In this post, we explore how natural language database analytics can revolutionize the way organizations interact with their structured data through the power of large language model (LLM) agents. Natural language interfaces to databases have long been a goal in data management. Agents enhance database analytics by breaking down complex queries into explicit, verifiable reasoning steps and enabling self-correction through validation loops that can catch errors, analyze failures, and refine queries until they accurately match user intent and schema requirements. We demonstrate how this modern approach enables intuitive, conversation-like interactions with complex database systems while maintaining precision and reliability.
To achieve optimal performance with minimal trade-offs, we use the Amazon Nova family of foundation models (FMs): Amazon Nova Pro, Amazon Nova Lite, and Amazon Nova Micro. These FMs encode vast amounts of world knowledge, facilitating nuanced reasoning and contextual understanding essential for complex data analysis. Our solution uses the ReAct (reasoning and acting) pattern, implemented through LangGraph’s flexible architecture. This approach combines the strengths of Amazon Nova LLMs for natural language understanding with explicit reasoning steps and actions.
Challenges of natural language-based database analytics
Many customers undergoing generative AI transformation share a common realization: their vast data stores hold untapped potential for automated analysis and natural language querying. This insight leads them to explore SQL-based solutions, where queries can range from simple SELECT and WHERE clauses to complex, multipage statements involving sophisticated aggregations and functions.
At its core, successful analysis depends on identifying and retrieving the correct dataset. This foundational step enables all downstream activities, including visualization, further analysis, and exploration. Translating a user’s intent—whether stated or implicit—into a performant, precise, and valid SQL query is a significant challenge.
Our solution excels in generating context and metadata-aware queries capable of retrieving precise datasets and performing intricate analyses. To fully harness the capabilities of Agents and Amazon Nova FMs, a user-friendly interface is crucial. We’ve developed an intuitive interface where users are guided through their analysis journey with human-in-the-loop (HITL) capabilities, allowing for input, approvals, and modifications at critical decision points.
Solution overview
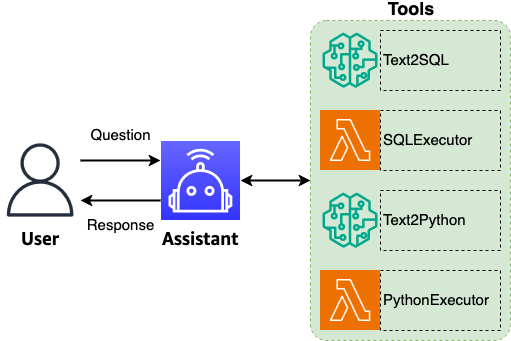
The solution architecture consists of three core components: UI, generative AI, and data. The agent in this solution serves as the central coordinator, combining critical capabilities such as question understanding, decision-making, workflow orchestration, intelligent routing, and generating comprehensive natural language responses. It enhances questions by improving text quality, standardizing terminology, and maintaining conversational context, helping users extend their analysis through a series of related queries while preserving precise analytical intent. The agent’s intelligent routing capabilities mean that correct tools are invoked for each user questions, enabling cohesive end-to-end query processing. Furthermore, it processes tabular and visual data and uses the complete context to generate comprehensive summaries that explain findings, highlight key insights, and suggest relevant follow-up questions. As an added benefit, the agent can suggest relevant follow-up questions and related topics, helping users explore their data more deeply and discover unexpected insights. The following tools are connected to the agent:
- Text2SQL – When the orchestrator determines data retrieval is needed, it uses the Text2SQL tool, which uses a comprehensive knowledge base that includes metadata, table schemas, example queries with their results, and detailed data dictionaries. Using this rich context, the tool transforms natural language questions into precise SQL queries.
- SQLExecutor – This tool directly connects to the structured data store and executes the SQL queries generated by the agent using the Text2SQL tool. The tool executes the generated SQL against a structured database endpoint such as Amazon Athena, Amazon Redshift, or Snowflake.
