Social engineering through phishing remains one of the most common tactics for launching cyberattacks. AI-generated phishing email messages now pose a new challenge for security teams managing email systems, significantly raising the risk because of their advanced sophistication. Modern social engineers use generative AI and open source intelligence (OSINT) to craft thousands of unique messages with perfect grammar, appropriate context, and personalized details. Today, an indicator of a phishing email message might be a perfectly written, professionally formatted message.
The evolution of phishing
For someone like John, an IT security engineer at a mid-sized firm, the rules of phishing detection were once straightforward: flag the typos, catch the generic salutations, and quarantine anything with a mismatched sender domain. These were the defining characteristics of an earlier era of phishing, when attacks sent millions of generic, error-riddled email messages at scale, relying on volume rather than precision to find victims. Security filters were built exactly for these threats, and for years, they were effective. Poor grammar, generic greetings, and mismatched logos were indicators that gave attackers away.
The threat landscape John monitors today looks nothing like the ones those filters were designed to catch. Generative AI changed how phishing works. Attacks are now grammatically correct, contextually accurate, and personalized to the target. These messages don’t trigger traditional filters because those filters weren’t designed to catch them.
The threat is no longer identifiable by what it looks like, but what it knows. Modern AI systems run OSINT operations that pull data from professional networks, corporate websites, and publicly available digital footprints to map out organizational hierarchies and relationships. With that intelligence, social engineers can process massive datasets at scale to generate contextually accurate messages personalized to your organization. These communications can even adapt in real time based on your responses, shifting tone or adjusting details to stay consistent with the conversation.
Amazon Bedrock is a fully managed service that makes high-performing foundation models (FMs) from leading AI companies available through a unified API, along with capabilities needed to build generative AI applications with security, privacy, and responsible AI. Amazon Bedrock adds an additional layer of analysis to your existing security infrastructure that goes beyond traditional surface-level filtering. It understands context and detects phishing attempts based on behavioral patterns, not grammar quality or formatting. To put that into practice, let’s break down how Amazon Bedrock analyzes an email from the moment it hits your inbox.
Amazon Bedrock uses large-scale general-purpose AI models pre-trained on vast amounts of data. Foundation models can analyze behavioral patterns in email content, understand contextual relationships, and identify anomalies that signal a message might be a phishing attempt. In practice, these capabilities can be structured as a multi-stage analysis pipeline. Each email passes through authentication, behavior analysis, and risk scoring before reaching your users’ inboxes.
Amazon Bedrock offers two integrated capabilities to power your AI-driven phishing defense. Pre-trained foundation models bring sophisticated natural language understanding that can detect nuanced manipulation, contextual anomalies, and impersonation patterns invisible to rule-based systems. The second capability, Amazon Bedrock Guardrails, provides configurable safeguards that help align foundation model interactions with your organization’s responsible AI policies and application requirements, without requiring custom detection logic. Together, these capabilities can be integrated into a multi-stage email analysis pipeline.
Amazon Bedrock workflow for intelligent phishing defense
In the workflow solution, each message first undergoes standard authentication checks (Sender Policy Framework (SPF), DomainKeys Identified Mail (DKIM), Domain-based Message Authentication, Reporting and Conformance (DMARC)). These protocols confirm that the sending server is authorized to send on behalf of the domain and that the message hasn’t been tampered with in transit. The phishing detection workflow, powered by the Amazon Bedrock foundation models, analyzes the message against three key factors: word choice, communication style deviations, and contextual appropriateness of requests. Detecting these subtle inconsistencies in writing style and misaligned requests adds a deeper layer of analysis on top of traditional security controls. AI analysis also requires careful governance to confirm it operates responsibly and within your defined boundaries. Amazon Bedrock Guardrails help filter both input prompts and model outputs. They prevent responses that could inadvertently leak confidential data, and they check that analysis results adhere to the policies you set. Keep in mind that guardrails need careful configuration and calibration to meet your application requirements.
