
This post is co-written with Vladimir Turzhitsky, Varun Kumar Nomula and Yezhou Sun from MSD.
Generative AI is transforming the way healthcare organizations interact with their data. Large language models (LLMs) can help uncover insights from structured data such as a relational database management system (RDBMS) by generating complex SQL queries from natural language questions, making data analysis accessible to users of all skill levels and empowering organizations to make data-driven decisions faster than ever before.
Merck & Co., Inc., Rahway, NJ, USA (hereinafter “MSD”) is a leading global pharmaceutical company that has been inventing medicines and vaccines for over 130 years. Headquartered in Rahway, New Jersey, the company delivers innovative health solutions through its prescription medicines, vaccines, biologic therapies, and animal health products. MSD collaborated with AWS Generative Innovation Center (GenAIIC) to implement a powerful text-to-SQL generative AI solution that streamlines data extraction from complex healthcare databases. MSD employs numerous analysts and data scientists who analyze databases for valuable insights. Currently, they spend considerable time manually querying these databases, which can slow down productivity and delay data-driven decision-making. The text-to-SQL solution can streamline this process significantly. For example, instead of writing complex SQL queries, an analyst could simply ask, “How many female patients have been admitted to a hospital in 2008?” The solution would generate the appropriate SQL query, potentially reducing query time from hours to minutes. This approach not only saves time but also democratizes data access, allowing even non-technical staff to extract insights quickly, thereby enhancing overall organizational productivity and accelerating informed decision-making.
Although some LLMs are capable of generating SQL code, creating an effective text-to-SQL pipeline necessitates precise prompting and may not be achievable with all models. Aside from generic instructions on SQL code generation, the prompt also needs to include all the necessary database information to write executable queries, because this context is crucial for generating accurate and schema-specific SQL statements.
This post explains how the solution is built using Anthropic’s Claude 3.5 Sonnet model on Amazon Bedrock. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. To showcase the solution’s capability, we use the open source DE-SynPUF (Data Entrepreneurs’ Synthetic Public Use File) dataset in this post. This dataset is ideal for demonstrating text-to-SQL capabilities because it provides a realistic yet synthetic healthcare data structure that closely mimics real-world scenarios without compromising patient privacy.
Understanding the DE-SynPUF dataset
The DE-SynPUF dataset is a synthetic database released by the Centers for Medicare and Medicaid Services (CMS), designed to simulate Medicare claims data from 2008–2010. It contains de-identified patient records, including demographics, diagnoses, procedures, and medications. This dataset is commonly used for research and development purposes, because it provides a realistic representation of healthcare data without compromising patient privacy. The database schema containing all the tables and their attributes of the dataset looks like the following figure (source).
Due to file size limitations, each data type in the CMS Linkable 2008–2010 Medicare DE-SynPUF database is released in 20 separate samples. For simplicity, we use only data from Sample 1. However, the solution seamlessly works for the database from all the samples too. In our case, we create a local SQLite database by first downloading it from the source site.
Solution overview
Out-of-the-box text-to-SQL solutions are available in several open source libraries, such as LangChain or LlamaIndex. Although they represent good baselines, we encountered several challenges that required a custom approach:
The DE-SynPUF dataset contains coded columns, a typical challenge for datasets used in the industry. Several attributes, such as sex, race and state, aren’t explicitly available in the database. Instead, they are coded: for instance, the sex column is a numerical column containing 1 for male and 2 for female. When writing a query to count the number of female patients, instead of filtering on the sex column containing female, we need to filter on the sex column containing 2. To give the LLM access to these codes without overwhelming the main prompt, we created lookup tools that the LLM can use to look up for sex, race, and state codes.
The DE-SynPUF dataset doesn’t have intuitive column names. In the input prompt, we listed the columns in the database along with their corresponding description to allow the LLM to identify the relevant column based on the user query.
User queries can contain a long list of medical codes corresponding to procedures, diagnoses, or drugs used by patients. For example, the user might ask “Count the number of patients having a diagnosis code list of 2500, 4501, ….” This is again representative of the industry challenge. Because data analysts need to filter on complex combinations of factors, this list can get too long to be reliably rewritten by the LLM in the SQL query. To avoid this, we rewrite the input question with the placeholder CODE_X, for example, “Count the number of patients having a diagnosis code list of CODE_X”. After the SQL query is generated with the placeholder, the user can swap back the actual list of codes before running it.
