Amazon Bedrock Custom Model Import now supports OpenAI models with open weights, including GPT-OSS variants with 20-billion and 120-billion parameters. GPT-OSS models offer reasoning capabilities and can be used with OpenAI Chat Completions API. By preserving full OpenAI API compatibility, organizations can migrate their existing applications to AWS, gaining enterprise-grade security, scaling, and cost control.
In this post, we show how to deploy the GPT-OSS-20B model on Amazon Bedrock using Custom Model Import while maintaining complete API compatibility with your current applications.
Overview of Amazon Bedrock Custom Model Import
Amazon Bedrock Custom Model Import lets you bring customized models into the same serverless environment where you access foundation models (FMs). You get one unified API for everything; you don’t need to juggle multiple endpoints or manage separate infrastructure.
To use this feature, upload your model files to Amazon Simple Storage Service (Amazon S3), then initiate the import through the Amazon Bedrock console. AWS handles the heavy lifting, including provisioning GPUs, configuring inference servers, and scaling automatically based on demand. You can focus on your applications while AWS manages the infrastructure.
GPT-OSS models support the OpenAI Chat Completion API, including message arrays, role definitions (system, user, or assistant), and standard response structures with token usage metrics. You can point your applications to Amazon Bedrock endpoints, and they will work with minimal changes to your code base.
Overview of GPT-OSS models
GPT-OSS models are OpenAI’s first open-weight language models since GPT-2, released under the Apache 2.0 license. You can download, modify, and use them at no additional cost, including for commercial applications. These models focus on reasoning, tool use, and efficient deployment.Choose the right model for your needs:
- GPT-OSS-20B (21 billion parameters) – This model is ideal for applications where speed and efficiency matter most. Despite having 21 billion parameters, it only activates 3.6 billion per token, so it runs smoothly on edge devices with just 16 GB of memory. With 24 layers, 32 experts (4 active per token), and a 128k context window, it matches OpenAI’s o3-mini performance while being able to deploy locally for faster response times.
- GPT-OSS-120B (117 billion parameters) – Built for complex reasoning tasks like coding, mathematics, and agentic tool use, it activates 5.1 billion parameters per token. With 36 layers, 128 experts (4 active per token), and a 128k context window, it matches OpenAI’s o4-mini performance while running efficiently on a single 80GB GPU.
Both models use a mixture-of-experts (MoE) architecture—subsets of the model’s components (experts) handle different types of tasks, with only the most relevant experts activated for each request. This approach gives you powerful performance while keeping computational costs manageable.
Understanding the GPT-OSS model format
When you download GPT-OSS models from Hugging Face, you get several file types that work together:
- Weight files (.safetensors) – The actual model parameters
- Configuration files (config.json) – Settings that define how the model works
- Tokenizer files – Handle text processing
- Index file (model.safetensors.index.json) – Maps weight data to specific files
The index file needs a specific structure to work with Amazon Bedrock. It must include a metadata field at the root level. This can be empty ({}) or contain the total model size (which must be under 200 GB for text models).
Models from Hugging Face sometimes include extra metadata fields like total_parameters that Amazon Bedrock doesn’t support. You must remove these before importing. The correct structure should look like the following code:
Make sure you exclude the metal directory before initiating the Amazon S3 upload.
Solution overview
In this post, we walk through the complete deployment process using Amazon Bedrock Custom Model Import. We use the Tonic/med-gpt-oss-20b model, a fine-tuned version of OpenAI’s GPT-OSS-20B specifically optimized for medical reasoning and instruction following.
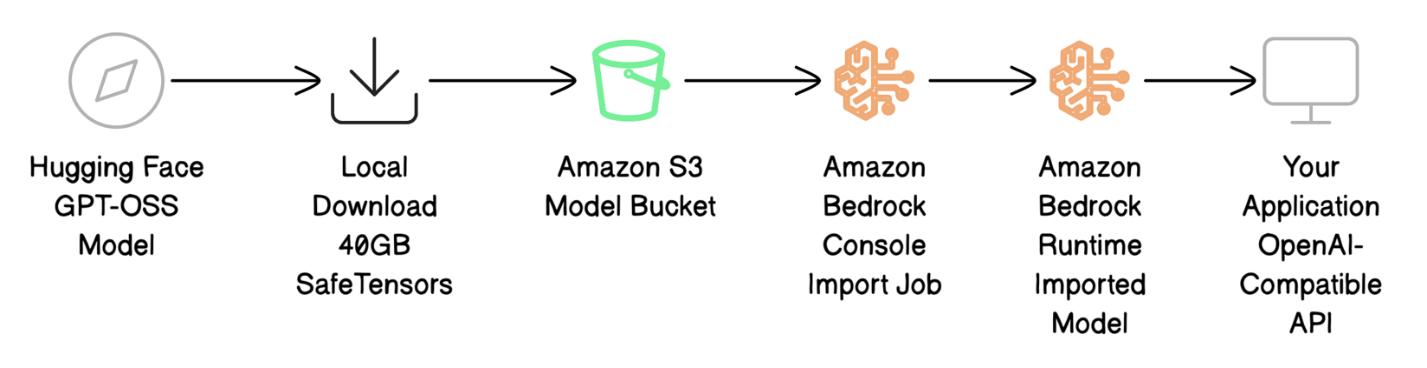
The deployment process involves four main steps:
- Download the model files from Hugging Face and prepare them for AWS.
