Mixture of Experts (MoE) architectures for large language models (LLMs) have recently gained popularity due to their ability to increase model capacity and computational efficiency compared to fully dense models. By utilizing sparse expert subnetworks that process different subsets of tokens, MoE models can effectively increase the number of parameters while requiring less computation per token during training and inference. This enables more cost-effective training of larger models within fixed compute budgets compared to dense architectures.
Despite their computational benefits, training and fine-tuning large MoE models efficiently presents some challenges. MoE models can struggle with load balancing if the tokens aren’t evenly distributed across experts during training, and some experts may become overloaded while others are under-utilized. MoE models have high memory requirements, because all expert parameters need to be loaded into memory even though only a subset is used for each input.
In this post, we highlight new features of the Amazon SageMaker model parallelism library that enable efficient training of MoE models using expert parallelism. Expert parallelism is a type of parallelism that handles splitting experts of an MoE model across separate workers or devices, similar to how tensor parallelism can partition dense model layers. We demonstrate how to use these new features of SMP by pre-training the 47 billion parameter Mixtral 8x7B MoE model using expert parallelism. To learn more, refer to our GitHub repo and Expert parallelism.
Expert parallelism
The Mixtral 8x7B model has a sparse MoE architecture, containing eight expert subnetworks with around 7 billion parameters each. A trainable gate network called a router determines which input tokens are sent to which expert. With this architecture, the experts specialize in processing different aspects of the input data. The complete Mixtral 8x7B model has a total of 47 billion parameters, but only around 12.9 billion (two experts, for this model architecture) are activated for any given input token; this results in improved computational efficiency relative to a dense model of the same total size. To learn more about the MoE architecture in general, refer to Applying Mixture of Experts in LLM Architectures.
SMP adds support for expert parallelism
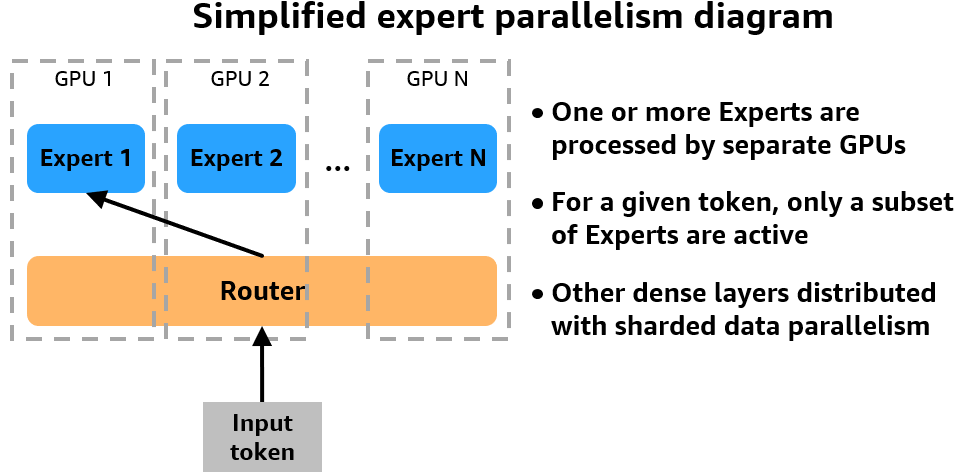
SMP now supports expert parallelism, which is essential to performant MoE model training. With expert parallelism, different expert subnetworks that comprise the MoE layers are placed on separate devices. During training, different data is routed to the different devices, with each device handling the computation for the experts it contains. By distributing experts across workers, expert parallelism addresses the high memory requirements of loading all experts on a single device and enables MoE training on a larger cluster. The following figure offers a simplified look at how expert parallelism works on a multi-GPU cluster.
The SMP library uses NVIDIA Megatron to implement expert parallelism and support training MoE models, and runs on top of PyTorch Fully Sharded Data Parallel (FSDP) APIs. You can keep using your PyTorch FSDP training code as is and activate SMP expert parallelism for training MoE models. SMP offers a simplified workflow where you need to specify the expert_parallel_degree parameter, which will evenly divide experts across the number of GPUs in your cluster. For example, to shard your model while using an instance with 8 GPUs, you can set the expert_parallel_degree to 2, 4, or 8. We recommend that you start with a small number and gradually increase it until the model fits in the GPU memory.
SMP’s expert parallelism is compatible with sharded data parallelism
SMP’s expert parallel implementation is compatible with sharded data parallelism, enabling more memory-efficient and faster training. To understand how this works, consider an MoE model in the following example with eight experts (N=8) training on a simple cluster with one node containing 4 GPUs.