Implementing Amazon Bedrock Guardrails for analysis
Amazon Bedrock Guardrails give you granular control over how foundation models process email content through content filters, denied topics, word filters, and sensitive information filters. For example, John the security engineer can configure guardrails to automatically redact sensitive personally identifiable information (PII) discovered during email analysis, helping to prevent the foundation model from generating responses that could inadvertently leak confidential data.
However, guardrail configurations for security analysis require careful calibration. While content filters protect against inappropriate inputs and outputs, overly restrictive settings can prevent the model from analyzing suspicious content that legitimately needs to be evaluated. If a social engineer includes offensive language in an email message to bypass filters, your guardrails must allow the security system to analyze that content. At the same time, the guardrails must still protect against inappropriate inputs and outputs in other contexts. Guardrails also provide contextual grounding checks that keep model responses factually anchored to the email content being analyzed, reducing false positives caused by model hallucination. This allows the AI-powered analysis to operate within defined boundaries while still detecting intricate patterns.
In this post, you will learn how to implement a multi-stage email analysis pipeline using Amazon Bedrock foundation models that evaluate sender behavior patterns, contextual appropriateness, and communication anomalies to identify AI-generated phishing attempts before they reach your users.
Implementation framework
The following framework shows how to put this into practice within your existing email security infrastructure, so that someone in John’s position can move from reactive filtering to proactive detection. After your standard authentication checks (SPF, DKIM, DMARC) confirm an email comes from a legitimate mail server, the phishing detection workflow goes a step further by layering in behavioral analysis. Your system moves from checking whether a server is authorized to evaluating whether a message matches how your coworker normally communicates.
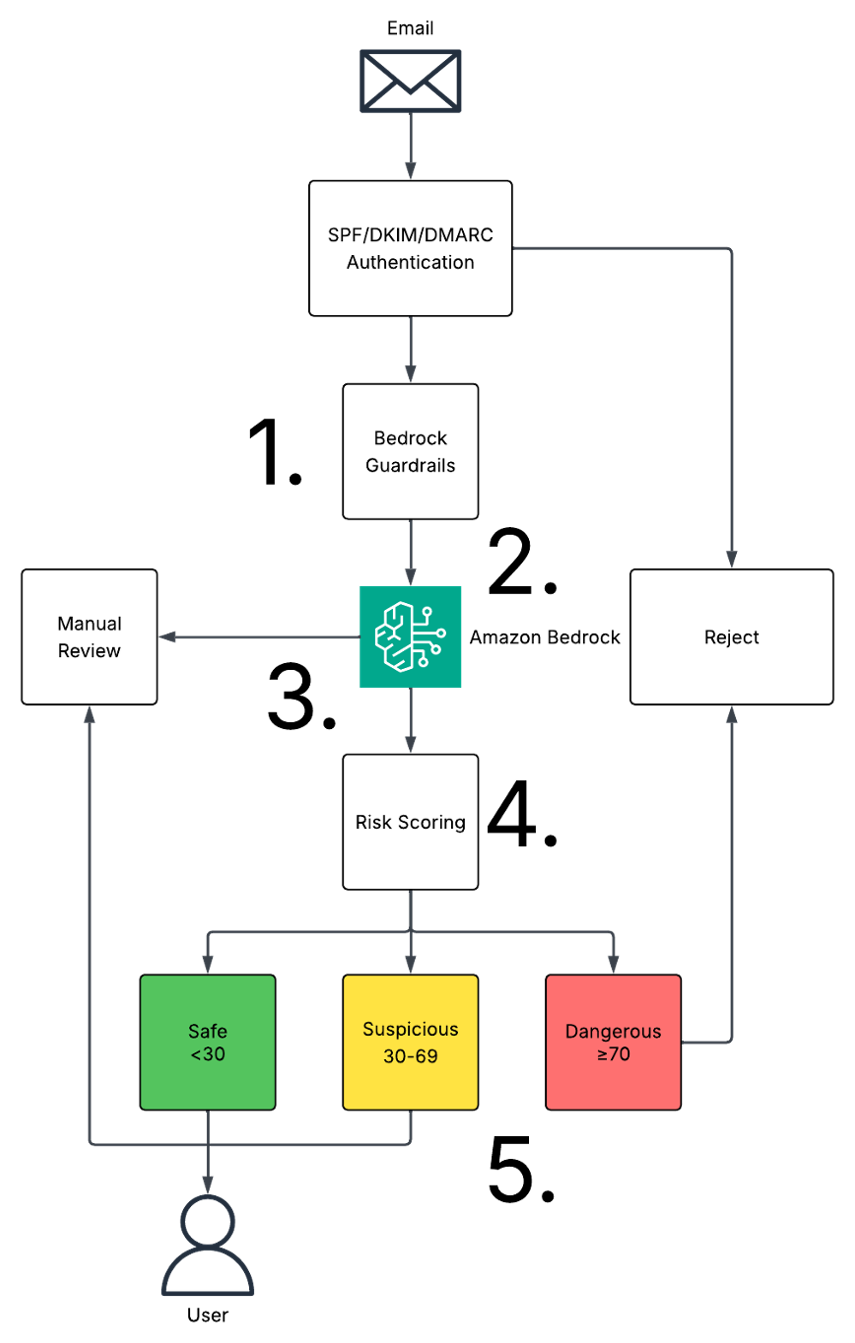
Figure 1 maps the five-step email security analysis workflow, from initial guardrail screening through AI analysis, risk scoring, and final routing decisions.
Before diving into the implementation, let’s clarify what each component does. Behavioral analysis starts with a sender baseline tracker, which is a profile of each person who sends email to you. The sender baseline tracker logs how your employees normally write, so the Amazon Bedrock analysis pipeline has a reference point to compare against.
