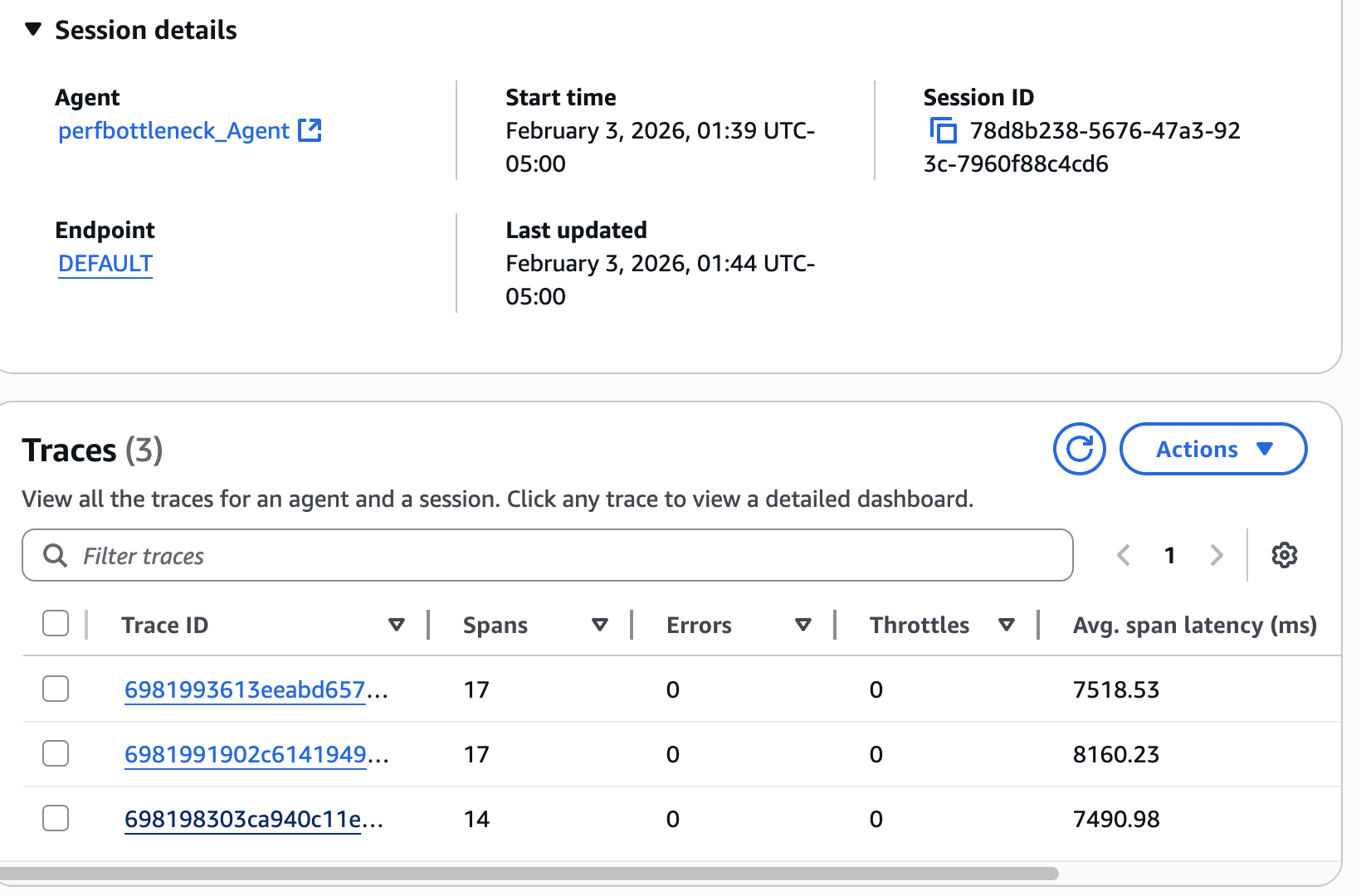
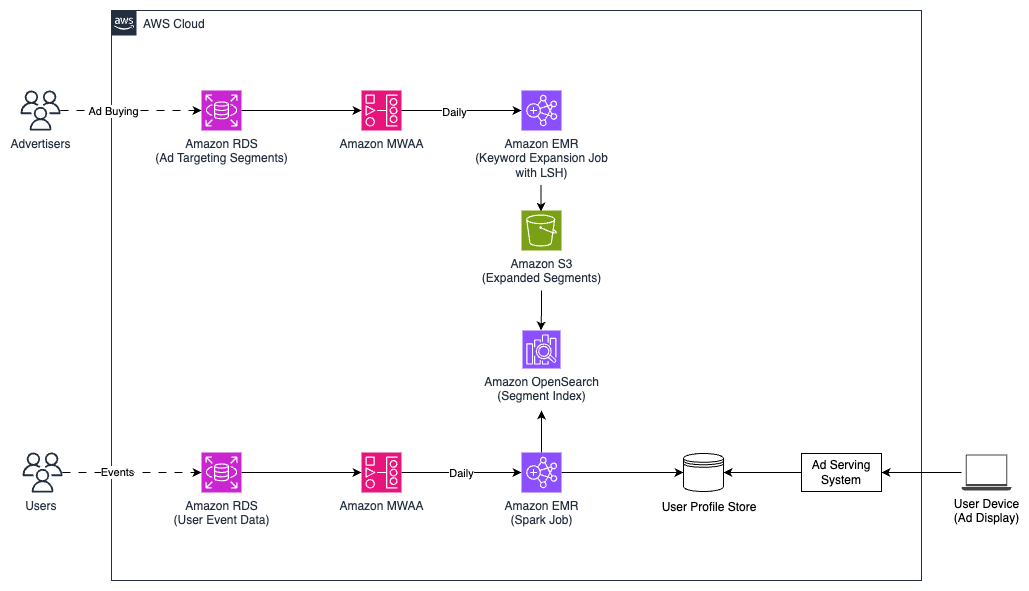
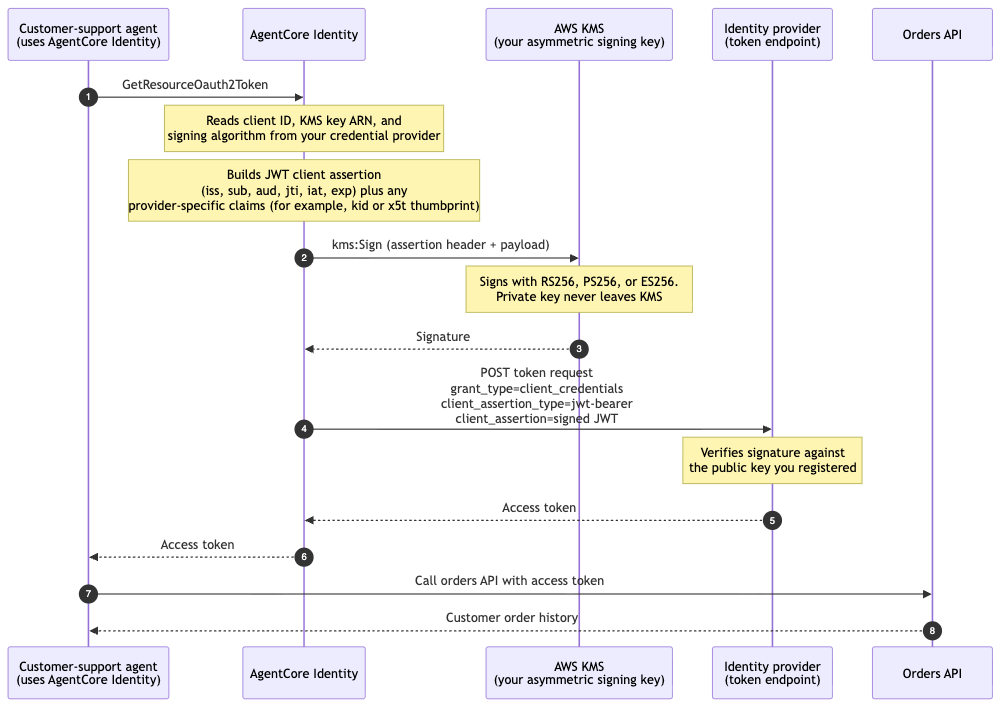
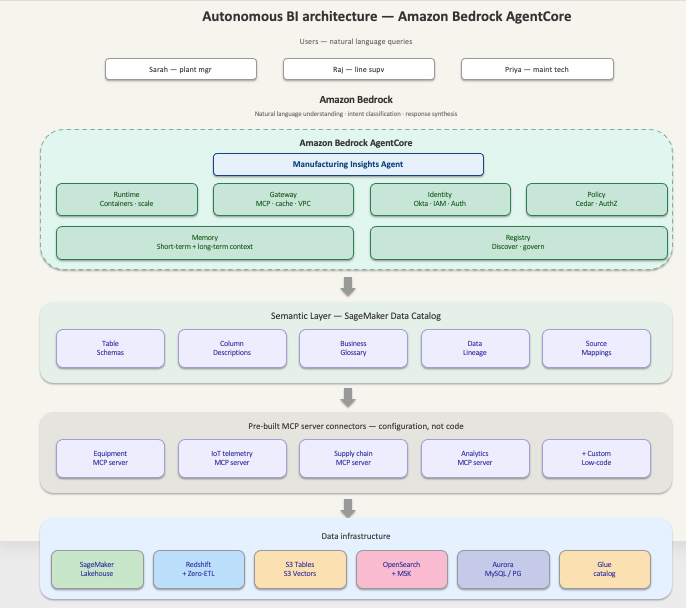
Announcing the Agentic Catalog Experience in Amazon Quick
As organizations embrace AI-powered analytics, the value of a natural language (Text2SQL) answer is only as good as the business context behind it. We’re entering a phase where semantic richness (table and column descriptions, and relationships) must flow directly from where it’s authored in upstream data catalogs and semantic tools into the AI products that […]
Announcing the Agentic Catalog Experience in Amazon Quick Read More »