SMP’s expert parallelism splits the MoE experts across GPUs. You control how many experts are instantiated on each device by using the expert_parallel_degree parameter. For example, if you set the degree to 2, SMP will assign half of the eight experts to each data parallel group. The degree value must be a factor of the number of GPUs in your cluster and the number of experts in your model. Data is dynamically routed to and from the GPU or GPUs hosting the selected expert using all-to-all GPU communication.
Next, sharded data parallelism partitions and distributes the experts as well as the non-MoE layers of the model, like attention or routers, across your cluster to reduce the memory footprint of the model. The hybrid_shard_degree parameter controls this. For example, a hybrid_shard_degree of 2 will shard the model states (including experts and non-MoE layers) across half of the GPUs in our cluster. The product of expert_parallel_degree and hybrid_shard_degree should not exceed the world size of the cluster. In the following example, hybrid_shard_degree * expert_parallel_degree = 4 is a valid configuration.
Solution overview
With the background out of the way, let’s dig into the components of our distributed training architecture. The following diagram illustrates the solution architecture.
In this example, we use SageMaker training jobs. With SageMaker training jobs, you can launch and manage clusters of high-performance instances with simple API calls. For example, you can use the SageMaker Estimator to specify the type and quantity of instances to use in your distributed systems with just a few lines of code. Later in this post, we use a cluster of two ml.p4d.24xlarge instances to train our model by specifying these parameters in our Estimator. To learn about SageMaker training jobs, see Train a Model with Amazon SageMaker.
In this post, we use the SMP library to efficiently distribute the workload across the cluster using hybrid sharded data parallelism and expert parallelism. In addition to these implementations, SMP offers many other performance-improving and memory-saving techniques, such as:
Mixed precision training and fp8 support for dense Llama models (which accelerates distributed training and takes advantage of the performance improvements on P5 instances)
Tensor parallelism composable with sharded data parallelism
Delayed parameter initialization
Activation checkpointing (a technique to reduce memory usage by clearing activations of certain layers and recomputing them during the backward pass)
For the latest updates, refer to SageMaker model parallelism library v2.
Along with SMP, this example also uses the SageMaker distributed data parallel library (SMDDP). As you scale your workload and add instances to your cluster, the overhead of communication between instances also increases, which can lead to a drop in overall computational performance and training efficiency. This is where SMDDP helps. SMDDP includes optimized communication collectives such as AllGather that are designed for AWS network infrastructure. Because of this, SMDDP can outperform other more general communications libraries such as NCCL when training on SageMaker.
Together, the SMP and SMDDP libraries can accelerate large distributed training workloads by up to 20%. Additionally, these libraries are compatible with standard PyTorch APIs and capabilities, which makes it convenient to adapt any existing PyTorch FSDP training script to the SageMaker training platform and take advantage of the performance improvements that SMP and SMDDP provide. To learn more, see SageMaker model parallelism library v2 and Run distributed training with the SageMaker distributed data parallelism library.
In the following sections, we showcase how you can accelerate distributed training of the Hugging Face Transformers Mixtral 8*7B model on P4 instances using SMP and SMDDP.
Prerequisites
You need to complete some prerequisites before you can run the Mixtral notebook.
First, make sure you have created a Hugging Face access token so you can download the Hugging Face tokenizer to be used later. After you have the access token, you need to make a few quota increase requests for SageMaker. You need to request a minimum of 2 P4d instances ranging to a maximum of 8 P4d instances (depending on time-to-train and cost-to-train trade-offs for your use case).
On the Service Quotas console, request the following SageMaker quotas:
P4 instances (ml.p4d.24xlarge) for training job usage: 2–8
It may take up to 24 hours for the quota increase to get approved.
Now that you’re ready to begin the process to pre-train the Mixtral model, we start with dataset preparation in the next step.
Prepare the dataset
We begin our tutorial with preparing the dataset. This will cover loading the GLUE/SST2 dataset, tokenizing and chunking the dataset, and configuring the data channels for SageMaker training on Amazon Simple Storage Service (Amazon S3). Complete the following steps:
You first need to load the GLUE/SST2 dataset and split it into training and validation datasets:
Load the Mixtral-8x7B tokenizer from the Hugging Face Transformers library:
Next, you define two utility functions: tokenize_function() and group_texts(). The tokenize_function() runs the tokenizer on the text data. The group_texts() function concatenates all texts from the dataset and generates chunks of a block size that corresponds to the model’s input length (2048) for this example. By chunking the text data into smaller pieces, you make sure the model can process the entire dataset during training, even if some text examples are longer than the input length (2048).
Define the functions with the following code:
Call the preceding utility functions on your dataset to tokenize and generate chunks suitable for the model:
Prepare the training and validation datasets for SageMaker training by saving them as JSON files and constructing the S3 paths where these files will be uploaded:
Finally, set up the data channels for SageMaker training by creating TrainingInput objects from the provided S3 bucket paths for the training and test/validation datasets:
You’re now ready to run pre-training or fine-tuning on the dataset.
