How Palo Alto Networks enhanced device security infra log analysis with Amazon Bedrock
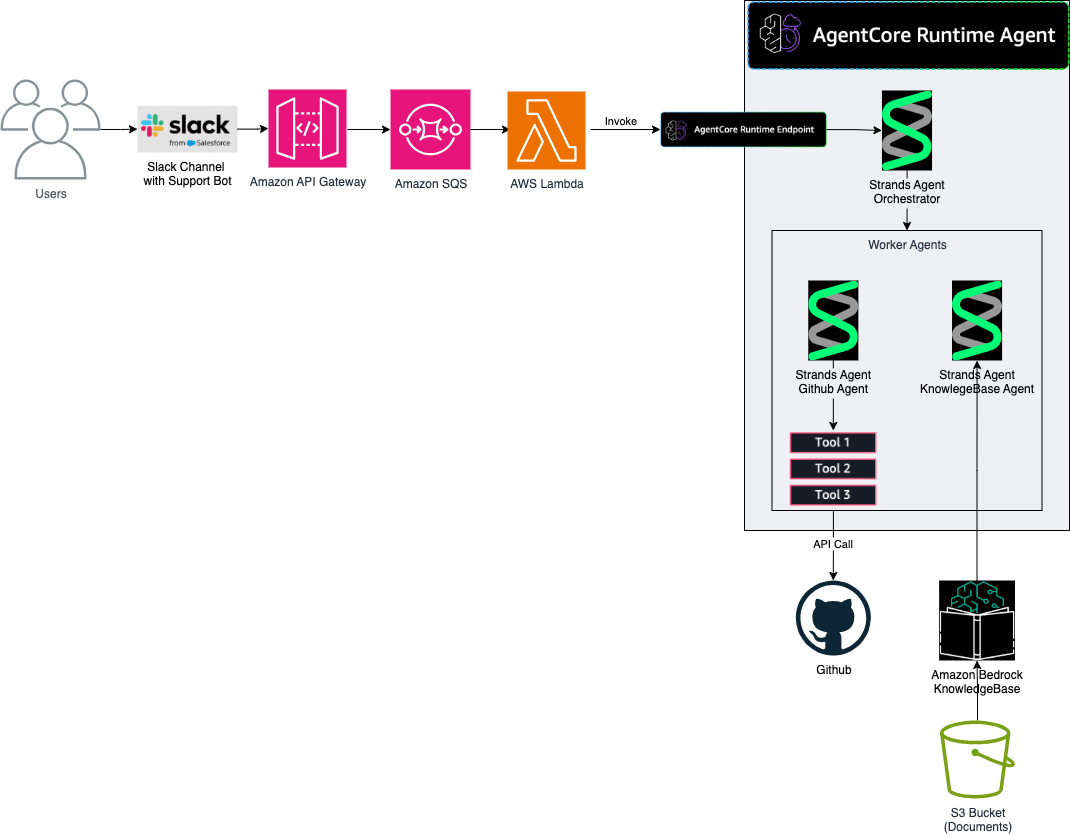
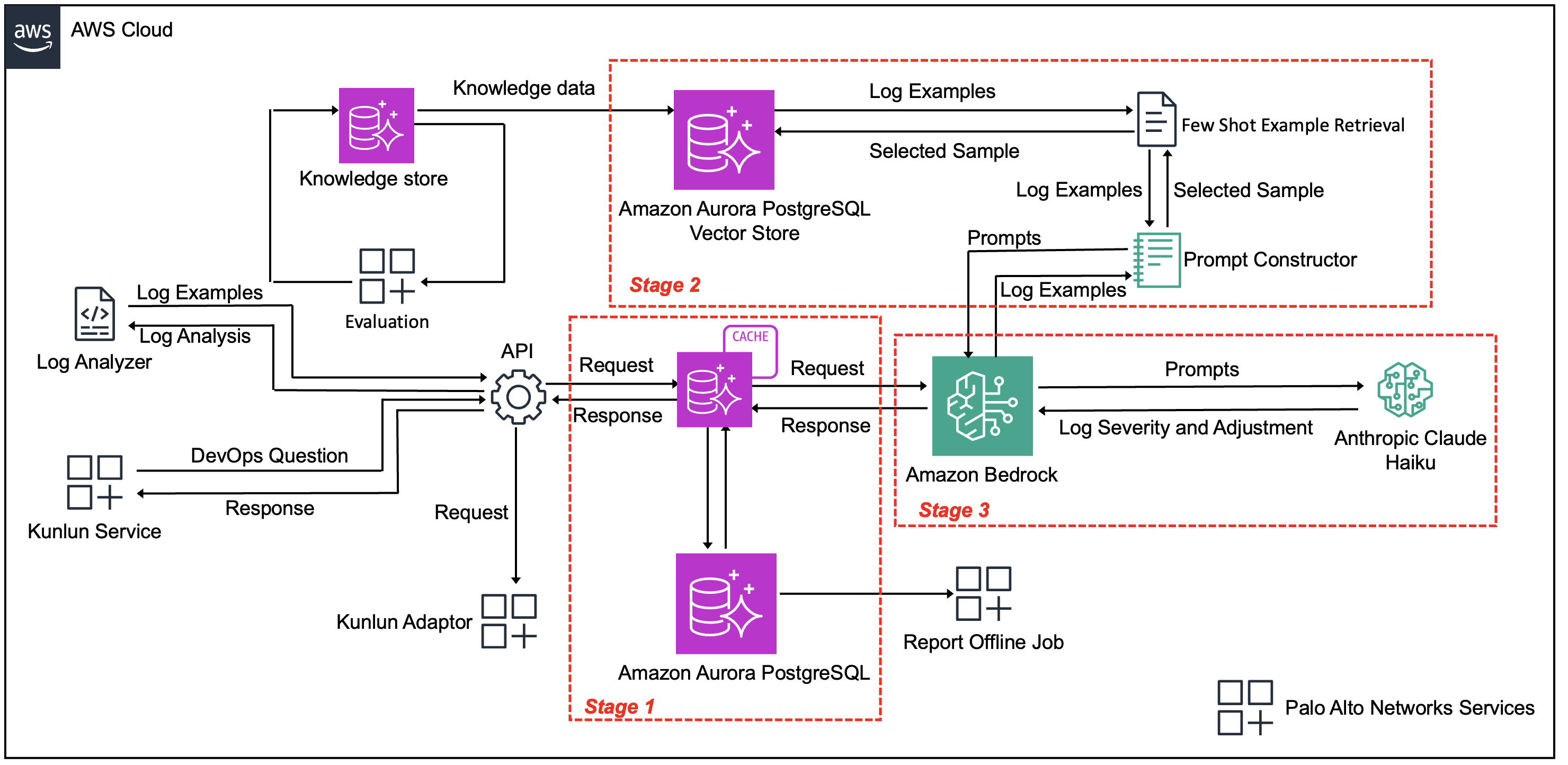
This post is co-written by Fan Zhang, Sr Principal Engineer / Architect from Palo Alto Networks. Palo Alto Networks’ Device Security team wanted to detect early warning signs of potential production issues to provide more time to SMEs to react to these emerging problems. The primary challenge they faced was that reactively processing over 200 …
How Palo Alto Networks enhanced device security infra log analysis with Amazon Bedrock Read More »