- Text2Python – When a visual representation of data is needed for the analysis, either by user request or orchestrator decision, the Text2Python tool transforms analytical results into compelling visualizations. This agent processes both the user’s query and the data table retrieved by the Text2SQL tool to generate appropriate Python scripts. Using industry-standard visualization libraries, these scripts execute locally to create diagrams, graphs, or charts that best represent the data. Like its SQL counterpart, this agent includes self-remediation capabilities. When execution errors occur, it uses the error feedback and context to regenerate the Python script, providing reliable visualization delivery.
- PythonExecutor – The PythonExecutor takes the generated Python scripts and executes them locally. This allows for the creation of high-quality data visualizations using industry-standard libraries.
The agent then evaluates whether the returned dataset fully answers the user’s question. If the results are insufficient, it automatically regenerates and executes a more refined query to retrieve optimal data. A key feature is the agent’s self-remediation capability. When execution errors occur, the agent uses these errors and the full context to regenerate a corrected SQL query. This self-healing approach provides robust and reliable query processing, even in complex scenarios. The agent processes the inputs—the rewritten question, analysis results, and context—to create a natural language summary and responds to the user, including tabular results with reasoning, visualizations with explanations, and a summary with key insights.
The workflow is illustrated in the following diagram.
The following shows an example of the conversation flow between the user and the agent:
- User_A: what are the number of claims by staff name?
- Chatbot: The following are the top 10….
- User_A: Visualize it
- Chatbot: Visualize as a bar chart? [Rewritten Question]
- User_A: Confirmed
- Chatbot: <IMAGE.PNG>
The agent maintains context through conversations, which means users only need to provide minimal follow-up inputs. It automatically reconstructs abbreviated questions using previous context for confirmation. Additionally, after each question-answer exchange, the agent suggests relevant follow-up exploratory questions for further exploration. The agent enforces consistent terminology, following industry standards, customer guidelines, and brand requirements. It standardizes abbreviations in both inputs and outputs by expanding them to their full forms. For example, “GDPR” is always expanded to General Data Protection Regulation in user input and agent responses. The agent improves text quality by maintaining clarity, correcting grammar, and refining sentence structure. All content is processed to provide professional, readable output.The solution uses the following AWS services and resources:
- Amazon Athena – Athena is used as the structured database for storing and querying the data
- Amazon Bedrock – The core of this solution is built on Amazon Bedrock, which enables the integration of generative AI agents and Amazon Nova
- AWS Glue – We use AWS Glue to prepare and load the dataset into Athena
- Amazon Nova – The state-of-the-art FM from Amazon is a key component, providing natural language understanding and generation capabilities
- Amazon SageMaker – We use SageMaker to create a notebook instance for running the code and experiments
Prerequisites
You need the following prerequisites to get started implementing the solution in this post:
- An AWS account
- Familiarity with FMs and Amazon Bedrock
- Model access enabled in Amazon Bedrock for Amazon Nova models: Amazon Nova Pro, Amazon Nova Lite, and Amazon Nova Micro
Set up a SageMaker notebook instance
Follow these steps to create a SageMaker notebook instance:
- On the SageMaker console, choose Notebook instances in the navigation pane.
- Choose Create notebook instance.
- For Notebook instance name, enter a name (for example,
text2sql-nova-nb). - For Notebook Instance type, choose ml.t3.medium.
