects the answer as a JSON object inside <final_output> tags:
The benchmark scores 1 if every field matches and 0 otherwise. Training and evaluation usually share this scoring rule and differ only in what you observe around it. The trainer consumes one reward (scalar or list of scalars) per rollout. Evaluation runs at lower frequency on a fixed split, so you can monitor more metrics: per-field accuracy, completion rate (did the agent emit <final_output> at all), tool-call distribution, turn budget exhaustion, format compliance.
There are two real reasons to deviate from the default benchmark scoring rule, and both call for a denser reward.
The first is algorithmic. RL computes the learning signal from variance across a group of group_size rollouts per prompt, using a group-based advantage method (advantage_method). The service default group_based is GRPO. Many other methods like rloo and grpo_passk are also available. See the documentation for a full list. A binary score can collapse that variance: when every rollout in a group scores the same, the relative signal is zero and the group contributes no gradient. When rollout/reward/valid_mean (the mean over non-zero-advantage groups) drifts below rollout/reward/mean and the model stalls, that gap is the symptom.
The second is convergence speed. Even when group variance is healthy, a dense reward gives the model gradient toward partial progress on every rollout, not only the ones that fully succeed. A rollout that gets five of six fields right teaches the model what closer looks like. A binary score teaches it nothing about that.
A dense reward for the SOP-Bench task scores each field independently and returns a reward scalar or list of scalars (per-turn rewards) plus a metrics dictionary.
Your agent reports the reward through update_reward, and the metrics dictionary (completion, field_acc) appears in MLflow. To credit individual turns instead of the whole trajectory, update_reward also accepts a per-turn list, paired with the group_based_per_turn advantage method, so your reward function can also return one reward value per turn.
- Verify the reward on real outputs before you train on it. A reward parser more forgiving than your evaluation is its own kind of reward hack. In one of our SOP-Bench runs the reward accepted a looser output format than the benchmark scored: a bare
<final_response>wrapper earned credit even though the benchmark only reads<final_output>. Training did exactly what we asked: the model learned to drop the tag the benchmark needed, the reward climbed, but the external evaluation fell. - Make sure the base model has a foothold first. RL improves what the base model can already do some fraction of the time. It doesn’t invent capability from nothing. If the base model produces zero successful trajectories on your task, the reward signal has nothing to amplify and training stalls.
SageMaker AI MTRL can run such a baseline as a managed evaluation job. MultiTurnRLEvaluator replays your agent over a held-out prompt set and reports eval/reward and pass@k. If you have already trained a model, a single call with evaluate_base_model=True scores the base and fine-tuned model side by side. Because pass@k thresholds the reward at success_threshold, setting success_threshold=1 gives you a strict success rate: the fraction of rollouts that scored a perfect reward alongside the mean.
In the specified s3_output_path, you will find the reported metrics of the evaluation which you can also review in MLflow, along with evaluation trajectories. For reward-based evaluation of fine-tuned and base models, see the documentation on Model evaluation.
Keep one distinction in mind: the evaluation job scores rollouts with your agent’s own reward function, so it measures held-out generalization, not independence from the reward. A lenient reward parser would look healthy here, because the metric is the reward itself. The independent check that catches reward-parser bugs stays separate: score the same rollouts with a stricter, independent parser (for SOP-Bench, the benchmark’s exact-match scorer) and compare. You can even run that strict scorer as its own evaluation job by pointing MultiTurnRLEvaluator at an agent whose reward is the independent metric.
For a deeper treatment of reward design, sparse vs. dense rewards, judge models, multi-objective shaping, and the trade-offs between them, see the SageMaker AI reward design best practices.
Before you trust your reward, confirm:
Manage what changes when the agent runs for multiple turns
A multi-turn agent has to manage concerns single-turn doesn’t see. These are worth designing for explicitly before you start training.
Context grows every turn, and turn budgets are part of the reward design. Each tool call extends the conversation: the call, its arguments, the result, and the reasoning the model produces between them. Long trajectories accumulate context fast, and MTRL uses sequence-extension training to keep wall-clock manageable as they grow. A task that needs eight calls in sequence might run out of room before it finishes. Two budgets bound this: max_turns, which your agent loop controls, and the per-turn token budget, which the service sets through sampling_max_tokens (rollout) and val_sampling_params.sampling_max_tokens (evaluation). Pick both to match what your task needs and what you can afford to serve at deployment.