Over continued use, the phishing detection workflow will understand the words your employees use, how formal or casual they are, what they usually ask for, and who they normally communicate with. Consider John’s environment: A coworker who usually sends quick one-liners suddenly writes a formal email requesting an urgent wire transfer. The analysis pipeline catches that shift and flags it for John’s team to take a closer look.
This can help reduce false alarms and save time that John’s team might otherwise spend sorting through flagged email messages that turn out not to be real threats.
Here’s a high-level outline on how these components work together when an email enters your phishing detection workflow:
Step 1: Input guardrails and pre-processing
The phishing detection workflow first runs incoming email messages through Amazon Bedrock Guardrails, which screen for sensitive content and flag anything that should go to manual review before the analysis begins.
Step 2: Prompt construction with context
After an email clears that check, the workflow constructs an analysis prompt by combining the email’s content with the sender’s baseline communication patterns, organizational context, and known phishing examples by using Amazon Bedrock Knowledge Bases. That way, the model is evaluating the message against a full picture, not in a vacuum.
Step 3: AI-powered analysis with guardrails
The foundation model processes the email using the constructed prompt while guardrails keep the analysis within your defined security boundaries. The foundation model can examine suspicious content thoroughly while the guardrails keep it from generating outputs that expose sensitive information in the process.
Step 4: Multi-factor risk scoring
From that analysis, the Amazon Bedrock pipeline generates three scores: one for content anomalies, one for behavioral deviations, and one for contextual alignment. The pipeline combines them into a single risk score from 0–100, which determines where the email is routed.
Step 5: Classification and automated routing
Safe messages land in your employees’ inboxes as usual. Suspicious email messages get quarantined for your security team to review. Dangerous messages are blocked outright.
Continuous learning through feedback
These steps happen in milliseconds as messages move through your routing system. Your existing infrastructure still handles message routing and delivery. The analysis runs alongside it as an inspection layer that evaluates behavioral risk before messages reach your users’ inboxes.