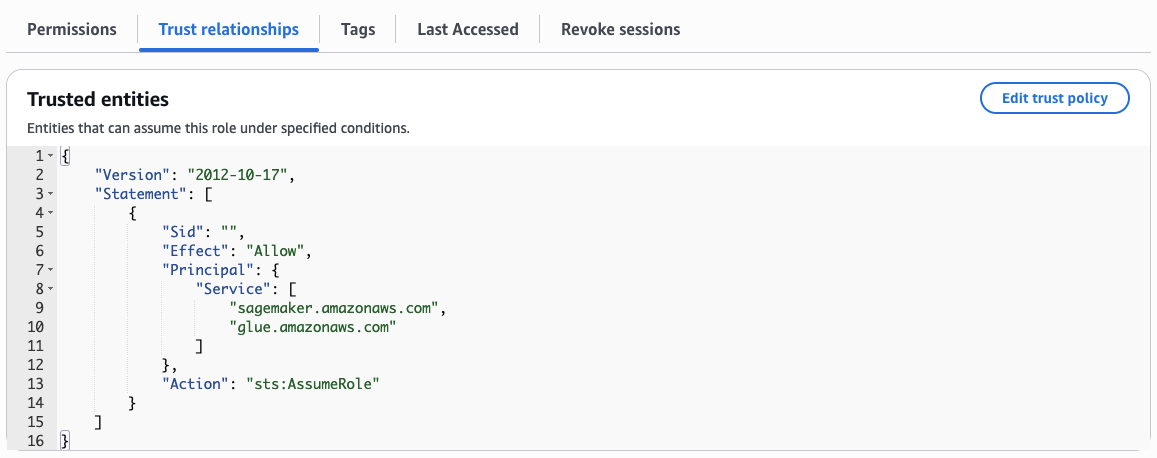
- On the notebook, click on “IAM role ARN”, and add
sagemaker.amazonaws.comandglue.amazonaws.comin the Trust relationships tab.
- After the notebook instance has started, clone the GitHub repository.
Download and prepare the database
Follow these steps to download and prepare the database:
- Download the Spider dataset. For this walkthrough, we use the insurance and claims database.
- Unzip the dataset into the
/datafolder. - Create an AWS hosted Amazon Simple Storage Service (Amazon S3) bucket (for instructions, see Creating a general purpose bucket).
- In the
/srcfolder, usedb_setup.ipynbto load the database into Athena.
Run the Streamlit application
To start the Streamlit application, use the following command:streamlit run app.pyThe following screenshot shows the interface.
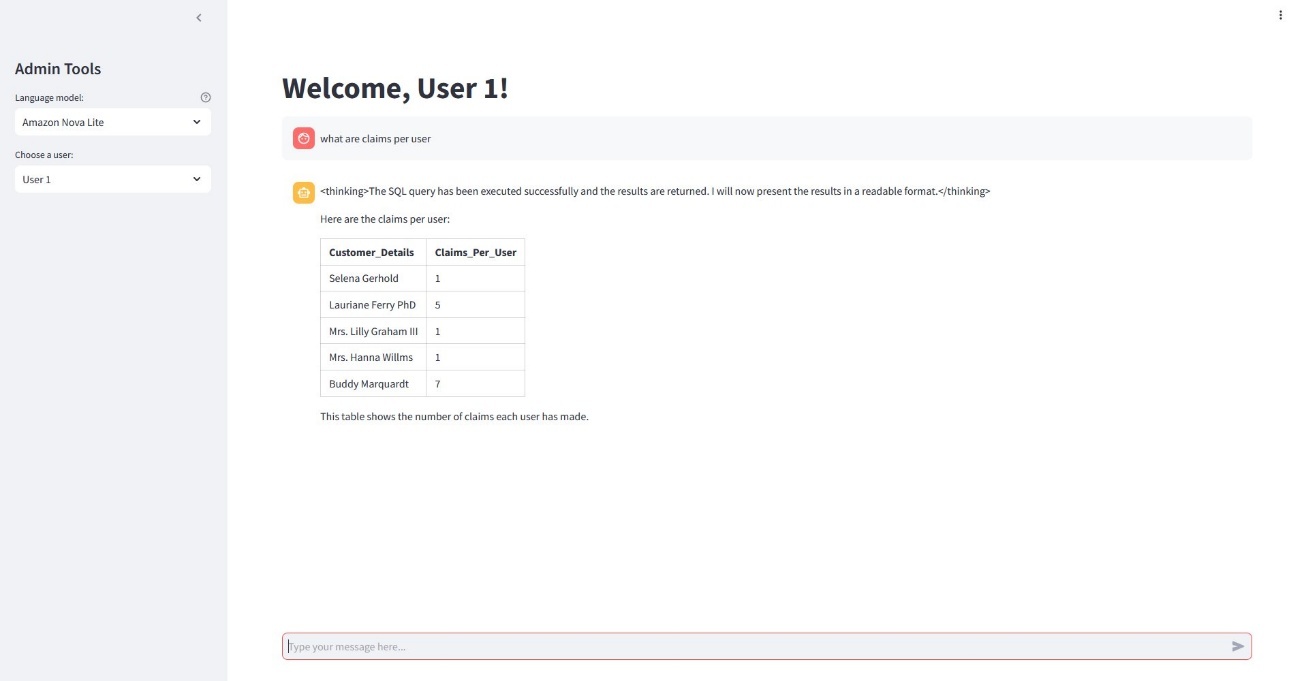
This demo uses Streamlit for illustration purposes only. For production deployments, review Streamlit’s security configuration and deployment architecture to make sure it aligns with your organization’s security requirements and best practices.