For SOP-Bench, eight turns and a 2,048-token per-turn budget cover the canonical procedure with margin to spare (sampling_max_tokens allows up to 8,192). A rule of thumb: if a human walkthrough of the task takes N turns, set max_turns = ceil(N * 1.5) in your agent loop. The right turn budget is the smallest one that lets the agent finish with a small safety margin. Watch rollout/tokens/response_max for responses clustering at the cap. If more than 5 percent of rollouts hit it, raise sampling_max_tokens. That signal is silent loss otherwise. The model learns from a truncated trajectory but does not see the reward it would have earned by finishing.
Separate completion from correctness
A trajectory that finishes with the wrong answer and one that never finishes are different failures, and conflating them hides where the model is breaking. The rollout and val metric families in MLflow give you both signals separately:
| Metric | What it tells you | |
| 1 | rollout/reward/mean |
Average trajectory reward, your training-side signal |
| 2 | rollout/reward/zero_frac |
Fraction of trajectories that scored exactly 0 |
| 3 | rollout/turns/mean |
Average turns per trajectory |
| 4 | analysis/zero_adv_groups |
Groups where every rollout scored the same, wasting rollouts |
| 5 | val/reward/mean |
Mean validation reward your held-out data signal |
| 6 | val/reward/pass_k_1, pass_k_8 |
pass@1 and pass@k on the held-out set |
