This post is co-authored with Philipp Pavlov, Dmytro Romantsov, Evgeny Mironenko, and Gowri Suryanarayana from Miro.
Miro is an AI-powered innovation workspace that serves over 95 million users globally, helping teams transform unstructured ideas into organized workflows. To support this scale and continue enhancing their system, Miro’s developer experience team decided to create an innovation workspace for Miro itself, using modern technologies to boost developer productivity. One of the key challenges faced by the team is efficiently routing software bugs to the responsible teams. Quick and accurate bug routing removes unnecessary context-switching, reduces developer frustration, improves time-to-resolution, and ultimately leads to a better product and happier customers. At Miro, a significant percentage of bugs miss internal resolution SLAs primarily due to misrouting and repeated reassignments between teams. This issue results in an estimated 42 years of cumulative lost productivity annually from delays and redundant investigation efforts. To tackle this problem, Miro partnered with the AWS Prototyping and Cloud Engineering (PACE) team to develop BugManager, an AI-powered solution for automated bug triaging.
In this post, we dive deep into the architecture and techniques we used to improve Miro’s bug routing, achieving six times fewer team reassignments and five times shorter time-to-resolution powered by Amazon Bedrock.
Challenge: Accurately routing bug reports to approximately 100 software teams
Automating bug triaging in modern software environments is complex. Bug reports are often messy, lack context, and contain diverse data including text, stack traces, screenshots, and even videos. The complexity multiplies in software-focused companies with many teams, creating a multi-class classification problem with numerous possible labels. Miro’s engineering organization consists of nearly 100 teams, each responsible for specific product aspects.High-accuracy bug classification requires augmenting reports with relevant product information from various sources, including GitHub pull requests, Confluence documentation, README files, and previously resolved tickets. Additionally, organizational structures are dynamic—teams merge, new teams form, and products evolve, continuously changing team responsibilities. The same holds true for software features that are added, updated, or deprecated.Traditional natural language processing (NLP) based text classifiers, such as fine-tuned BERT models or fine-tuned large language model (LLM) classifiers, face severe limitations in these dynamic environments. They require retraining when organizational changes occur and depend on labeled data that might not exist for new structures. Miro experienced quickly degrading performance with an existing solution based on a fine-tuned GPT model.Recognizing these challenges, Miro opted for an LLM-powered approach that combines optimized prompts for team classification with Retrieval Augmented Generation (RAG) for context retrieval, creating a more adaptable, zero-training, and higher-accuracy bug triaging solution: BugManager.
BugManager: RAG-based bug triaging powered by Amazon Bedrock
BugManager adopts an LLM-powered approach to bug classification. When a new bug report is received, the BugManager classification system takes action. BugManager first parses non-text data such as screenshots or screen recordings using the multimodal image and video understanding capabilities of Amazon Nova Pro. The system then enriches the parsed report with important context from several knowledge bases (using Amazon Bedrock Knowledge Bases) with RAG. These knowledge bases contain, for example, previously resolved Jira issues, GitHub pull requests, Confluence documentation, and GitHub READMEs. Using Anthropic’s Claude Sonnet 4 on Amazon Bedrock, the system combines the enriched bug descriptions along with detailed textual information on each team and their responsibilities into a single, optimized classification prompt that performs the routing to the correct team. As an optional feature, the system can also generate a detailed root cause analysis, using the collected information in combination with retrieval of relevant source code repositories to provide deeper insights into the issue and offer hypotheses on how to resolve them.
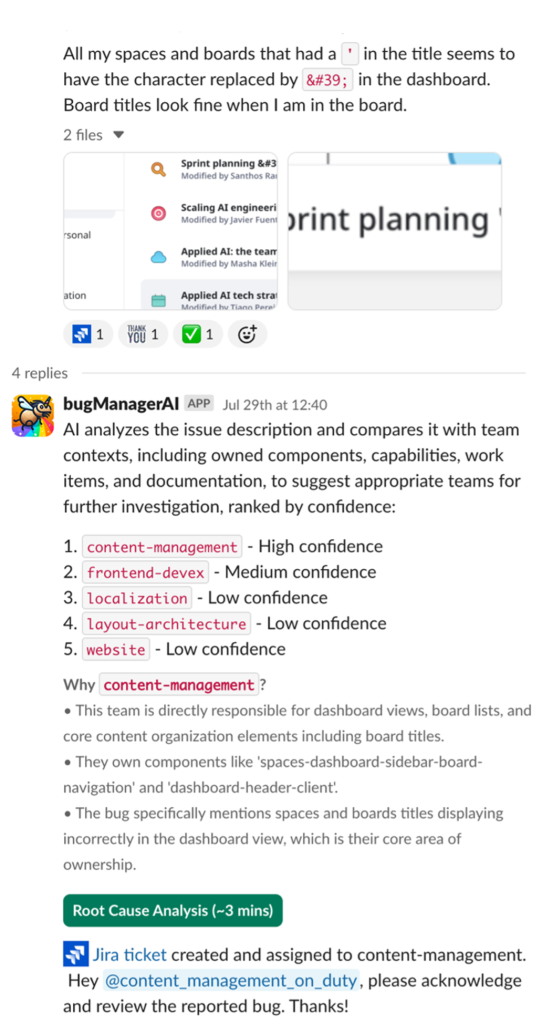
To enable frictionless adoption and use, BugManager is exposed to the Miro Engineering community through a simple Slack-based workflow. The following screenshot shows an example of a user interaction with BugManager. Based on the initial description of the bug, BugManager proposes up to five suitable teams (in order of priority) along with a rationale. By default, the bug is routed to the most likely team, but users can manually overwrite this selection. Optionally, BugManager also provides engineers with a root cause analysis of the reported bug, drawing on information retrieved from the full Miro code base.