Evaluations
We evaluated the performance of Amazon Nova on the Spider text-to-SQL dataset, a widely used benchmark for complex cross-domain semantic parsing and text-to-SQL tasks. The evaluation provided insights into the Amazon Nova capabilities compared to other state-of-the-art approaches. The Spider dataset contains 10,181 questions and 5,693 unique complex SQL queries on 200 databases with multiple tables covering 138 different domains. The evaluation was conducted in a zero-shot setting, where the models weren’t fine-tuned on examples from the dataset, to assess their general text-to-SQL translation abilities. We used the following evaluation metrics:
- Execution accuracy – The execution accuracy metric evaluates whether the predicted SQL query produces the same result as the ground truth SQL query when executed against the database. The execution accuracy provides a practical assessment of the model’s performance because it measures the end-to-end capability to translate natural language questions into executable SQL queries. The top-performing models demonstrate strong execution accuracy on the Spider dataset, with the Amazon Nova model showing particularly competitive performance. Compared to other state-of-the-art models, Amazon Nova achieves similar or slightly higher accuracy across the various query complexity levels. For the most challenging queries, Amazon Nova outperforms the other leading models, showcasing its ability to handle complex natural language-to-SQL translations.
- Latency – In addition to accuracy, the speed and responsiveness of the text-to-SQL translation is an important consideration. Here, the Amazon Nova model stands out, demonstrating significantly faster processing times compared to other top-performing models. For a representative set of database queries, Amazon Nova was able to generate the SQL and retrieve the results notably quicker (a latency improvement of about 60%) than the competition. This latency improvement could translate to enhanced user experience and productivity, meaning that business users can use natural language interfaces to interact with databases more seamlessly.
Overall, the evaluation results highlight the strengths of Amazon Nova in both accuracy and efficiency for text-to-SQL translation tasks. Its competitive performance, low latency, and advantages on the most complex queries make it a compelling option for organizations looking to democratize data access and analysis through natural language interfaces.
Clean up
To avoid continuing charges because of resources created as part of this walkthrough, perform the following cleanup steps:
- Disable Amazon Bedrock model access for Amazon Nova Pro.
- Delete project-specific AWS Glue Data Catalog databases and associated tables.
- Remove the Amazon S3 content:
- Delete the SageMaker notebook instance.
Conclusion
The Generative AI Innovation Center (GenAIIC) at AWS has developed this natural language-based database analytics solution that uses the strengths of state-of-the-art Amazon Nova FMs, along with explicit reasoning steps and actions, as implemented through the ReAct pattern in LangGraph’s flexible architecture. This solution is built using Amazon Bedrock, which enables intuitive, conversation-like interactions with complex database systems. You can seamlessly translate your natural language queries into accurate SQL statements and generate insightful data visualizations. The evaluation results demonstrate the solution’s competitive performance, making it a compelling option for organizations looking to democratize data access and analysis. Furthermore, the GenAIIC provides you with access to a team of experts to help identify valuable use cases and implement practical generative AI solutions tailored to your specific needs, enhancing the potential of this technology.