A high val/reward/pass_k_1 on a low completion rate (rollouts hitting max_turns before emitting a <final_output>) means the model gets the easy paths right and stalls on the hard ones, suggesting turn-budget tuning. A high completion rate on a low val/reward/pass_k_1 means it answers fluently but wrong, suggesting reward redesign. The two failure modes call for different fixes, so it is worth telling them apart.
Before you commit a turn budget, confirm:
Monitor training metrics
After you’ve set up and verified your evaluation, environment, and reward, it’s time to start training. SageMaker AI MTRL provides the high-level MultiTurnRLTrainer and MultiTurnRLEvaluator constructs to train and score your agent:
While training, watch rollout/reward/mean next to the completion rate and open a few trajectories in MLflow (under the Traces tab), so a reward that rises on flat completion doesn’t slip past. The signal that matters at evaluation is disagreement: when rollout/reward/mean climbs but val/reward/mean stays flat, the reward is being hacked. Open those trajectories and compare what the reward credited against what the evaluation scored. That comparison drives your reward design iteration: tighten the reward parser, reshape a component, or curate the data, then run again. Each iteration is faster than the last because the environment and evaluation stay fixed. Only the reward and the data change, and MTRL’s per-model starter recipes give you a tuned point to start from.
For example, in one of our earliest attempts we were trying to train an agent on all SOP-Bench tasks at the same time, which led to tasks competing and reward fluctuating:
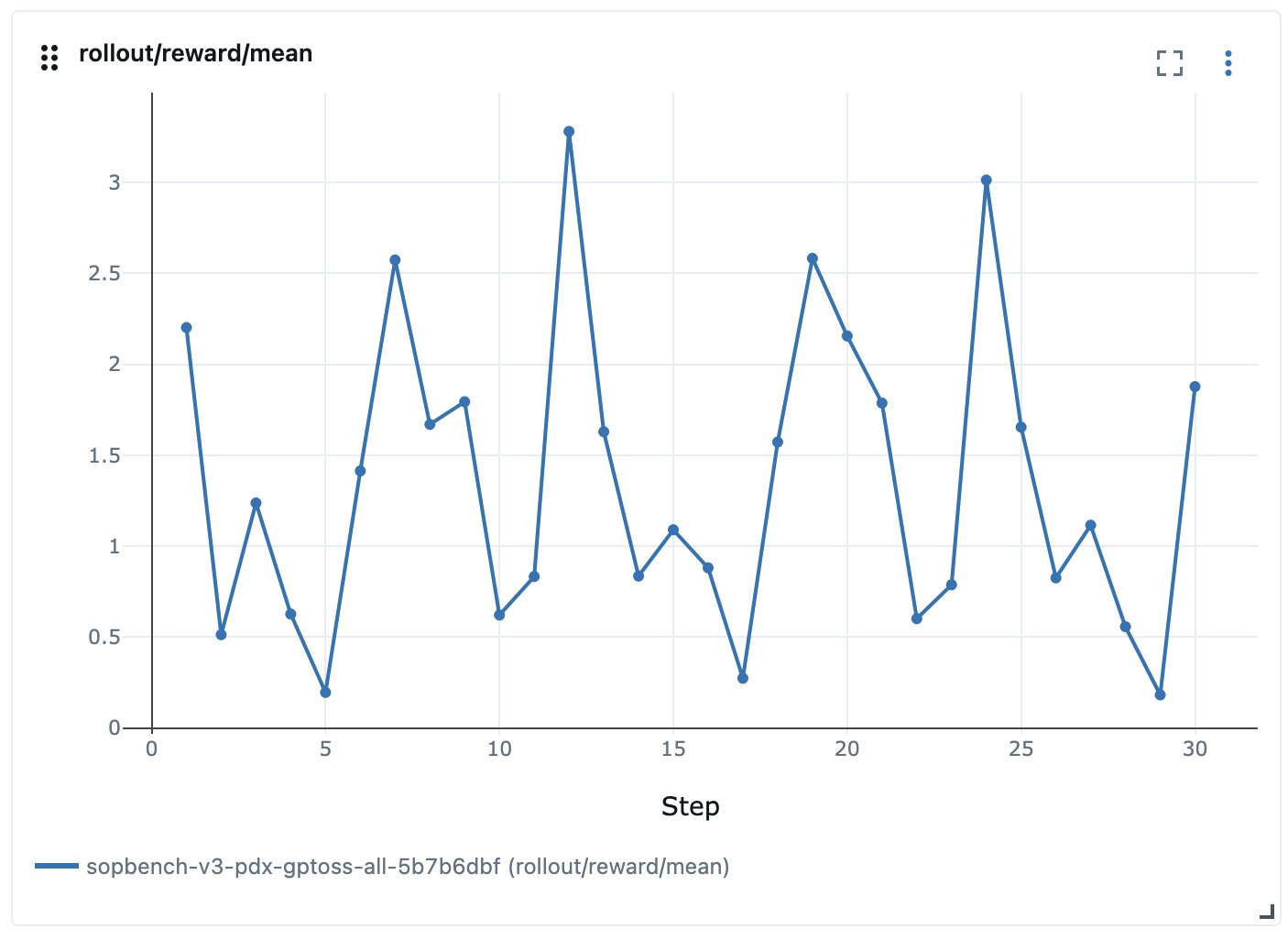
Figure 2: Reward fluctuating when trying to train all SOP-Bench tasks together
After limiting our data to focus on a single task (aircraft_inspection), we noticed validation reward going down while rollout reward had saturated. In our reward formulation the max reward was 5.0, but reward had stalled around 3.7:
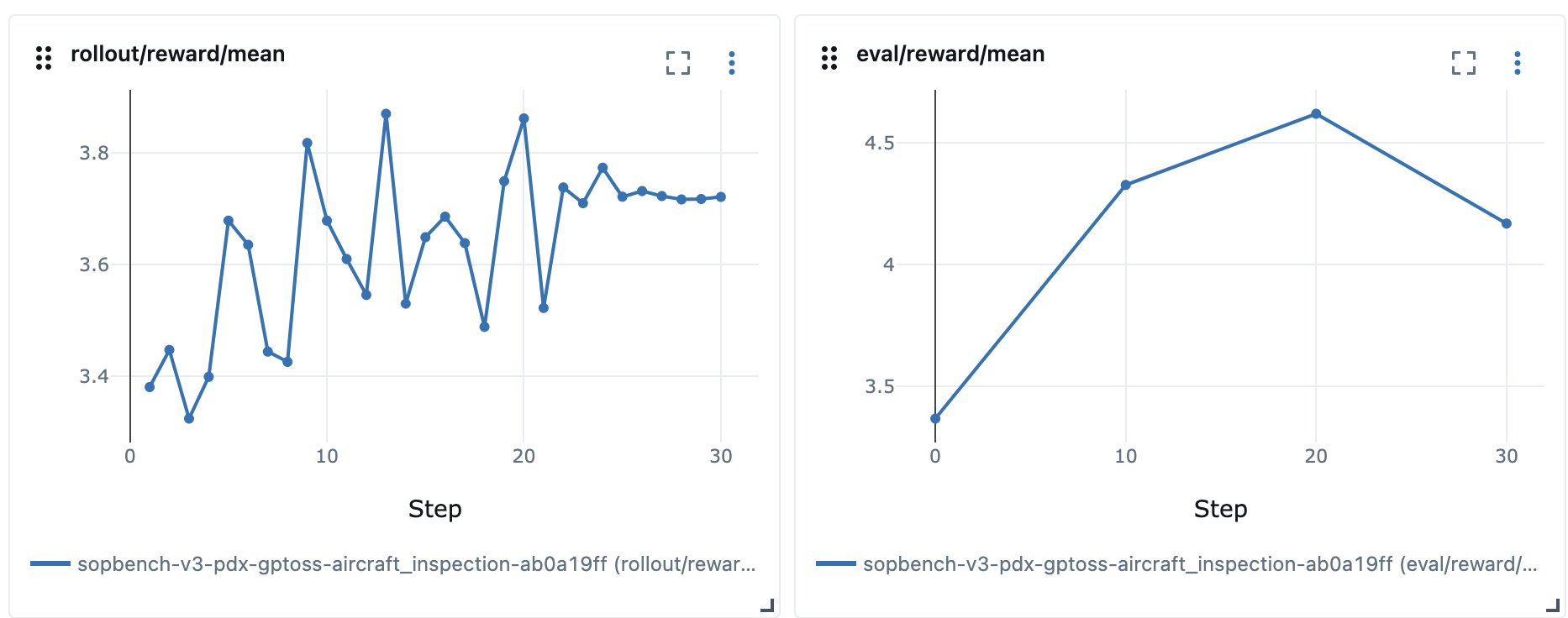
Figure 3: Reward stalling and validation reward dropping
The model wasn’t earning full reward on aircraft_inspection, and the Task Success Rate on the external benchmark went down for the fine-tuned model compared to the base model. We needed to review rollout trajectories to find out why. The SOP’s one-shot example didn’t match the task’s ground-truth data in two ways. It omitted the cross_check_response field that the data required, so the model couldn’t produce a complete answer, and it wrapped the output in a different tag than the evaluation expected. We aligned the example with the data and dropped the unanswerable field, which let the reward and the evaluation measure the same thing.
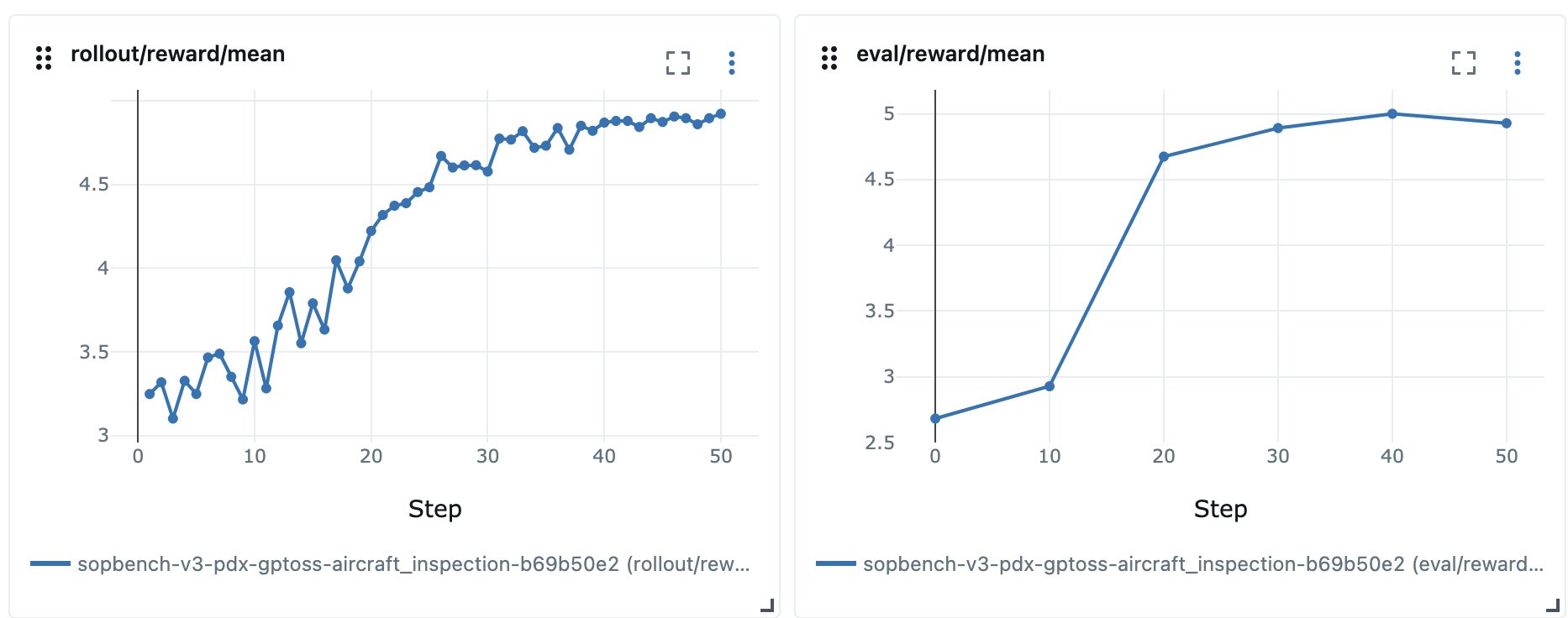
Figure 4: Healthy reward signals for the aircraft_inspection task of SOP-Bench
When measuring the Task Success Rate (TSR) of a fine-tuned GPT-OSS 20B model against the external benchmark, we saw TSR increase by 13 percent and per-field accuracy grow by approximately 16 percent on the aircraft_inspection task, confirming that our reward function aligns with our external evaluation.
