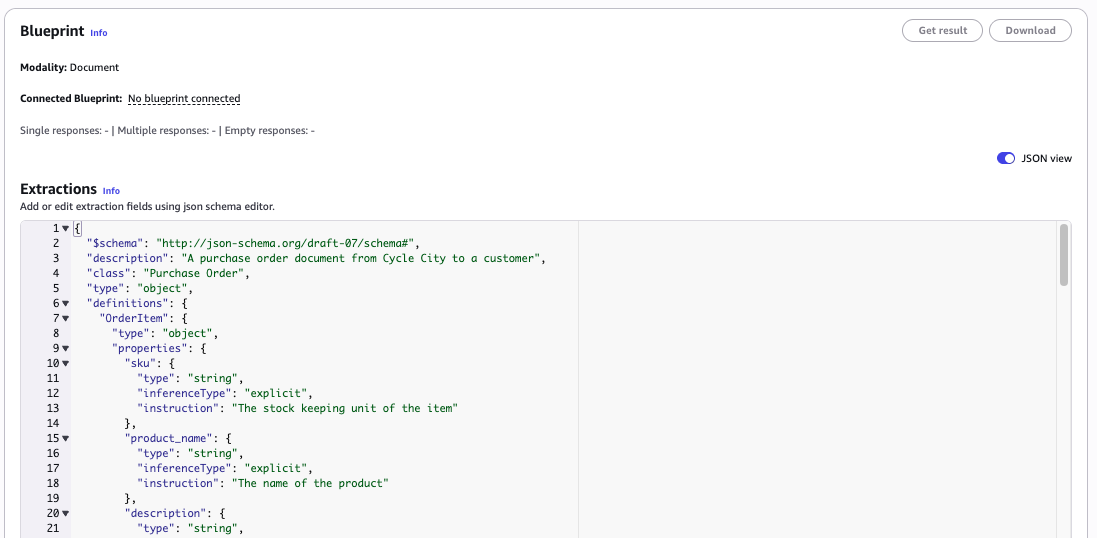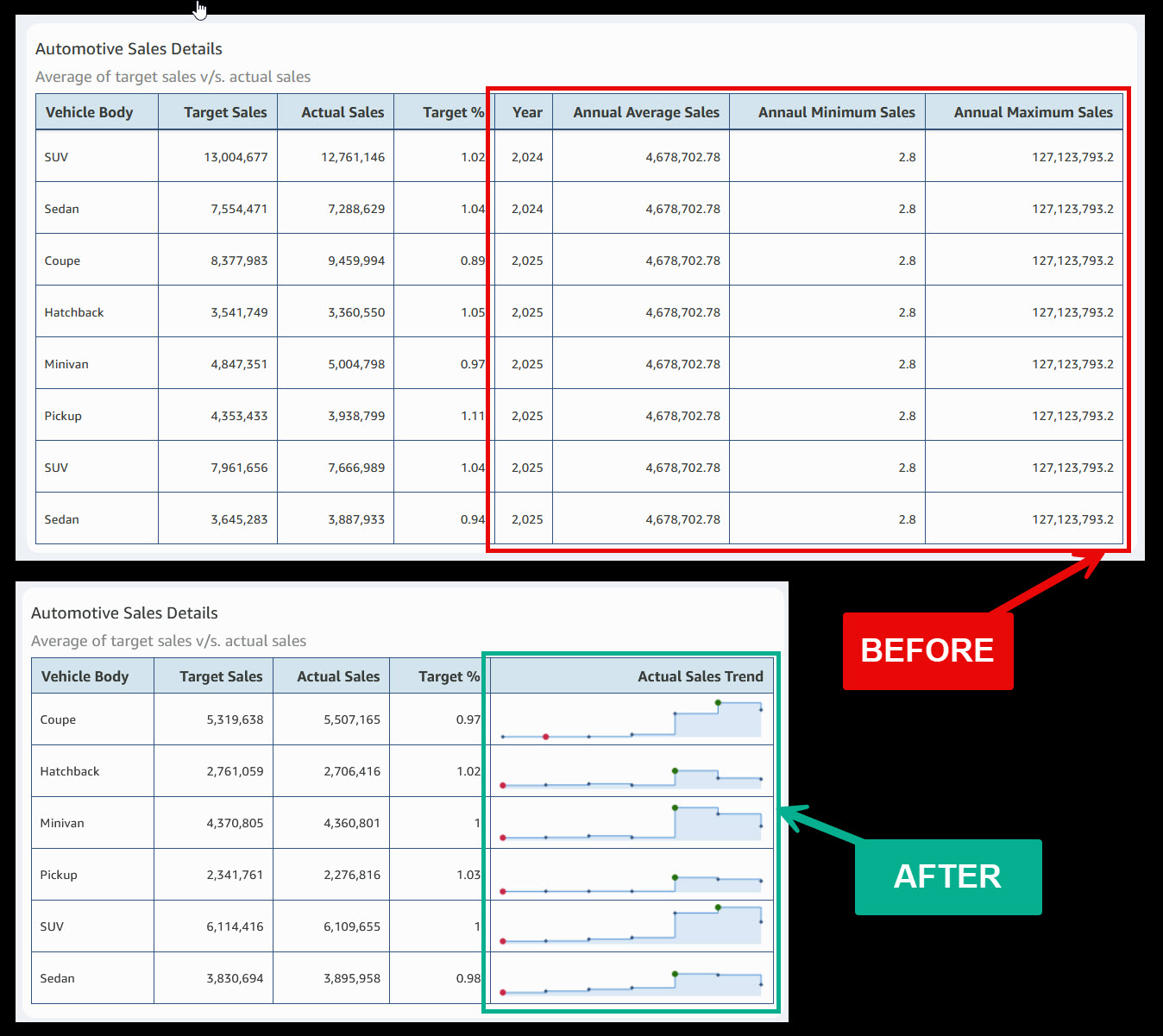
Spot trends faster, sort smarter: Unlocking Sparklines and Custom Sort in Amazon Quick
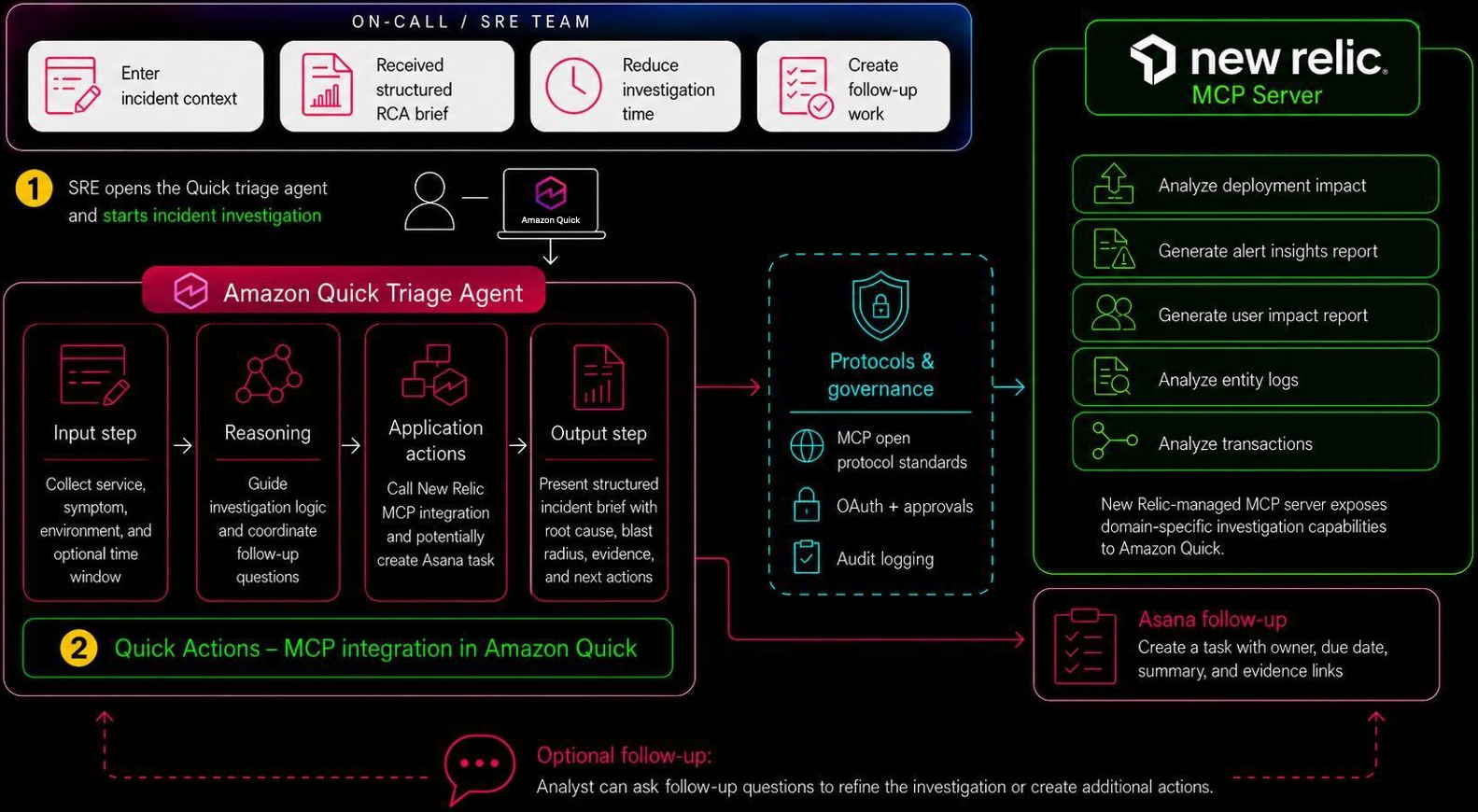
Amazon Quick Sight, the business intelligence capability of Amazon Quick, delivers a unified BI experience, from modern interactive dashboards and natural language querying to pixel-perfect reports, machine learning insights, and embedded analytics at scale. Amazon Quick brings together AI-powered agents for business insights, research, and automation in one integrated experience, helping teams work smarter and […]
Spot trends faster, sort smarter: Unlocking Sparklines and Custom Sort in Amazon Quick Read More »