This post is co-written with Abhinav Pandey from Nippon Life India Asset Management Ltd.
Accurate information retrieval through generative AI-powered assistants is a popular use case for enterprises. To reduce hallucination and improve overall accuracy, Retrieval Augmented Generation (RAG) remains the most commonly used method to retrieve reliable and accurate responses that use enterprise data when responding to user queries. RAG is used for use cases such as AI assistants, search, real-time insights, and improving overall content quality by using the relevant data to generate the response, thereby reducing hallucinations.
Amazon Bedrock Knowledge Bases provides a managed RAG experience that can be used for many use cases. Amazon Bedrock Knowledge Bases is a fully managed service that does the heavy lifting of implementing a RAG pattern—including data ingestion, data chunking, data embedding, and query matching. Amazon Bedrock offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Using Amazon Bedrock Knowledge Bases, you can create a RAG solution quickly and seamlessly.
However, in a large enterprise scenario with a large number of relevant documents, the final response is generated based on only the top 5 or top 10 results provided by the database. Because RAG uses a similarity match and not an exact match, there is a possibility that the most relevant result won’t be in the top results returned by the database. In such scenarios, the regular RAG pattern might not be highly accurate.
In this post, we examine a solution adopted by Nippon Life India Asset Management Limited that improves the accuracy of the response over a regular (naive) RAG approach by rewriting the user queries and aggregating and reranking the responses. The proposed solution uses enhanced RAG methods such as reranking to improve the overall accuracy.
Limitations and workarounds in naive RAG for a large volume of documents
The following are the primary limitations with naive RAG when using it with a large volume of documents:
- Accuracy – As the documents grow in number or size, the final list of extracted chunks might miss some relevant sections or documents because of the limited number of documents returned
- Parsing complex structures – Entities such as nested tables, images, and graphs are not parsed accurately
- Limited use of relevant data – As the dataset grows, only the configured set of top results are used for context, impacting accuracy
- Responding to complex questions – Compound questions (such as a question with multiple sub-questions) pose challenges to the RAG solution
- Retrieving the correct context – Documents such as legal documents or technical manuals have semantically related sections on different pages, impacting the overall accuracy
- Avoiding hallucinations – Models must generate complete, correct, and grounded responses without hallucinations
To address these challenges, developers usually adopt a combination of the following workarounds:
- Programmatic parsing – Use another service (such as Amazon Textract) to extract the table content into a markdown (
.MD) file. - Programmatic split of compound questions – Programmatically split the question or reformulate the question and get the responses and then programmatically aggregate the response.
- Programmatic chunking – Programmatically create custom chunks of the documents and manage them in a vector store.
Solution overview
In this section, we review the basics of RAG, Amazon Bedrock Knowledge Bases, and advanced RAG methods to address the preceding challenges. The following table details the specific solution components adopted by Nippon to overcome the challenges we discussed in the previous section.
| Naive RAG Challenges | How Nippon Addressed These Challenges |
| Lower accuracy due to high volume of documents | Use Amazon Bedrock Knowledge Bases with advanced RAG methods, including semantic chunking, multi-query RAG, and results reranking |
| Parsing complex document structure such as nested tables and graphs within documents | Use Amazon Textract to parse the documents into markdown files |
| Handling compound questions | Use query reformulation and results reranking to get the relevant results |
| Retrieving current context from the documents | Use semantic chunking in Amazon Bedrock Knowledge Bases |
| Generating grounded responses without any hallucination | Use Amazon Bedrock Knowledge Bases RAG evaluation |
In the next few sections, we detail each of the solution components. We start with an overview of RAG and then discuss Amazon Bedrock Knowledge Bases. We then discuss advanced RAG methods adopted by Nippon, including advanced parsing, query reformulation, multi-query RAG, and results reranking.
RAG overview
The RAG pattern for this solution has two primary workflows: a data ingestion workflow and a text generation phase, as depicted in the following figure. During the ingestion phase, the solution chunks the content of the source documents, creates embeddings for the created chunks, and stores them in a vector database. In the text generation workflow, the user query is converted to a vector embedding and the query embedding is compared with embeddings stored in the vector database. The database provides the top results that are close to the user query. The solution then sends the user query along with the retrieved top results as the context to the FM, which then provides the final response. Because the responses are based on the relevant contextual enterprise data, this solution reduces hallucinations.