Putting it together: An iteration loop
The pieces described earlier add up to a single training loop, run in the order they were introduced. You build the environment and the evaluation first, because they are the fixed scaffolding every later step depends on. You then design the reward against that evaluation, and only after that do you train and read the metrics. Keeping the early pieces fixed is what makes each pass fast, so most of your effort goes into the reward and the data. A version that has worked well for us:
- Collect representative task data and split into train, validation, and held-out test sets.
- Build the training environment from production schemas: hermetic, seeded, reproducible.
- Stand up the external evaluation against the test set, computed independently of the reward.
- Establish a baseline by running the base model and a frontier reference model through the evaluation. If the base model scores zero, stop and simplify before continuing.
- Design the reward, then validate it on real model outputs from the baseline before any training has happened.
- Train, monitoring rollout/reward, completion rate, and a sample of trajectories to know what your model is producing during training.
- Evaluate the trained model with the external evaluation. Read trajectories, especially the ones where the reward and the evaluation disagree.
- Adjust the reward, the environment, or the data, and run again.
When the curve stalls or collapses, walk these in order before tuning anything else:
| Symptom | First thing to change | Diagnostic to confirm | |
| 1 | Reward flat from step 0 | Verify model output formats are aligned with reward | Perform standalone evaluations on different rewards to align format reward with model’s output structure |
| 2 | Train reward flat, all groups score the same | Drop group_size from 8 to 4 and increase batch_size |
Watch analysis/zero_adv_groups, should drop |
| 3 | Train reward rising but val/reward/mean flat |
Reward is being hacked. Re-read trajectories, tighten the reward parser | Re-run the offline reward review against new baseline rollouts |
| 4 | Reward collapses (drops to ~0.0) after step 40–80 | Set async_config.max_steps_off_policy = 0. If on CISPO, switch to PPO with (0.8, 1.2) |
Reward should stabilize, even if lower |
| 5 | Reward stalls with limited improvement, all knobs healthy | Double LoRA capacity (lora_rank=64, lora_alpha=128) |
Higher ceiling within 50 steps if there’s room to grow |
Make one change at a time, observing metrics for 25–50 training steps (gradient updates) per decision. In our runs, most failures became identifiable within roughly 30 steps when these parameters are adjusted deliberately.
Conclusion
Your reward quality and your evaluation decide whether training produces a useful agent, much more than the algorithm or the hyperparameters do. The reward is the only signal the model optimizes, and an evaluation kept separate from it is what tells you whether the agent is learning the task or learning the reward. A carefully designed reward and an evaluation that matches the end task can produce a useful agent; without them, even a strong algorithm yields a model that looks good in training and fails in production.
SageMaker AI multi-turn RL takes care of most of the operational work and complexity of running a distributed agentic RL training, abstracting away the hardware, orchestration, and training engine. With SageMaker AI multi-turn RL, you focus on creating an accurate environment, where Strands Agents and AgentCore can help you transition your production environment to an agentic setup, and focus on the reward design, evaluation, and parameter tuning.
To get started with agentic RL, you can walk through the example notebook for MTRL setup. See the SageMaker AI multi-turn RL documentation for service-level guidance and the reward design best practices for a deeper treatment of the reward topic, or this AWS blog post on GRPO with verifiable rewards. Finally, the SOP-Bench paper and dataset are the source of the running example used here.
About the authors