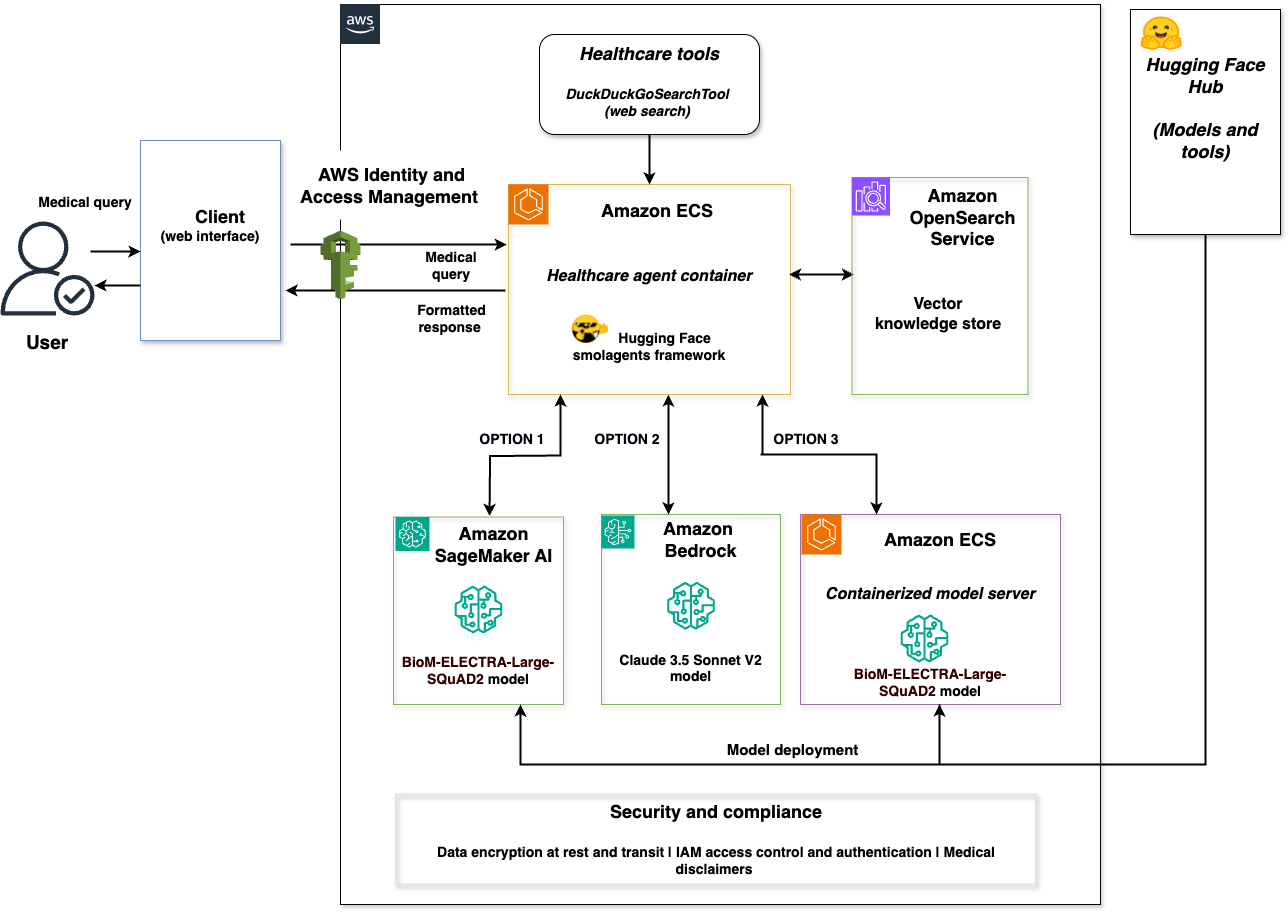
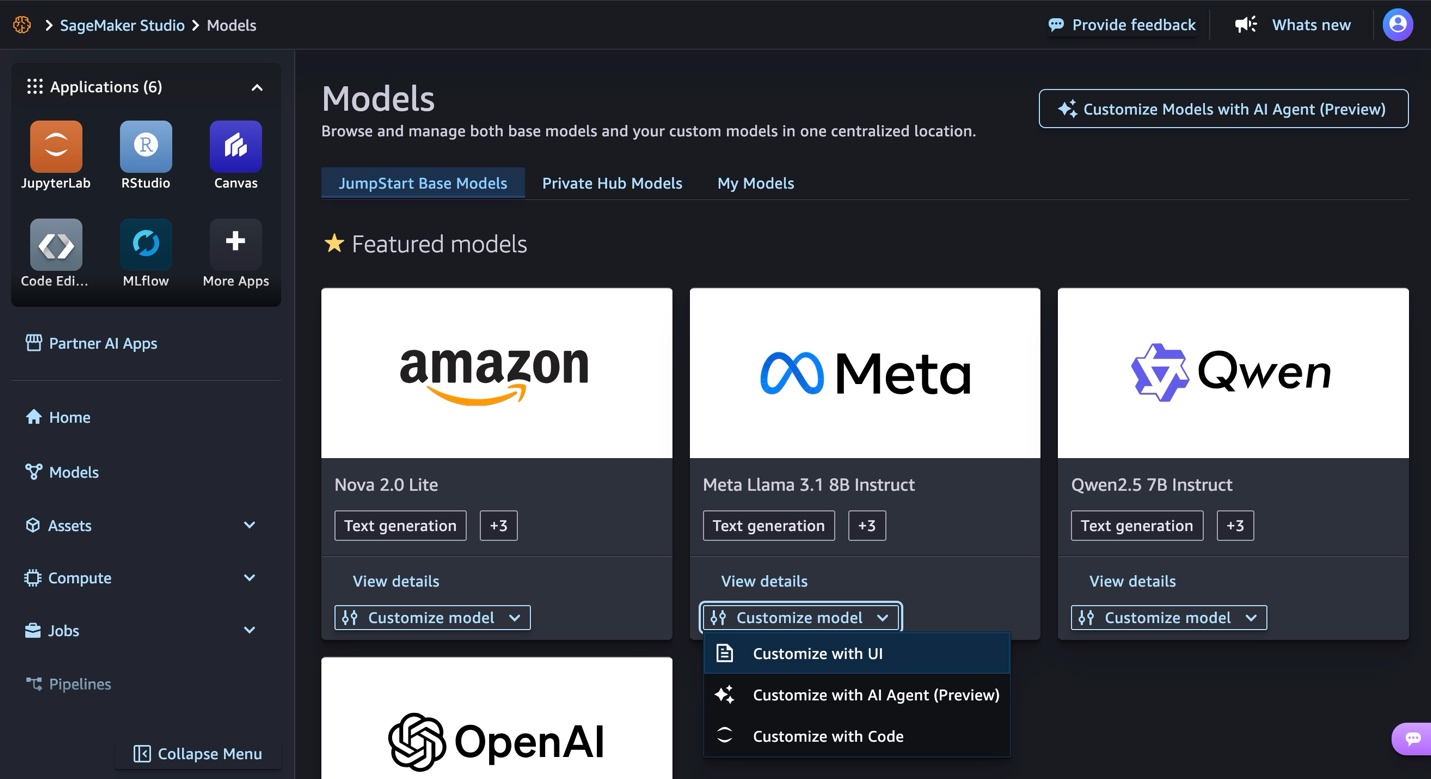
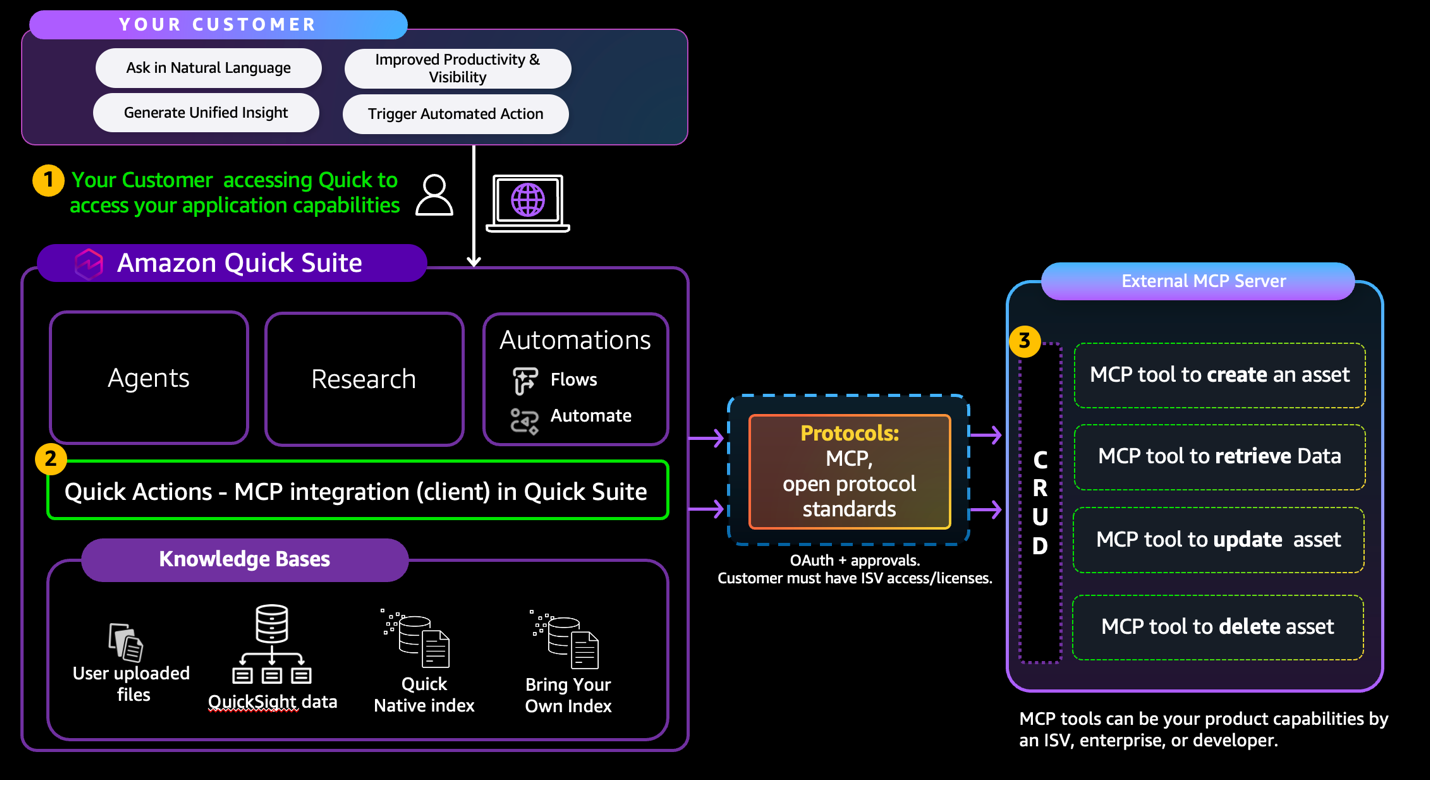
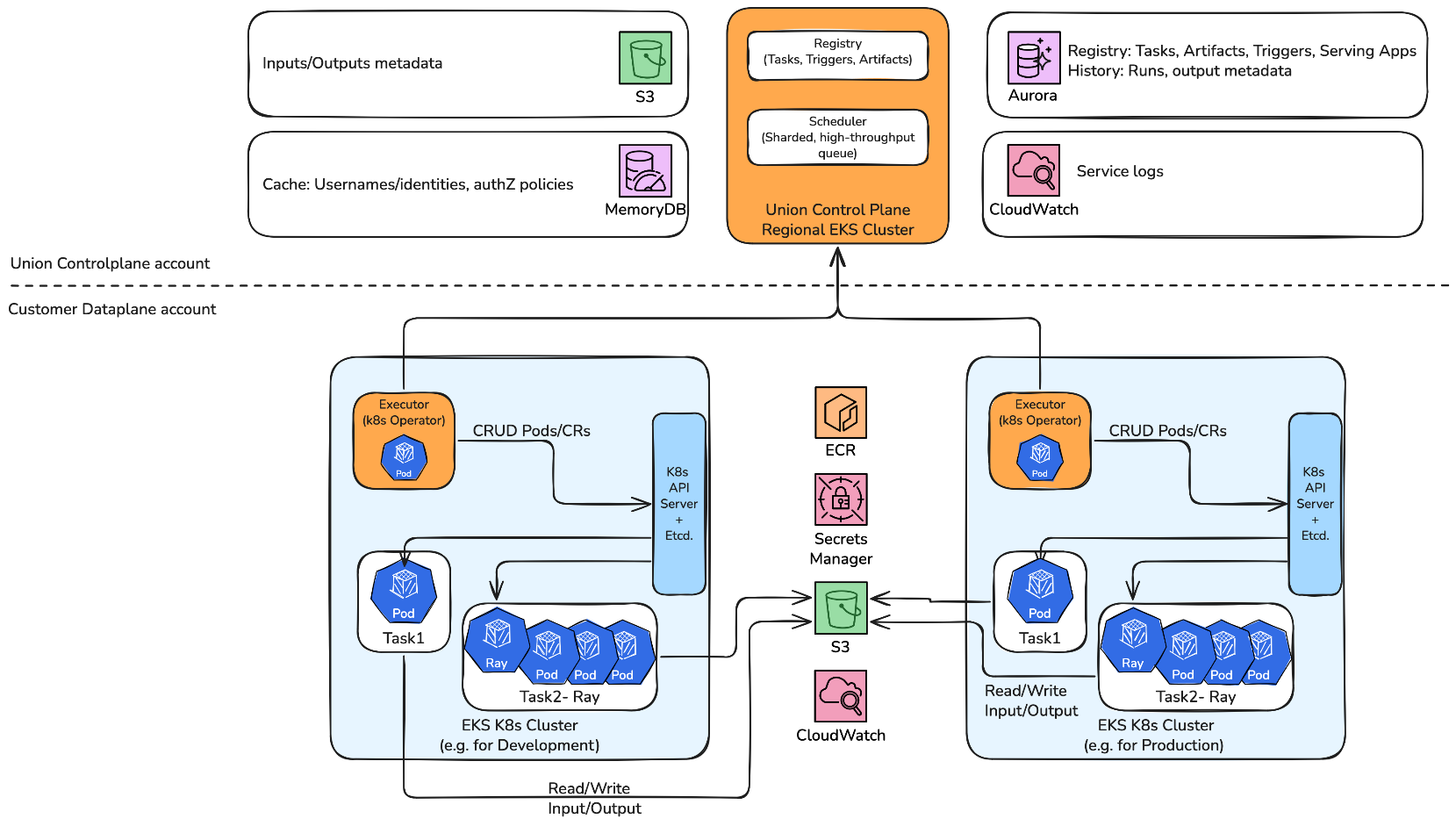