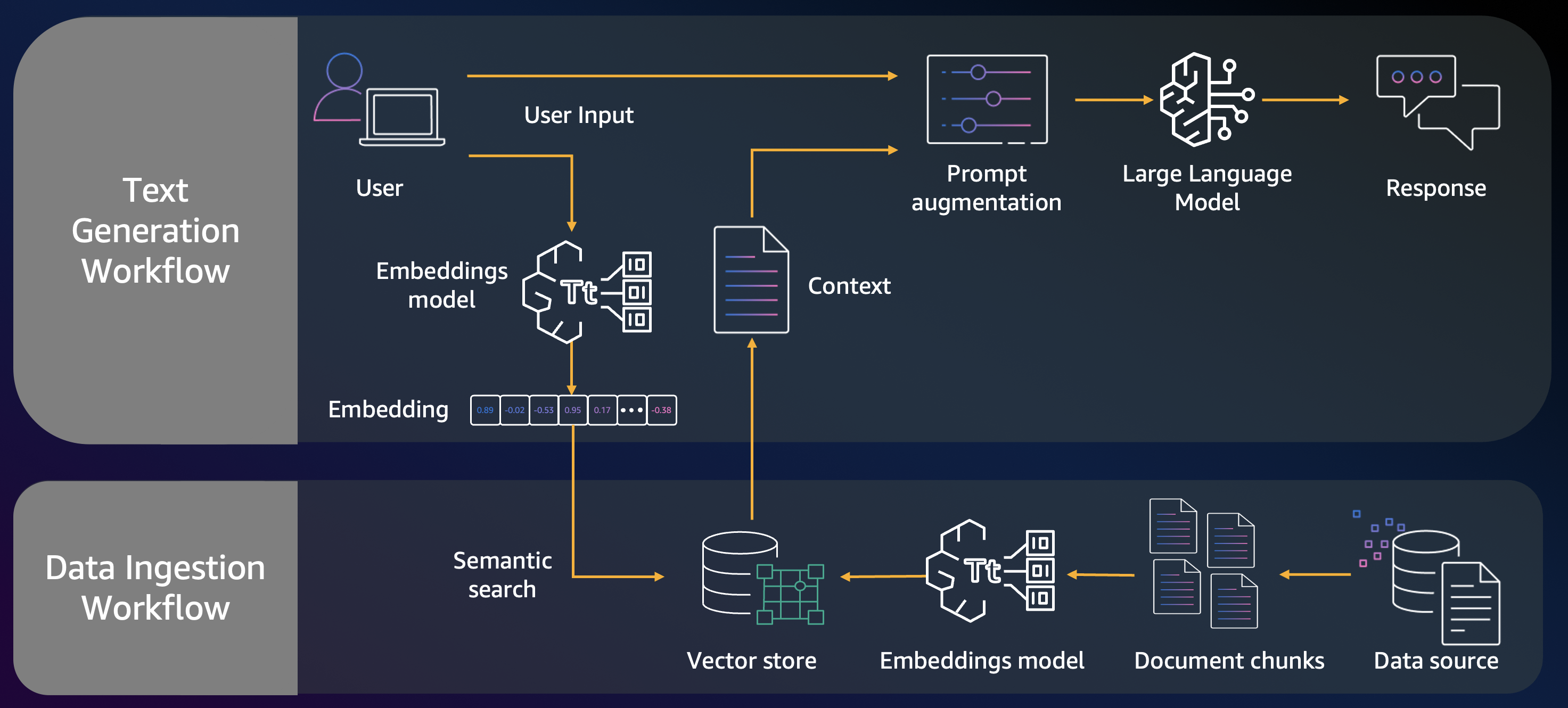
Ingestion & Text generation workflows
You can implement this solution using AWS services as shown in the following figure.
