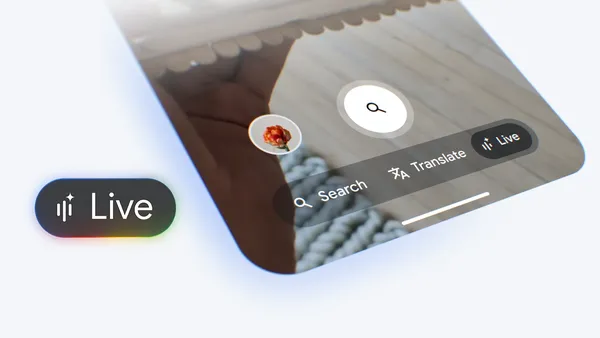
5 ways to get real-time help by going Live with Search
Try it out today in the Google app for Android and iOS.
Try it out today in the Google app for Android and iOS.

Google AI Pro and Ultra subscribers now get higher limits to Gemini CLI and Gemini Code Assist IDE extensions.

Today marks the launch of the Data Commons Model Context Protocol (MCP) Server, which allows developers to query our connected public data with simple, natural language.…

Google Arts & Culture’s “Moving Paintings” project uses Veo, Google’s advanced video generation model, to animate static art.

Google announces its first cohort of 25 startups using AI to improve public services.
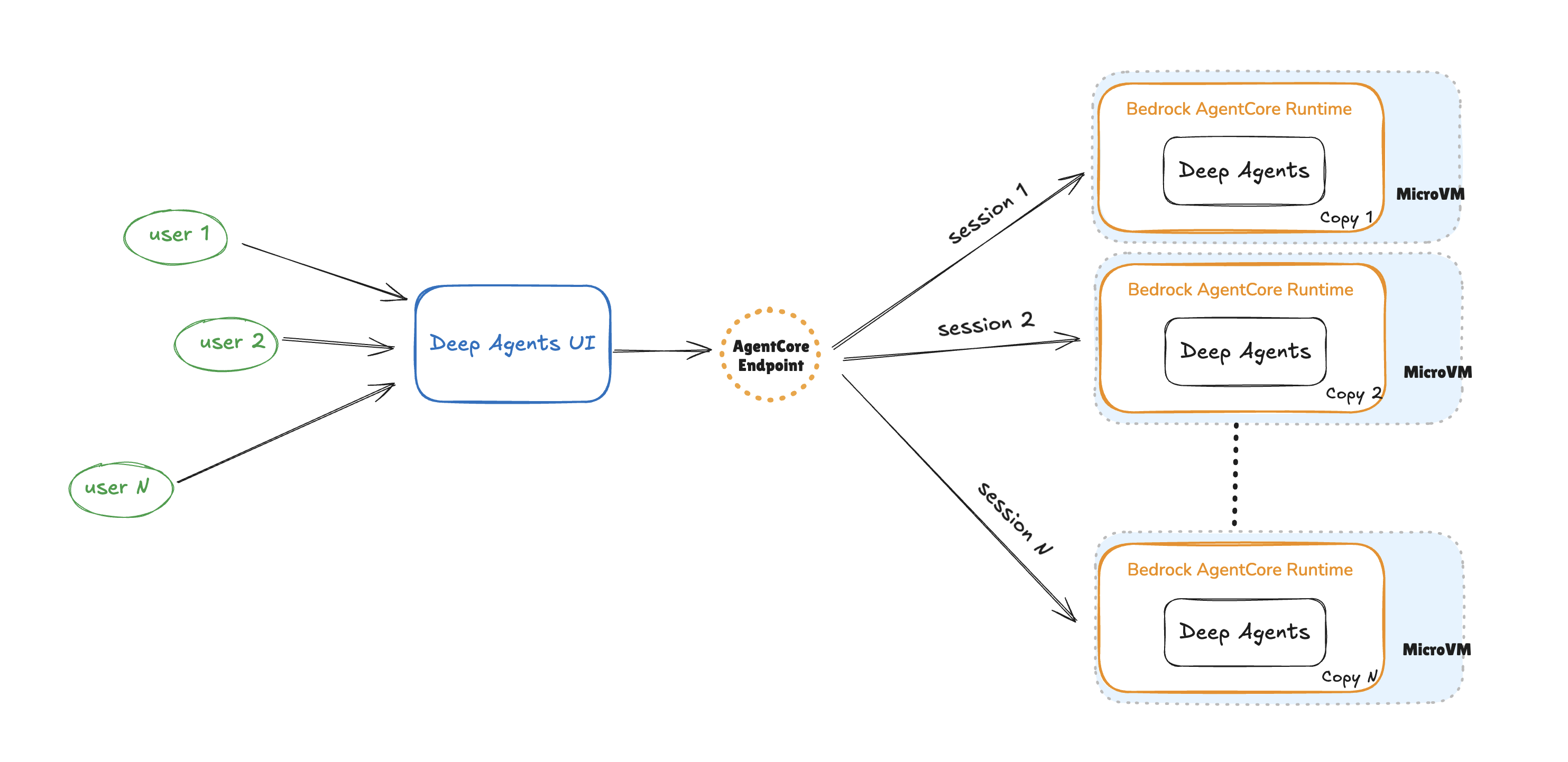
AI agents are evolving beyond basic single-task helpers into more powerful systems that can plan, critique, and collaborate with other agents to solve complex problems. Deep Agents—a recently introduced framework built on LangGraph—bring these capabilities to life, enabling multi-agent workflows that mirror real-world team dynamics. The challenge, however, is not just building such agents but …