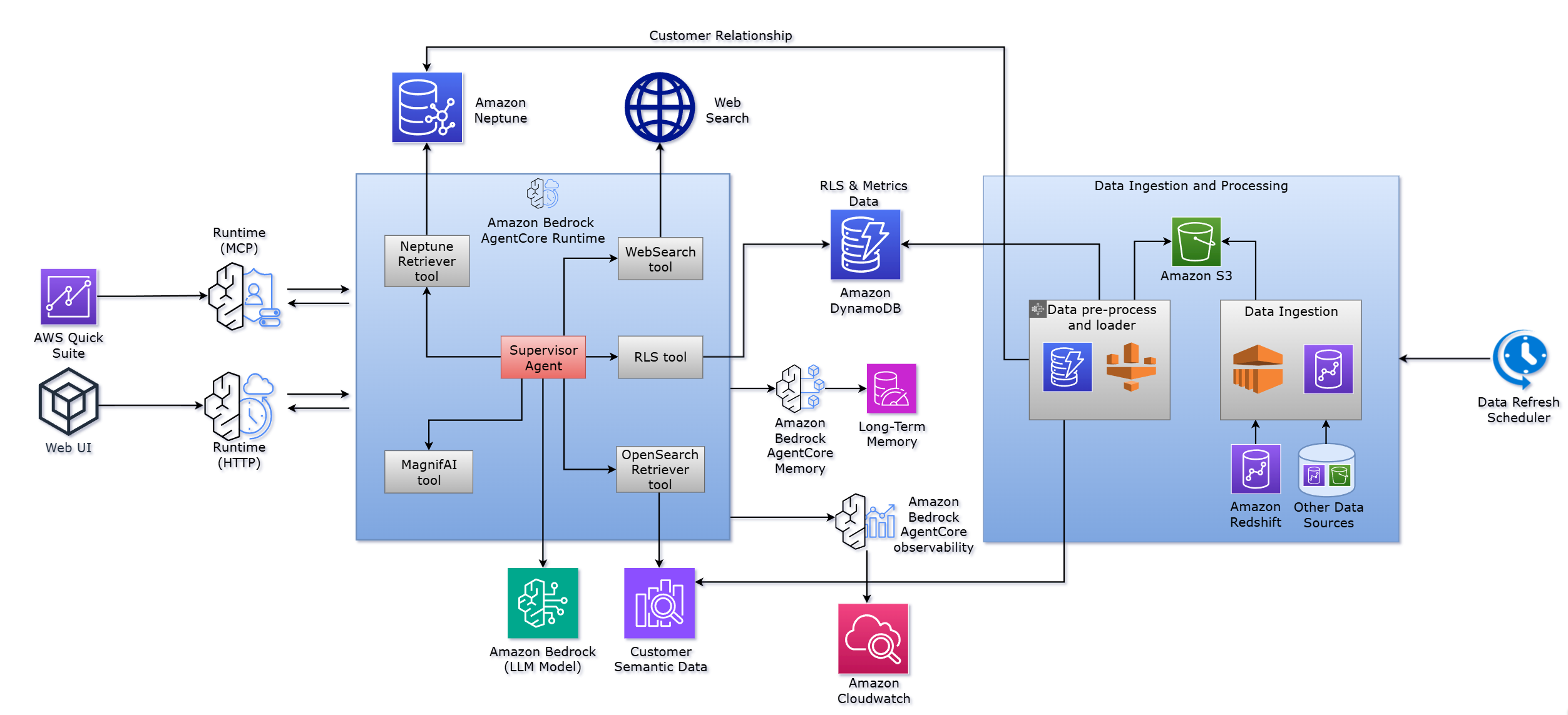
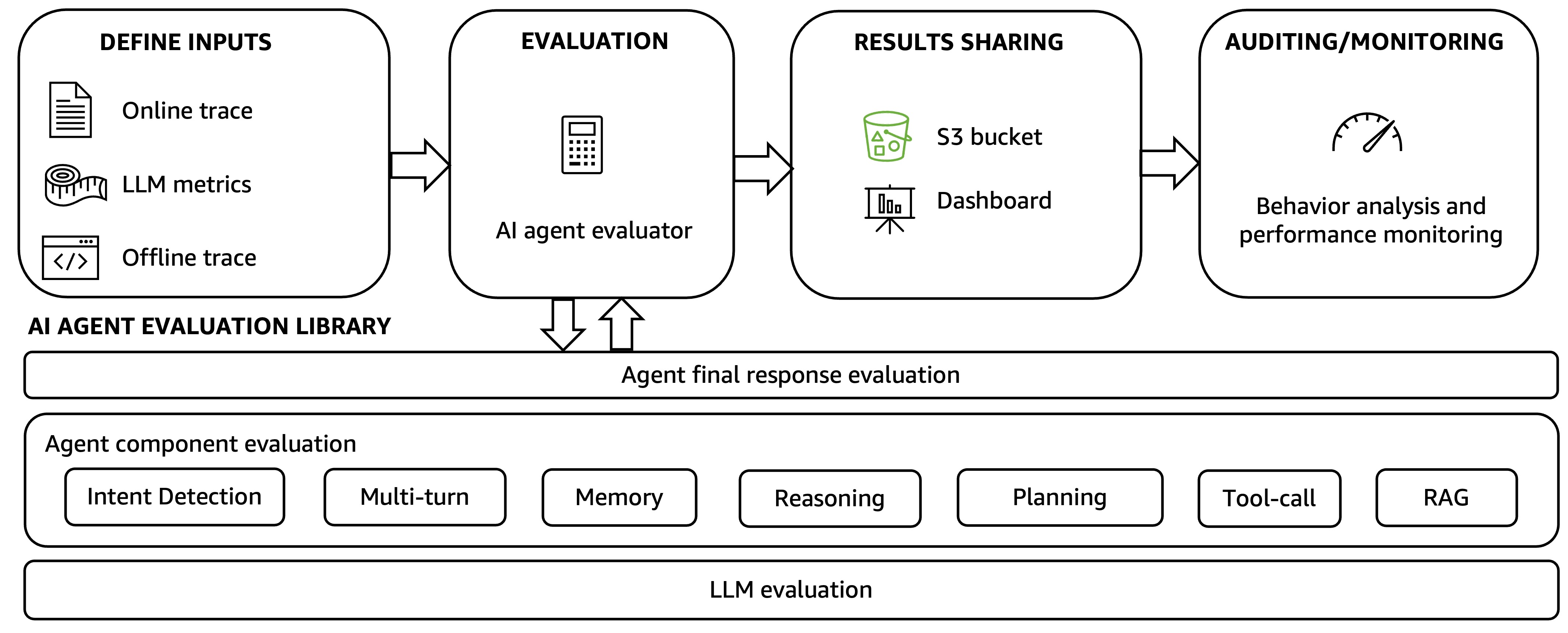
Accelerating AI model production at Hexagon with Amazon SageMaker HyperPod
This blog post was co-authored with Johannes Maunz, Tobias Bösch Borgards, Aleksander Cisłak, and Bartłomiej Gralewicz from Hexagon. Hexagon is the global leader in measurement technologies and provides the confidence that vital industries rely on to build, navigate, and innovate. From microns to Mars, Hexagon’s solutions drive productivity, quality, safety, and sustainability across aerospace, agriculture, …
Accelerating AI model production at Hexagon with Amazon SageMaker HyperPod Read More »