In the following sections, we dive into the BugManager architecture.
Architecture deep dive
BugManager primarily uses Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies through a single API. With Amazon Bedrock Knowledge Bases, Anthropic’s Claude Sonnet 4, and Amazon Nova Pro on Amazon Bedrock, we developed an end-to-end workflow that converts a bug description posted in Slack to an issue created in Jira and assigned to a team for resolution.
BugManager runs as a Python microservice in an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The architecture and application flow is depicted in the following diagram.
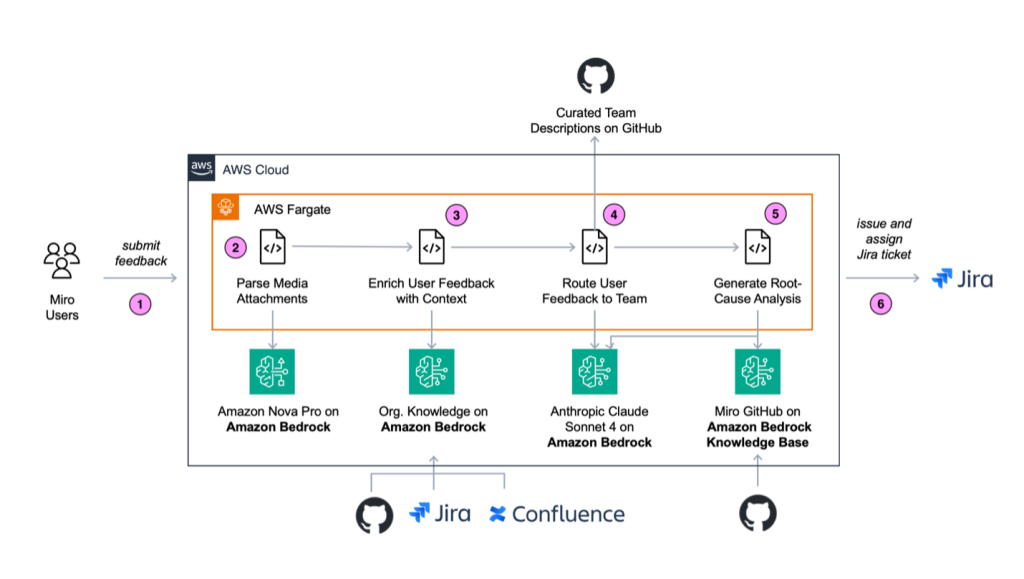
The BugManager workflow consists of the following steps:
- Submit user feedback report.
- Parse media attachments.
- Enrich user feedback with context.
- Route user feedback to the correct team.
- Generate root cause analysis.
- Return results to user for review.
In the following sections, we explore these steps in more detail.
Step 1: Submit user feedback report
A user posts a feedback report (for example, of a bug) into a dedicated Slack channel. The report might contain text and media attachments. Media attachments might include a video (typically a screen recording) that describes the process to reproduce the bug, a screenshot that depicts the bug, or a screenshot of a product page for feature enhancement. The bug report is delivered as a JSON object, which includes the content (text) and the link to the attachments deposited in Amazon Simple Storage Service (Amazon S3).
Step 2: Parse media attachments
If the message contains media attachments, these must be parsed to text to enable bug analysis and classification in a single modality (text) in later steps. We use the image understanding capabilities of Amazon Nova Pro to parse the media attachment description as text. One challenge with this approach is that the LLM isn’t context-aware by default; it lacks information about the type of image (typically a screenshot of the Miro product) to interpret it in a specific and useful way. Therefore, to supply the required context, we first run RAG based on the bug text to supplement our prompt with information about the specific feature likely depicted in the media asset. Our RAG approach uses Amazon Bedrock Knowledge Bases to automatically fetch data from Miro’s internal product documentation. This meaningfully improves specificity of the extracted information from the attachment. After it’s parsed, the text description of the media attachment is appended to the original bug text and passed on to the next step in the application workflow.