For more information, refer to Amazon Nova Foundation Models and Amazon Bedrock. If you’re interested in the collaboration with GenAIIC, you can find more information at AWS Generative AI Innovation Center.
 Rahul Ghosh is an Applied Scientist at the AWS Generative AI Innovation Center, where he works with AWS customers across different verticals to expedite their use of Generative AI. Rahul holds a PhD in Computer Science from the University of Minnesota.
Rahul Ghosh is an Applied Scientist at the AWS Generative AI Innovation Center, where he works with AWS customers across different verticals to expedite their use of Generative AI. Rahul holds a PhD in Computer Science from the University of Minnesota.
 Gaurav Rele is a Senior Data Scientist at the AWS Generative AI Innovation Center, where he works with AWS customers across different verticals to accelerate their use of generative AI and AWS cloud services to solve their business challenges.
Gaurav Rele is a Senior Data Scientist at the AWS Generative AI Innovation Center, where he works with AWS customers across different verticals to accelerate their use of generative AI and AWS cloud services to solve their business challenges.
 Amaran Asokkumar is a Deep Learning Architect at AWS, specializing in infrastructure, automation, and AI. He leads the design of generative AI-enabled solutions across industry segments. Amaran is passionate about all things AI and helping customers accelerate their generative AI exploration and transformation efforts.
Amaran Asokkumar is a Deep Learning Architect at AWS, specializing in infrastructure, automation, and AI. He leads the design of generative AI-enabled solutions across industry segments. Amaran is passionate about all things AI and helping customers accelerate their generative AI exploration and transformation efforts.
 Long Chen is a Sr. Applied Scientist at the AWS Generative AI Innovation Center. He holds a PhD in Applied Physics from the University of Michigan. With more than a decade of experience for research and development, he works on innovative solutions in various domains using generative AI and other machine learning techniques, facilitating the success of AWS customers. His interest includes generative models, multimodal systems, and graph learning.
Long Chen is a Sr. Applied Scientist at the AWS Generative AI Innovation Center. He holds a PhD in Applied Physics from the University of Michigan. With more than a decade of experience for research and development, he works on innovative solutions in various domains using generative AI and other machine learning techniques, facilitating the success of AWS customers. His interest includes generative models, multimodal systems, and graph learning.
 Jae Oh Woo is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he specializes in developing custom solutions and model customization for a diverse range of use cases. He has a strong passion for interdisciplinary research that connects theoretical foundations with practical applications in the rapidly evolving field of generative AI. Prior to joining Amazon, Jae Oh was a Simons Postdoctoral Fellow at the University of Texas at Austin. He holds a Ph.D. in Applied Mathematics from Yale University.
Jae Oh Woo is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he specializes in developing custom solutions and model customization for a diverse range of use cases. He has a strong passion for interdisciplinary research that connects theoretical foundations with practical applications in the rapidly evolving field of generative AI. Prior to joining Amazon, Jae Oh was a Simons Postdoctoral Fellow at the University of Texas at Austin. He holds a Ph.D. in Applied Mathematics from Yale University.
 Sungmin Hong is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he helps expedite the variety of use cases of AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds PhD in Computer Science from New York University. Outside of work, he prides himself on keeping his indoor plants alive for over 3 years.
Sungmin Hong is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he helps expedite the variety of use cases of AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds PhD in Computer Science from New York University. Outside of work, he prides himself on keeping his indoor plants alive for over 3 years.
 Vidya Sagar Ravipati is a Science Manager at the AWS Generative AI Innovation Center, where he uses his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
Vidya Sagar Ravipati is a Science Manager at the AWS Generative AI Innovation Center, where he uses his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.