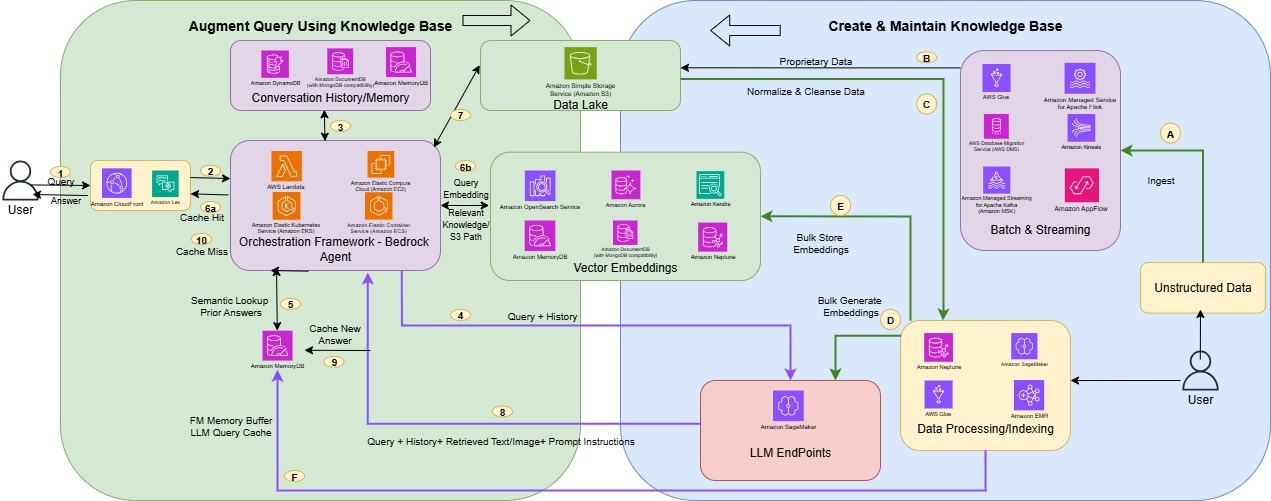
RAG implementation using AWS services
The following is a typical RAG-based AI assistant flow.The first series of steps, as numbered in the preceding diagram, augment the user query using a knowledge base:
- User queries are served by Amazon Lex hosted on Amazon CloudFront.
- The business logic for the AI assistant can run on Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), or AWS Lambda.
- You can manage the conversation history or state in Amazon DynamoDB, Amazon DocumentDB (with MongoDB compatibility), or Amazon MemoryDB.
- The user query and the earlier conversation history are sent to the Amazon Bedrock embedding model.
- User prompts are compared to earlier prompts cached in MemoryDB. If the user prompt matches a stored prompt, the stored prompt result is retrieved and sent to the user.
- If there’s no match for the user prompt in the cache, the vector database (such as Amazon OpenSearch, Amazon Aurora, Amazon Kendra, MemoryDB, DocumentDB, or Amazon Neptune) is searched for the query embedding. The relevant knowledge or Amazon Simple Storage Service (Amazon S3) path to the relevant image or video is retrieved.
- The relevant knowledge, image, or video is retrieved from the Amazon S3 path.
- The multimodal large language model (LLM) in Amazon Bedrock uses the query results to create a final response.
- The new answer is stored in the database cache.
- The final response is sent to the user.
The workflow to create and maintain the knowledge base is shown in the previous diagram:
- The data is ingested from structured and unstructured sources such as a file system, emails, or multi-media content.
- The data is ingested into Amazon S3 in batches or in real time using services such as AWS Database Migration Service (AWS DMS), Amazon Kinesis, Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon AppFlow, or AWS Glue.
- The data is processed through AWS Glue, Amazon SageMaker processing, or Amazon EMR.
- An embeddings LLM from Amazon Bedrock generates the embeddings for the content chunks.
- The embeddings are stored in the vector database.
Amazon Bedrock Knowledge Bases
Amazon Bedrock Knowledge Bases provides managed RAG, which does the heavy lifting of the core activities in the data ingestion and text generation workflows. Nippon uses Amazon Bedrock Knowledge Bases for implementing the RAG pattern. The following figure shows the fully managed data ingestion workflow provided by Amazon Bedrock Knowledge Bases. You can choose the data source from which data of various formats can be incrementally updated. For content chunking, you can choose from the following strategies: fixed, semantic, or hierarchical. You can also choose the embedding models and vector store.