Step 3: Enrich user feedback with context
We used Amazon Bedrock Knowledge Bases to automatically fetch data from various sources and provide the FMs with contextual information from a wide range of Miro internal and external data sources. Amazon Bedrock Knowledge Bases is a fully managed capability with built-in session context management and source attribution that helps you implement the entire RAG workflow—from ingestion to retrieval and prompt augmentation—without having to build custom integrations to data sources and manage data flows. More specifically, we used the Amazon S3 and Confluence connector as data sources. We configured Amazon OpenSearch Serverless, the on-demand serverless option of Amazon OpenSearch Service, as a vector store. We indexed the following data sources in the knowledge base: Confluence documentation, Miro help center articles, resolved Jira tickets, GitHub READMEs, and Backstage documents (technical documentation and the software catalog). Amazon Bedrock Knowledge Bases supports incremental re-syncs, which makes it straightforward to keep the knowledge base up to date with documentation changes in a cost-effective manner (only modified documents are re-imbedded and re-indexed).
Step 4: Route user feedback to the correct team
With the help of Amazon Bedrock and Anthropic’s Claude Sonnet 4, we routed the bug to the responsible team. The context given to the LLM to do the correct classification consists of the enriched bug description, the enriched attachment description, if the attachment is available, and the team descriptions that are centrally curated and versioned in Backstage (backed by GitHub). Team descriptions are living documents that can be updated whenever necessary. Miro’s product and engineering organization are dynamic constructs. Product features are added or deprecated, and team responsibilities change. Given BugManager’s prompt-based approach, such updates can be incorporated with relative ease by simply updating the respective team descriptions (a markdown file written in English). Changes are propagated immediately. The following is a simplified version of the prompt we used for bug-to-team classification. Note the use of <xml> tags in the output, which allows robust parsing of outputs.
BugManager achieves a top-1 accuracy for bug-to-team routing of over 75% (a 70% increase vs. an existing internal solution based on a fine-tuned NLP model). Average classification latency is 53 seconds, which proved practical when deployed in production. BugManager returns up to five likely team options (ranked by confidence, exact number is configurable). Top-3 accuracy is 95%, which—when paired with a human-in-the-loop approach—has been proven to boost triaging accuracy further. These results were made possible through Anthropic’s Claude’s extended thinking, which resulted in additional accuracy gains of 7–9%.
For each classification, the solution also provides a comprehensive rationale for why a certain routing decision was made. This significantly improved user acceptance and trust vs. the fine-tuned NLP solution that only returned a single team without further explanation.
Step 5: Generate root cause analysis
BugManager can optionally generate a root cause analysis of the bug. Again, we provide the necessary context to run such an analysis using Amazon Bedrock Knowledge Bases, this time drawing on the entire Miro GitHub code base for reference. During root cause analysis, we provide the LLM (Anthropic’s Claude Sonnet 4 with extended thinking enabled) with the bug description, the previously retrieved context, and the selected software team to resolve the bug. The LLM then retrieves the respective code sections using Amazon Bedrock Knowledge Bases and generates a set of hypotheses for the root cause of the observed bug. In doing so, it relieves software engineers of the required research work necessary to identify a course for action.
Step 6: Return results to user for review
The result of the classification and root cause analysis (optional) is sent to Slack as a response to the initial message posted. Users can review the routing results and make changes to the default choice if needed. After that, a Jira ticket with the original bug description and supporting documentation retrieved from the knowledge bases as well as the results for the root cause analysis is cut and assigned to the selected team.
Conclusion
BugManager boasts several key features that make it a highly capable bug triaging solution powered by Amazon Bedrock that has been adopted with significant success across Miro’s engineering org. These key features include:
- High-accuracy first-try bug-to-team routing
- Further performance boosts through multi-class prediction enabling human-in-the-loop decision-making
- Transparent routing decisions that drive user acceptance
- Bug root cause analysis to accelerate resolution
- Augmentation with continuously refreshed organizational knowledge
- Robustness and flexibility to changes in team responsibilities
BugManager has successfully routed thousands of bugs and support requests in production, delivering exceptional results for Miro’s development workflow. The system has achieved a six-fold reduction in team reassignments for customer support requests and a five-fold improvement in median time-to-resolution, transforming what once took days into an hours-long processes. BugManager is projected to save years of cumulative waiting and investigation time annually, ultimately delivering a significantly better Miro product experience.
To get started building your own feedback routing system today, explore the AWS generative AI resources and sample architectures at Generative AI on AWS, where you can find step-by-step guides, reference implementations, and best practices to accelerate your journey toward AI-powered operational efficiency.
About the authors