Pre-train Mixtral 8x7B with expert parallelism on SMP
To pre-train the Mixtral 8x7B model, complete the following steps:
Initialize the script with torch.sagemaker.init() to activate the SMP library:
Import the MoEConfig class from the torch.sagemaker.transform API. We use the MoEConfig class to enable the model to use the SMP implementation of MoE:
Create a model configuration for Mixtral 8x7B model. This will be passed to AutoModelForCausalLM.from_config(model_config, attn_implementation=”flash_attention_2″) from the Hugging Face Transformers library to initialize the model with random weights. If you want to fine-tune, you can provide the path to the pre-trained weights instead of the model configuration.
In the example Jupyter Notebook, you use a create_model() function that invokes the AutoModelForCausalLM.from_config() function.
Create the SMP MoE configuration class. In the following code, you specify parameters in the training estimator in the subsequent steps. To learn more about the SMP MoEConfig class, see torch.sagemaker.moe.moe_config.MoEConfig.
With the model and MoE configuration ready, you wrap the model with the SMP transform API and pass the MoE configuration. Here, the tsm.transform method adapts the model from Hugging Face format to SMP format. For more information, refer to torch.sagemaker.transform.
Define the training hyperparameters, including the MoE configuration and other settings specific to the model and training setup:
We enable delayed parameter initialization in SMP, which allows initializing large models on a meta device without attaching data. This can resolve limited GPU memory issues when you first load the model. This approach is particularly useful for training LLMs with tens of billions of parameters, where even CPU memory might not be sufficient for initialization.
SMP supports various routing strategies, including sinkhorn, balanced, and aux_loss. Each provides distinct load balancing approaches to achieve equitable token assignment among experts, thereby maintaining balanced workload distribution.
Specify the parameters for expert_parallel_degree and hybrid_shard_degree:
Hybrid sharding is a memory saving technique between `FULL_SHARD` and `NO_SHARD`, with `FULL_SHARD` saving the most memory and `NO_SHARD` not saving any. This technique shards parameters within the hybrid shard degree (HSD) group and replicates parameters across groups. The HSD controls sharding across GPUs and can be set to an integer from 0 to `world_size`.
An HSD of 8 applies `FULL_SHARD` within a node and then replicates parameters across nodes because there are 8 GPUs in the nodes we are using. This results in reduced communication volume because expensive all-gathers and reduce-scatters are only done within a node, which can be more performant for medium-sized models. Generally, you want to use the smallest HSD that doesn’t cause out of memory (OOM) errors. If you’re experiencing OOM, try increasing the hybrid shard degree to reduce memory usage on each node.
With all the necessary configurations in place, you now create the PyTorch estimator function to encapsulate the training setup and launch the training job. We run the pre-training on the 2 ml.p4d.24xlarge instances, where each instance contains 8 A100 Nvidia GPUs:
Finally, launch the pre-training workload:
Clean up
As part of cleanup, you can delete the SageMaker default bucket created to host the GLUE/SST2 dataset.
Conclusion
Training large MoE language models like the 47 billion parameter Mistral 8x7B can be challenging due to high computational and memory requirements. By using expert parallelism and sharded data parallelism from the SageMaker model parallelism library, you can effectively scale these MoE architectures across multiple GPUs and workers.
SMP’s expert parallelism implementation seamlessly integrates with PyTorch and the Hugging Face Transformers library, allowing you to enable MoE training using simple configuration flags without changing your existing model code. Additionally, SMP provides performance optimizations like hybrid sharding, delayed parameter initialization, and activation offloading and recomputation to further improve training efficiency.
For the complete sample to pre-train and fine-tune Mixtral 8x7B, see the GitHub repo.
Special thanks
Special thanks to Rahul Huilgol, Gautam Kumar, and Luis Quintela for their guidance and engineering leadership in developing this new capability.
About the Authors
Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS based in Munich, Germany. Roy helps AWS customers—from small startups to large enterprises—train and deploy large language models efficiently on AWS. Roy is passionate about computational optimization problems and improving the performance of AI workloads.
Kanwaljit Khurmi is a Principal Solutions Architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
Robert Van Dusen is a Senior Product Manager with Amazon SageMaker. He leads frameworks, compilers, and optimization techniques for deep learning training.
Teng Xu is a Software Development Engineer in the Distributed Training group in AWS AI. He enjoys reading.
Suhit Kodgule is a Software Development Engineer with the AWS Artificial Intelligence group working on deep learning frameworks. In his spare time, he enjoys hiking, traveling, and cooking.