User queries are often ambiguous. To avoid a discrepancy between the intent in the input question and the generated SQL, we instruct the LLM to also generate its interpretation of the user query before generating the SQL statement. This way, the user can make sure the LLM’s interpretation of the question is in line with their intent. For example, if the user query is “Find the total number of male patients,” the LLM will generate the description “This query counts the distinct number of male beneficiaries from the beneficiary_summary table by filtering on the BENE_SEX_IDENT_CD column where the value is ‘1’ which represents the code for male gender.” It will also generate the SQL statement: SELECT COUNT(DISTINCT “DESYNPUF_ID”) AS num_male_patients FROM beneficiary_summary WHERE “BENE_SEX_IDENT_CD” = ‘1’;.
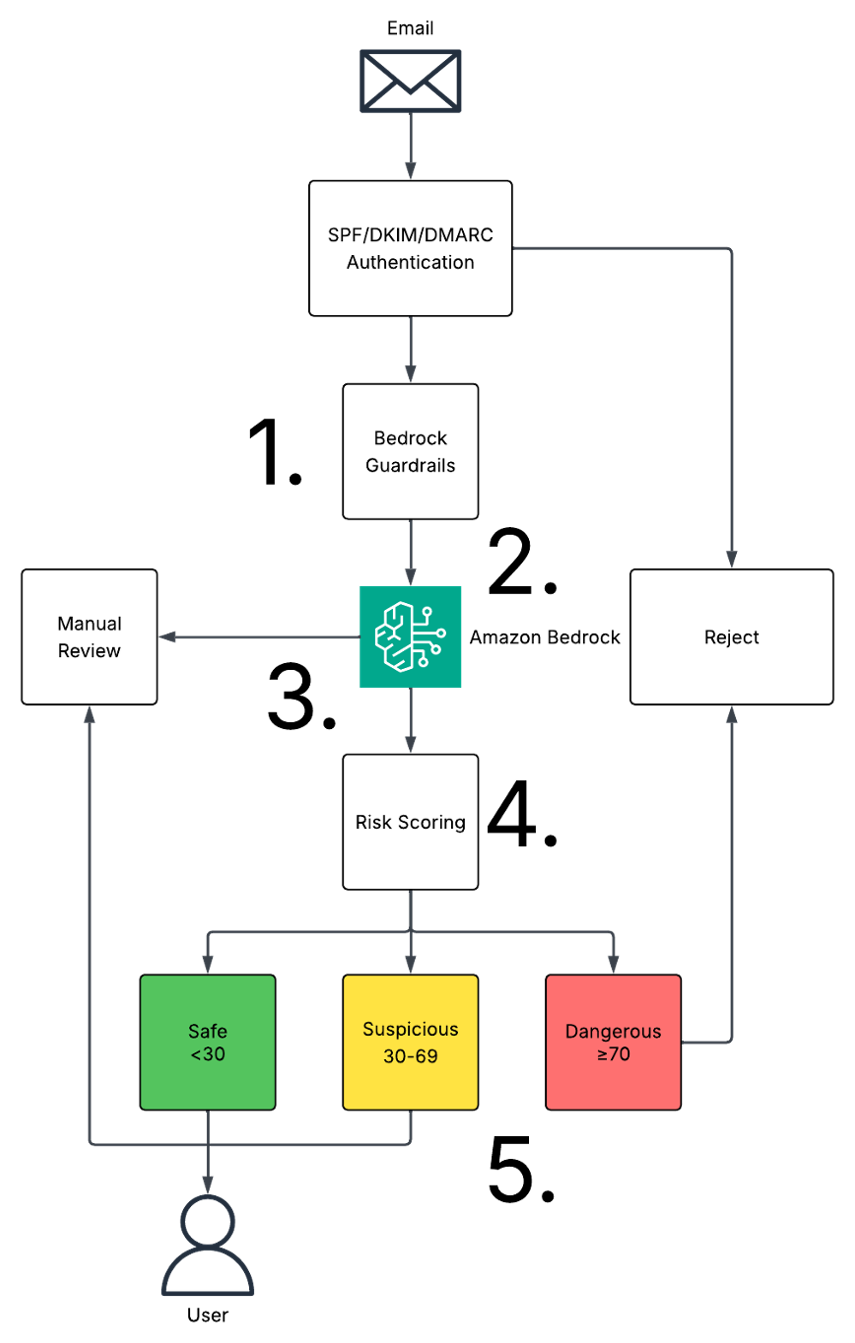
The customized text-to-SQL pipeline is illustrated in the following diagram. It uses Anthropic’s Claude models (LLMs) in Amazon Bedrock to convert natural language questions into SQL queries. Given the comprehensive nature of these inputs, careful management of the total token count is crucial to make sure it remains within the maximum input token limit while providing sufficient context for accurate SQL generation.