- Upload the model files to Amazon S3.
- Import using Amazon Bedrock Custom Model Import to bring your model into Amazon Bedrock.
- Invoke your model with OpenAI-compatible API calls to test your deployment.
The following diagram illustrates the deployment workflow.
Prerequisites
Before you start deploying your GPT-OSS model, make sure you have the following:
- An active AWS account with appropriate permissions
- AWS Identity and Access Management (IAM) permissions to:
- Create model import jobs in Amazon Bedrock
- Upload files to Amazon S3
- Invoke models after deployment
- Use the Custom Model Import service role
- An S3 bucket in your target AWS Region
- Approximately 40 GB of local disk space for model download
- Access to the US East 1 (N. Virginia) Region (required for GPT-OSS based custom models)
- The AWS Command Line Interface (AWS CLI) version 2.x installed
- The Hugging Face CLI (install with
pip install -U "huggingface_hub[cli]")
Download and prepare model files
To download the GPT-OSS model using the Hugging Face Hub library with fast transfer enabled, use the following code:
After the download is complete (10–20 minutes for 40 GB), verify the model.safetensors.index.json file structure. Edit it if needed to make sure the metadata field exists (they can be empty):
Upload model files to Amazon S3
Before you can import your model, you must store the model files in an S3 bucket where Amazon Bedrock can access them. Complete the following steps:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Create a new bucket or open an existing one.
- Upload your model files.
Alternatively, upload the files to an S3 bucket in your target Amazon Bedrock Region using the AWS CLI:
The 40 GB upload typically completes in 5–10 minutes. Verify files are uploaded:
The following screenshot shows an example of the files in the S3 bucket.

Note your S3 URI (for example, s3://amzn-s3-demo-bucket/med-gpt-oss-20b/) to use for the import job.
The output files are encrypted with the encryption configurations of the S3 bucket. These are encrypted either with SSE-S3 server-side encryption or with AWS Key Management Service (AWS KMS) SSE-KMS encryption, depending on how you set up the S3 bucket.
Import model using Amazon Bedrock Custom Import
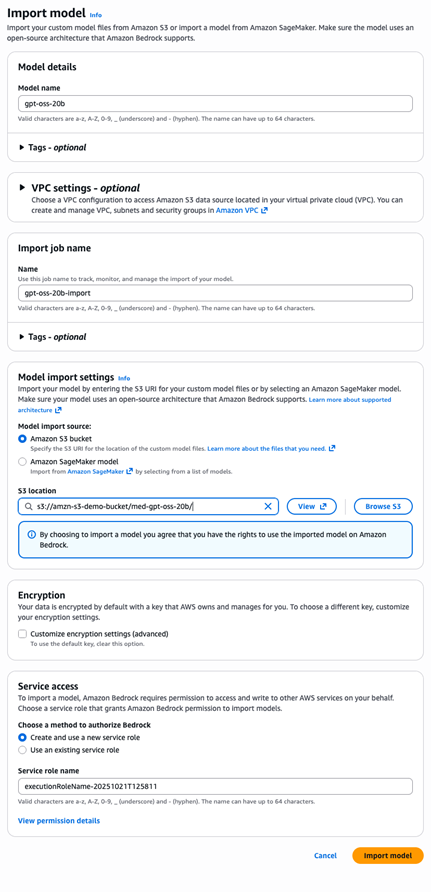
Now that your model files are uploaded to Amazon S3, you can import the model into Amazon Bedrock, where it will be processed and made available for inference. Complete the following steps:
- On the Amazon Bedrock console, choose Imported models in the navigation pane.
- Choose Import model.
- For Model name, enter
gpt-oss-20b. - For Model import source, select Amazon S3 bucket.
- For S3 location, enter
s3://amzn-s3-demo-bucket/med-gpt-oss-20b/. - For Service access, select Create and use a new service role. Amazon Bedrock console automatically generates a role with the correct trust relationship and Amazon S3 read permissions.
- Choose Import model to start the import job.
To use the AWS CLI, use the following code:
The model import typically completes in 10–15 minutes for a 20B parameter model. You can monitor progress on the Amazon Bedrock console or using the AWS CLI. Upon completion, note your importedModelArn, which you use to invoke the model.