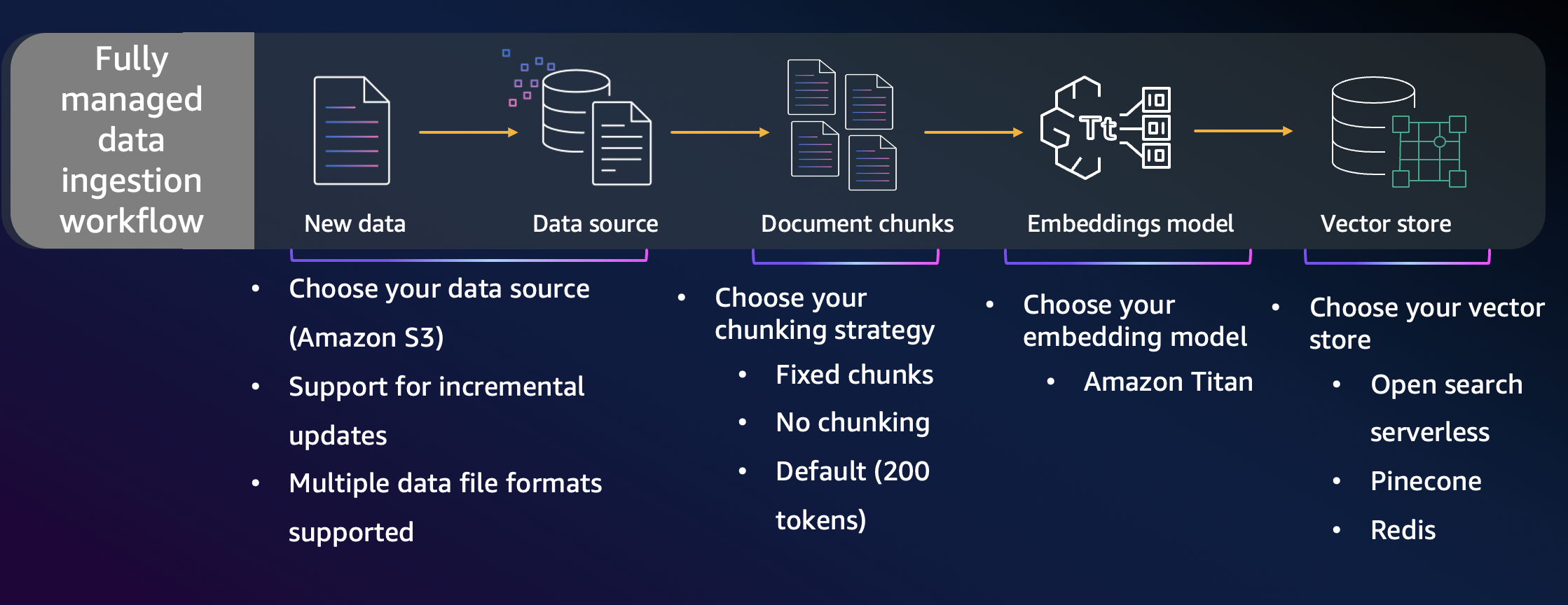
Data ingestion flow
The following table compares various chunking strategies. You can also author a custom chunking strategy using Lambda.
| Chunking strategy | Details | Advantages |
| Fixed chunking |
|
Quick and efficient |
| Semantic chunking (used by Nippon) |
|
Better retrieval quality |
| Hierarchical chunking |
|
Improved retrieval efficiency and reliability |
Nippon uses semantic chunking because the documents have sections with semantic similarity. During the text generation workflow, Amazon Bedrock Knowledge Bases creates embeddings from the user input and performs semantic search in the Amazon Bedrock knowledge base. The retrieved results from the context are augmented with a prompt for the LLM to generate the final response as shown in the following figure.