Running deep research AI agents on Amazon Bedrock AgentCore Read More »
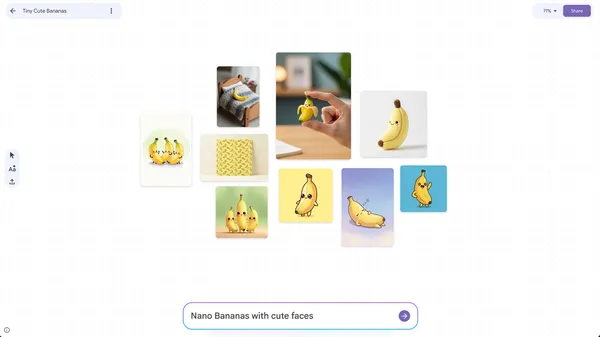
Mixboard is an experimental, AI-powered visual brainstorming tool that helps you explore, expand and refine ideas.
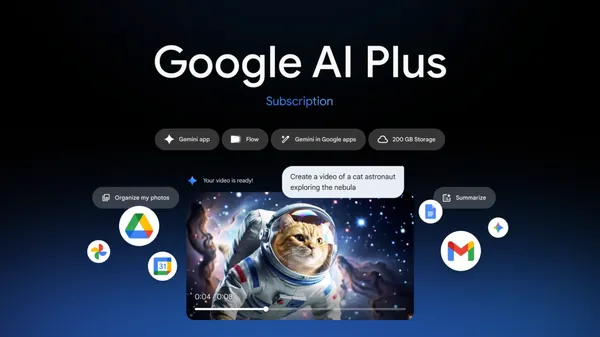
Google AI Plus — our newest AI plan — is now available in more than 40 more countries.
AI Mode in Google Search is starting to roll out globally in Spanish today.
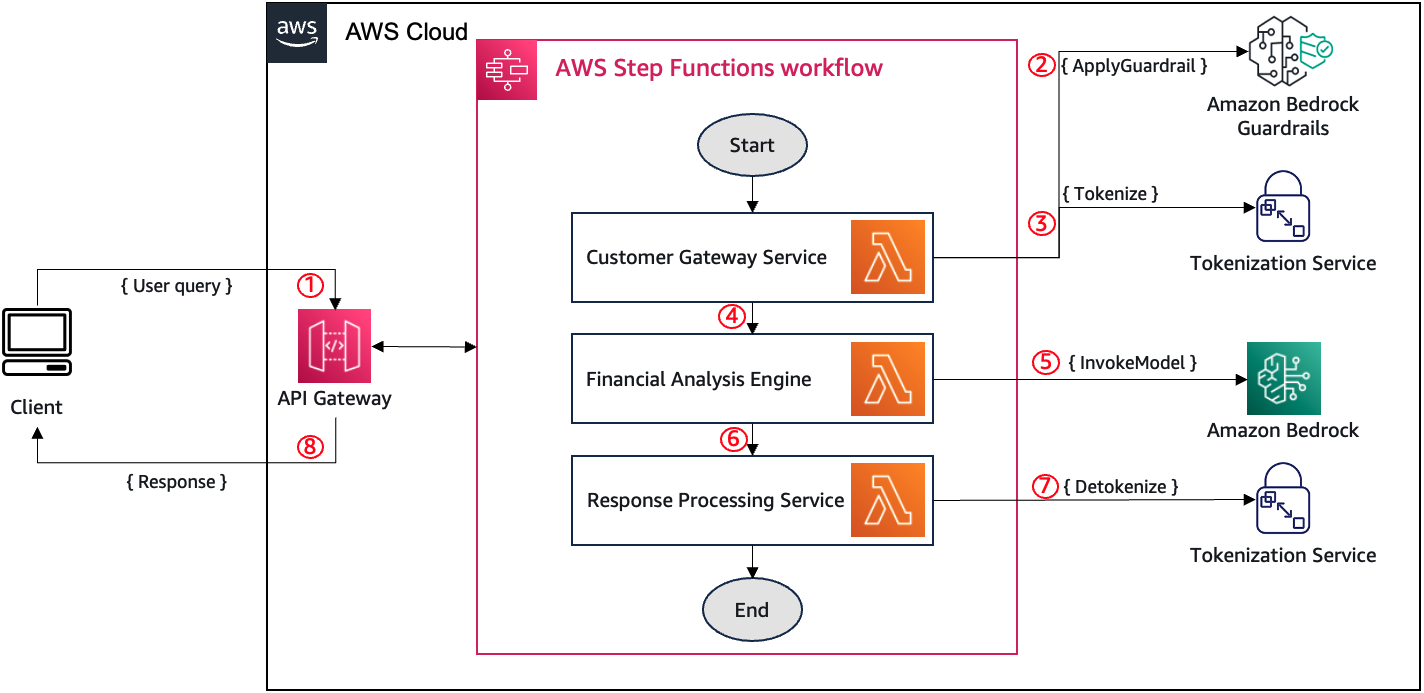
This post is co-written by Mark Warner, Principal Solutions Architect for Thales, Cyber Security Products. As generative AI applications make their way into production environments, they integrate with a wider range of business systems that process sensitive customer data. This integration introduces new challenges around protecting personally identifiable information (PII) while maintaining the ability to …
Integrate tokenization with Amazon Bedrock Guardrails for secure data handling Read More »