The pipeline contains the following variables:
Prompt template
Database schema
Sample data
Few-shot examples (question-SQL pairs)
Column and table descriptions
Lookup tools
The flow of the solution is the following:
The system prompt template is populated with the aforementioned variables.
The system prompt is passed to Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock using the Converse API, along with the list of tools and the user input.
The LLM output is processed with one of two results:
The output contains a call for a lookup tool, in which case we run the lookup tool and append the result to the main prompt, before going back to Step 2.
The output contains a generated SQL query, in which case we return it to the user, along with the generated explanation.
Create and query the DE-SynPUF SQLite database
The following code downloads the DE-SynPUF dataset and uploads it to a local SQLite database, which automatically gets created. Although this example uses SQLite, you can adapt the text-to-SQL pipeline for other database engines by simply updating the prompt with the appropriate schema and syntax information for the target database system. We have a config file that contains the information and paths associated with each database.
Build the text-to-SQL application using in-context learning
You can call a variety of chat models using the Amazon Bedrock Converse API. In our case, we focus on the family of Anthropic’s Claude models. You can select the specific LLM at runtime from the Streamlit UI.
The Converse API allows the LLM to use tools, which need to be specified in the tool_config parameter. In our use case, we use tool calling, also known as function calling, to look up relevant codes for our SQL queries.
Create lookup tools for codes
To address the fact that the DE-SynPUF dataset contains coded columns, we created lookup tools that allow the LLM to search for the codes corresponding to gender, race, and state location. We use Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock and the recently introduced tool calling capability.
To use tool calling, you need to call the model using the Amazon Bedrock Converse API and provide a list of available tools. Each tool is defined by a JSON that contains the name of the tool, its description, and its parameters. For example, the following is the tool spec for the get_state_code function:
The following is the message item from the Converse API response when the user input is “Return all patients from Wisconsin”:
The Converse API response also contains a stopReason item, which can be either end_turn or tool_use. When the stop reason is tool_use, we extract the tool dictionary from the message dictionary and then invoke the function specified in the tool[‘name’] item with the parameters in the tool[‘input’] item. In the preceding example, we would invoke get_state_code(‘WI’), which would return 52.
We then send the result back to the Converse API so the LLM can continue answering the user question. The following is the formatted message that we feed back to the Converse API:
If the stop reason is end_turn, we stop the loop and return the generated SQL query to the user.
Prompt template
We use a system prompt to provide guidelines to the LLM, and only pass the user query in each message. We describe in the following sections how we populate the different placeholders.
Add dataset information to the prompt
To enable the LLM with the necessary information to write executable SQL queries, we need to provide it with database information:
Database schema – The database schema contains each table’s schema by exposing its CREATE TABLE SQL statement. For example, the following is the schema for the table beneficiary_summary:
Sample data – The sample data contains sample records from each table to show the LLM the expected data within the table. For example, for the beneficiary_summary table, it looks as follows:
Column descriptions – The column description is formatted as XML data that contains the column name, its description, and its associated table name. The following is a code example:
Table descriptions – Similarly, the table description contains the table name and its description, as shown in the following example:
Use few-shot examples to improve performance
Few-shot examples allow the LLM to better follow instructions, in particular regarding tool usage. We added some few-shot examples in the prompt that cover a variety of challenging cases. In general, it’s recommended to add few-shot examples that cover a broad spectrum of queries. Few-shot examples can be especially useful in helping the LLM deal with complex or ambiguous requests.
Another approach to few-shot prompting is to use the user query to find the most similar query in a database of sample code, to make the few-shot examples more relevant to the problem at hand. This can be done using a RAG approach, where sample queries are embedded in a vector store and stored with corresponding code. That way, when a new user query comes in, we can look at the closest query in the vector store and pull the corresponding code into the prompt.