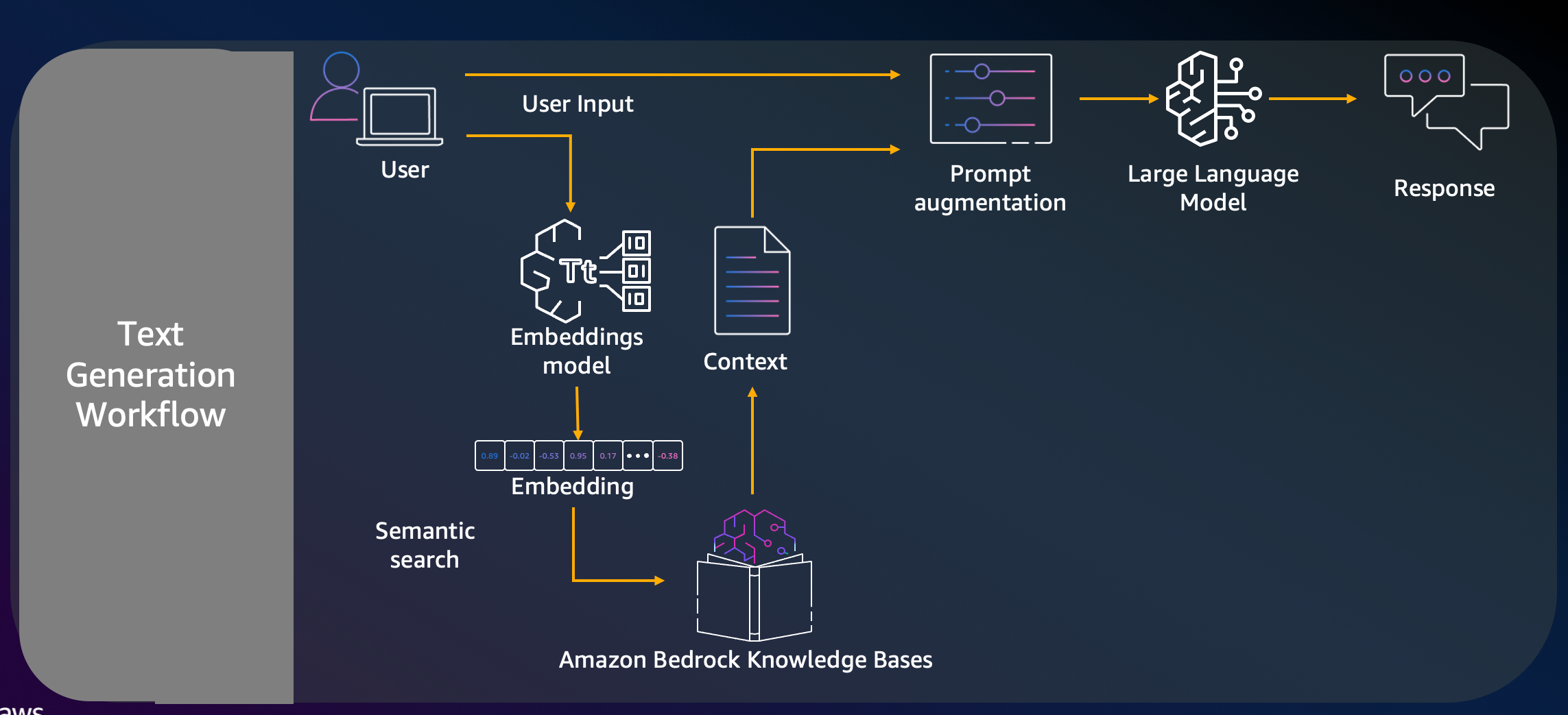
RAG Flow
Advanced RAG methods adopted by Nippon
In this section, we review the key advanced RAG methods used in the Nippon AI assistant solution.
Advanced parsing and chunking
A complex document with tables, images, and graphs poses challenges in RAG because the default fixed chunking often loses the context. For these scenarios, Nippon uses the following approaches:
- Parse the document with Amazon Textract – Nippon uses Amazon Textract—which excels at understanding complex structures like tables—to extract the details from the document into a markdown file (.MD).
- Parse the document with an FM with specific instructions – In this approach, Nippon uses an FM that has specific parsing instructions to extract the details from the document. Amazon Bedrock Knowledge Bases provides LLMs along with instructions for parsing the documents.
- Parse the document using third-party parsers – This approach uses third-party parsers such as open source document parsers and then indexed the parsed content.
After the documents are parsed, Amazon Bedrock Knowledge Bases chunks the data. Amazon Bedrock Knowledge Bases provides fixed chunking, semantic chunking, and hierarchical chunking strategies. You can also add custom chunking using Lambda functions for specific documents.