Over continued use, the phishing detection workflow improves its accuracy in making these calls through a few complementary techniques. Dynamic prompt engineering, the practice of iteratively refining the instructions sent to the foundation model based on real-world results, takes feedback from the security team and incorporates it directly into your analysis prompts, gradually fine-tuning how the model evaluates potential issues. That feedback loop also feeds into a growing knowledge base of validated examples, where confirmed phishing attempts and legitimate messages are cataloged and later used as few-shot learning demonstrations in future prompts. So, when a new email comes in, the model isn’t working from scratch. It references your real, previously verified examples that match similar patterns to make a more informed judgment.
Example: AI-generated phishing email analysis
The following AI-generated phishing email message demonstrates modern phishing sophistication. Notice the perfect grammar, legitimate business context, and reference to a real purchase order (PO) format. None of these would trigger traditional spam filters. Following the email message is a simplified prompt structure showing how Amazon Bedrock analyzes messages against sender baselines and known phishing patterns. The prompt combines email content with historical context to support behavioral analysis beyond surface-level filtering. Last is a sample risk assessment output identifying a vendor impersonation attempt. The Amazon Bedrock pipeline flagged behavioral anomalies, including a first-ever payment change request, along with domain inconsistencies that traditional authentication checks missed.
Sample phishing email
Prompt structure and risk assessment output
The continuous feedback loop
Behind these examples, the phishing detection system maintains dynamic sender baselines in a database that tracks each of your sender’s typical communication patterns, vocabulary, tone, and request types. False positives flagged by John’s security team are fed back into the phishing detection pipeline, updating baselines to account for legitimate variations in how senders communicate. Confirmed phishing patterns are cataloged alongside these baselines to enrich future prompt context with current intelligence. The result is a feedback loop where every correction and every confirmed threat make the analysis more accurate.
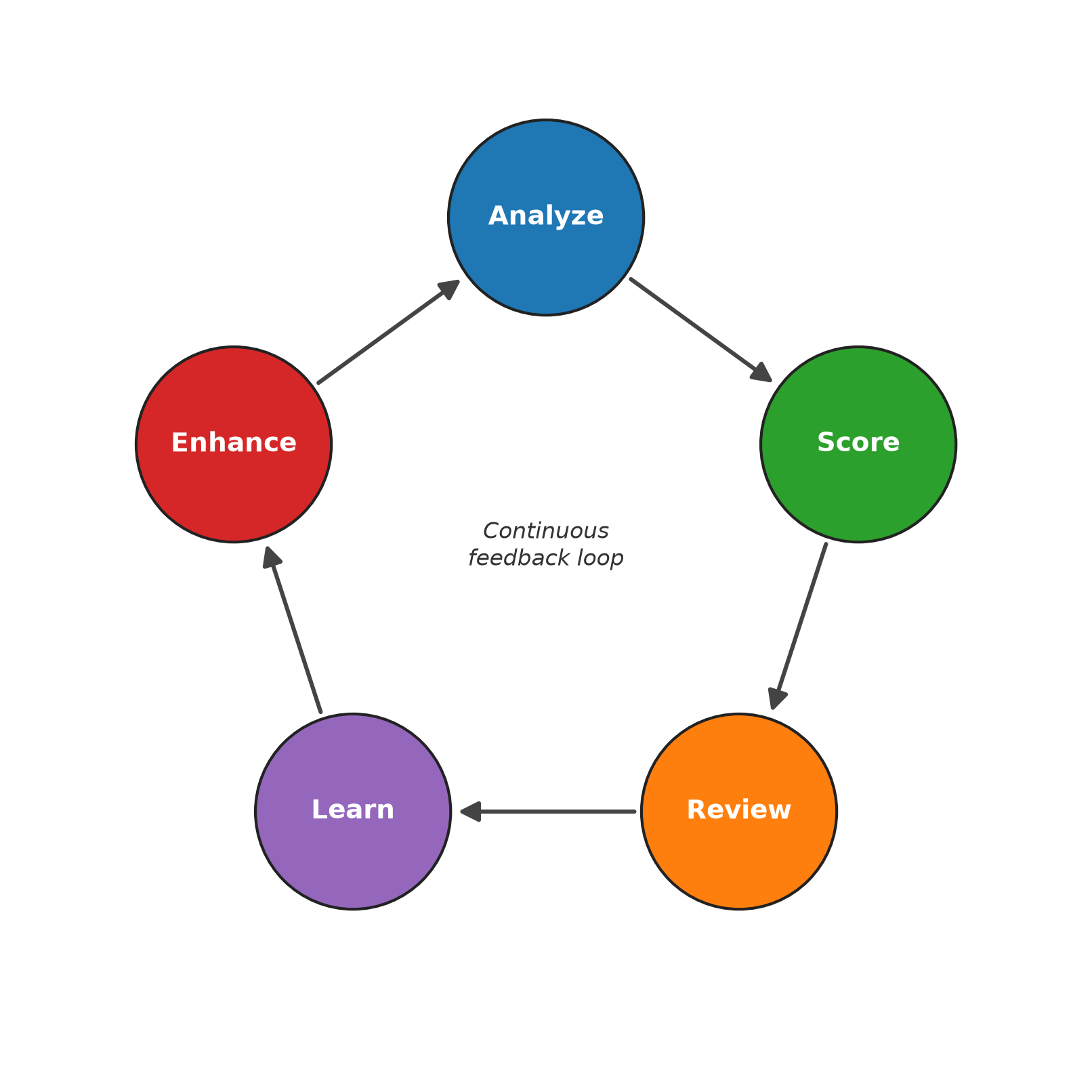
The continuous feedback pipeline runs across five stages:
1. Analyze – The foundation model evaluates your incoming email messages using dynamic prompts built from accumulated phishing attempt intelligence and sender context.
2. Score – Based on that analysis, a risk score from 0–100 is assigned, and suspicious messages are quarantined for your security team’s review.
3. Review – Flagged messages get classified as either a confirmed phishing attempt or a false positive.
4. Learn – Those classifications feed back into your system, updating the example library, sender behavior baselines, and emerging patterns catalog.
5. Enhance – New examples and confirmed phishing attempt patterns get incorporated into the analysis prompts, improving detection accuracy for the next cycle.
Early cycles will require more hands-on review as your system creates its baseline understanding. For John, that means his team initially spends more time classifying flagged messages, but the investment pays off quickly. As the example library and sender profiles grow, the model becomes progressively more accurate at distinguishing legitimate communications from phishing attempts. John stays in the loop throughout, but his attention shifts from sifting through noise to focusing on genuinely suspicious messages.
Each cycle through this loop creates a stronger, more adaptive defense that evolves alongside the phishing attempts it was designed to catch. That continuous improvement is what separates this feedback-driven detection model from static, signature-based detection.
Conclusion
Phishing detection can no longer rely on surface-level indicators such as typos and awkward phrasing. The framework in this post addresses that shift by combining the Amazon Bedrock foundation models with behavioral analysis, contextual grounding, and a continuous feedback loop that improves accuracy over time. Amazon Bedrock catches subtle manipulation attempts that trained eyes might miss, while your existing infrastructure keeps doing what it was built to do.
Pair these defenses with solid verification processes, healthy skepticism toward unexpected requests, and a security culture that keeps your teams moving confidently. Employee awareness still matters, but now generative AI works with you to identify and help prevent impersonation attempts. AI made phishing harder to detect. The same technology, applied defensively, makes it harder to succeed.
To begin implementing these defenses, start by visiting the Amazon Bedrock console. You can configure Amazon Bedrock Guardrails for your email flow and follow this tutorial to build your own email phishing detection pipeline. Share your experience with AI-powered security in the comments.
About the authors