Conclusion
In this post, we showcased how you can use generative AI to translate natural language into SQL for complex healthcare databases like DE-SynPUF. We chose the DE-SynPUF dataset for this text-to-SQL solution due to its realistic representation of healthcare data, offering a complex yet accessible environment for demonstrating the capabilities of the system. Its unique challenges, including coded attributes, non-intuitive column names, and the need to handle ambiguous queries, provided an opportunity to showcase the robustness and adaptability of the custom approach in generating accurate SQL queries from natural language input.
By formulating the text-to-SQL use case and building an application using Amazon Bedrock, we demonstrated the potential of this technology to revolutionize data accessibility and analytics in healthcare. The text-to-SQL solution at MSD has markedly accelerated data access, streamlining the extraction process from complex databases and thereby facilitating quicker, more informed decision-making. Additionally, it has boosted analyst productivity by simplifying the SQL query process, allowing you to dedicate more time to data interpretation and strategic decision-making, while also enhancing the company’s scalability for future data-driven growth.
You can extend the text-to-SQL application in several ways, such as:
Using Amazon Bedrock Knowledge Bases to find similar question-SQL pairs for few-shot learning
Incorporating data visualization to present results in a more intuitive manner
Integrating with a voice assistant for hands-free interaction
Extending support to multiple languages for global accessibility
As healthcare organizations continue to generate vast amounts of data, generative AI will play a crucial role in unlocking insights and driving data-driven decision-making. By embracing text-to-SQL technology, you can empower your users to access and analyze data more efficiently, ultimately leading to better patient outcomes and operational excellence.
If you’re interested in working with the AWS Generative AI Innovation Center, reach out to the GenAIIC.
About the authors
Tesfagabir Meharizghi is an Applied Scientist at the AWS Generative AI Innovation Center, where he leads projects and collaborates with enterprise customers across various industries to leverage cutting-edge generative AI technologies in solving complex business challenges. He specializes in identifying and prioritizing high-impact use cases, developing scalable AI solutions, and fostering knowledge-sharing partnerships with stakeholders.
Aude Genevay is a Senior Applied Scientist at the Generative AI Innovation Center, where she helps customers tackle critical business challenges and create value using generative AI. She holds a PhD in theoretical machine learning and enjoys turning cutting-edge research into real-world solutions.
Shinan Zhang is an Applied Science Manager at the AWS Generative AI Innovation Center. With over a decade of experience in ML and NLP, he has worked with large organizations from diverse industries to solve business problems with innovative AI solutions, and bridge the gap between research and industry applications.
Rifat Jafreen is a Generative AI Strategist in the AWS Generative AI Innovation center where her focus is to help customers realize business value and operational efficiency by using generative AI. She has worked in industries across telecom, finance, healthcare and energy; and onboarded machine learning workloads for numerous customers. Rifat is also very involved in MLOps, FMOps and Responsible AI.
Henry Wang is a senior applied scientist at the AWS Generative AI Innovation Center, where he researches and builds generative AI solutions for AWS customers. His interest in adapting multimodal LLMs and building agentic workflows across custom domains. During his spare time, he likes to play tennis and golf.
Vladimir Turzhitsky is a Director of Data Science and Outcomes research at MSD. He received a Ph.D. degree from Northwestern University and obtained postdoctoral training at Harvard Medical School, where he later served as faculty researching algorithms and devices for cancer and other disease prediction. He joined Merck Research Laboratories in 2018, where his focus has been on applying data science methods for observational studies in healthcare.
Varun Kumar Nomula is Principal AI/ML Engineer consultant for MSD, specializing in Generative AI, Cloud computing, and Data Science. He is passionate about leveraging cutting-edge technology to solve real-world challenges and creating impactful AI-driven solutions. Varun is also a published author of several books and research papers in the fields of AI and Healthcare, contributing to the academic and professional community.
Yezhou Sun is a data scientist and outcome researcher, and associate director at MSD. His works focus on real world evidence generation for market access and reimbursement, and the application of advanced analytics and AI/ML methods in outcome research. Prior to MSD, he was senior principal engineer at UnitedHealth Group/Optum, building AI/ML solutions for risk stratification and business process automation.
{kind=link}
{kind=link}