Invoke model with OpenAI-compatible API
After your model import is complete, you can test it using the familiar OpenAI Chat Completions API format to verify it’s working as expected:
- Create a file named
test-request.jsonwith the following content:
- Use the AWS CLI to send the request to your imported model endpoint:
The response returns in standard OpenAI format:
The response structure matches OpenAI’s format exactly—choices contains the response, usage provides token counts, and finish_reason indicates completion status. The existing OpenAI response parsing code works without modification.
A powerful advantage of this model is its transparency. The reasoning_content field gives us information about the model’s internal reasoning process before it generates the final response. This level of transparency is not available with closed-source APIs.
Clean up
When you’re finished, clean up your resources to avoid unnecessary charges:
If you no longer need the IAM role, delete it using the IAM console.
Migrate from OpenAI to Amazon Bedrock
Migrating from OpenAI requires minimal code changes—only the invocation method changes while message structures remain identical.
For OpenAI, use the following code:
For Amazon Bedrock, use the following code:
Migration is straightforward, and you will gain predictable costs, better data privacy, and the ability to fine-tune models for your specific needs.
Best practices
Consider the following best practices:
- File validation – Before uploading, verify
model.safetensors.index.jsonhas the correct metadata structure, the referenced safetensors files exist, and tokenizers are supported. Local validation saves import retry time. - Security – On the Amazon Bedrock console, create IAM roles automatically with least-privilege permissions. For multiple models, use separate S3 prefixes to maintain isolation.
- Versioning – Use descriptive S3 paths (
gpt-oss-20b-v1.0/) or dated import job names for tracking deployments.
Pricing
You are charged for running inference with custom models that you import into Amazon Bedrock. For more details, see Calculate the cost of running a custom model and Amazon Bedrock pricing.
Conclusion
In this post, we showed how to deploy GPT-OSS models on Amazon Bedrock using Custom Model Import while maintaining full OpenAI API compatibility. You can now migrate your existing applications to AWS with minimal code changes and gain enterprise benefits, including complete model control, fine-tuning capabilities, predictable pricing, and enhanced data privacy.
Ready to get started? Here are your next steps:
- Choose your model size – Start with the 20B model for faster responses, or use the 120B variant for complex reasoning tasks
- Set up your environment – Make sure you have the required AWS permissions and S3 bucket access
- Try the Amazon Bedrock console – Import your first GPT-OSS model using the Amazon Bedrock console
- Explore advanced features – Consider fine-tuning with your proprietary data after your basic setup is working
Amazon Bedrock Custom Model Import is available in multiple Regions, with support expanding to additional Regions soon. Refer to Feature support by AWS Region in Amazon Bedrock for the latest updates. GPT-OSS models will initially be available in the US-East-1 (N. Virginia) Region.
Have questions or feedback? Connect with our team through AWS re:Post for Amazon Bedrock—we’d love to hear about your experience.
About the authors
 Prashant Patel is a Senior Software Development Engineer in AWS Bedrock. He’s passionate about scaling large language models for enterprise applications. Prior to joining AWS, he worked at IBM on productionizing large-scale AI/ML workloads on Kubernetes. Prashant has a master’s degree from NYU Tandon School of Engineering. While not at work, he enjoys traveling and playing with his dogs.
Prashant Patel is a Senior Software Development Engineer in AWS Bedrock. He’s passionate about scaling large language models for enterprise applications. Prior to joining AWS, he worked at IBM on productionizing large-scale AI/ML workloads on Kubernetes. Prashant has a master’s degree from NYU Tandon School of Engineering. While not at work, he enjoys traveling and playing with his dogs.
 Ainesh Sootha is a Software Development Engineer at AWS. He’s passionate about performance optimization and scaling large language models for enterprise applications. Prior to joining AWS Bedrock, he worked on authentication systems for Amazon’s Just Walk Out Technology. Ainesh has a bachelor’s degree in computer engineering from Purdue University. While not at work, he enjoys playing guitar and reading books.
Ainesh Sootha is a Software Development Engineer at AWS. He’s passionate about performance optimization and scaling large language models for enterprise applications. Prior to joining AWS Bedrock, he worked on authentication systems for Amazon’s Just Walk Out Technology. Ainesh has a bachelor’s degree in computer engineering from Purdue University. While not at work, he enjoys playing guitar and reading books.
 Sandeep Akhouri is an experienced Product and Go-To-Market (GTM) leader with over 20 years of experience in Product Management, Engineering, and Go-To-Market. Prior to his current role, Sandeep led product management building AI/ML products at leading technology companies, including Splunk, KX Systems, Hazelcast and Software AG. He is passionate about agentic AI, model customization and driving real-world impact with Generative AI.
Sandeep Akhouri is an experienced Product and Go-To-Market (GTM) leader with over 20 years of experience in Product Management, Engineering, and Go-To-Market. Prior to his current role, Sandeep led product management building AI/ML products at leading technology companies, including Splunk, KX Systems, Hazelcast and Software AG. He is passionate about agentic AI, model customization and driving real-world impact with Generative AI.