Query reformulation
If the user queries are complex, the overall accuracy of the RAG solution decreases because it can be difficult to understand all the nuances of the complex question. In such cases, you can split the complex question into multiple sub-questions for improved accuracy. Nippon used an LLM to split the compound query into multiple sub-queries. The search results for each of the sub-queries are returned simultaneously and are then ranked and combined. The LLM uses the combined data to provide the final response, as shown in the following figure.
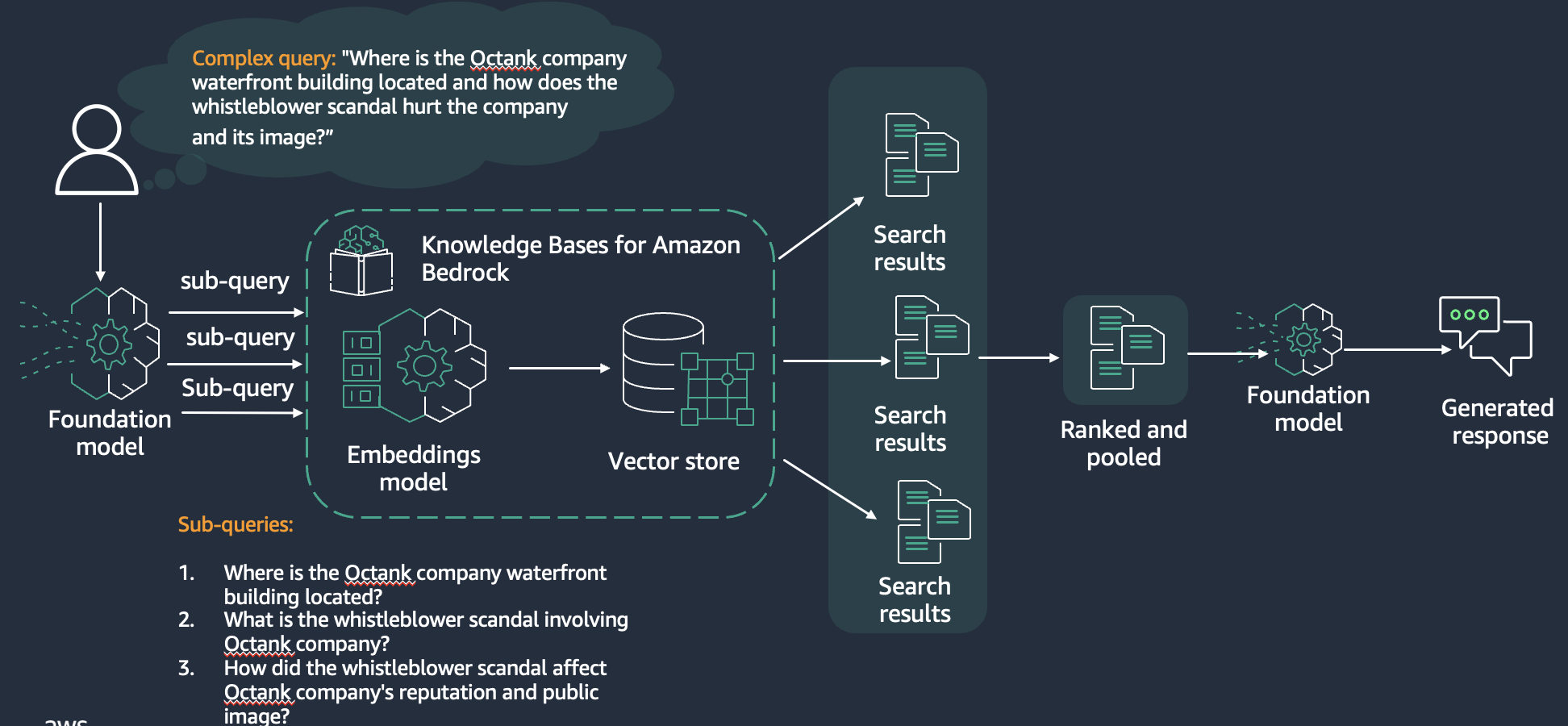
Query reformulation
Multi-query RAG
In the multi-query RAG approach, you can reformulate the question into different variants (Amazon Bedrock Knowledge Bases provides automatic query reformulation) and execute the queries in parallel. You then summarize the results of those queries and rerank them to get the final response as shown in the following figure.
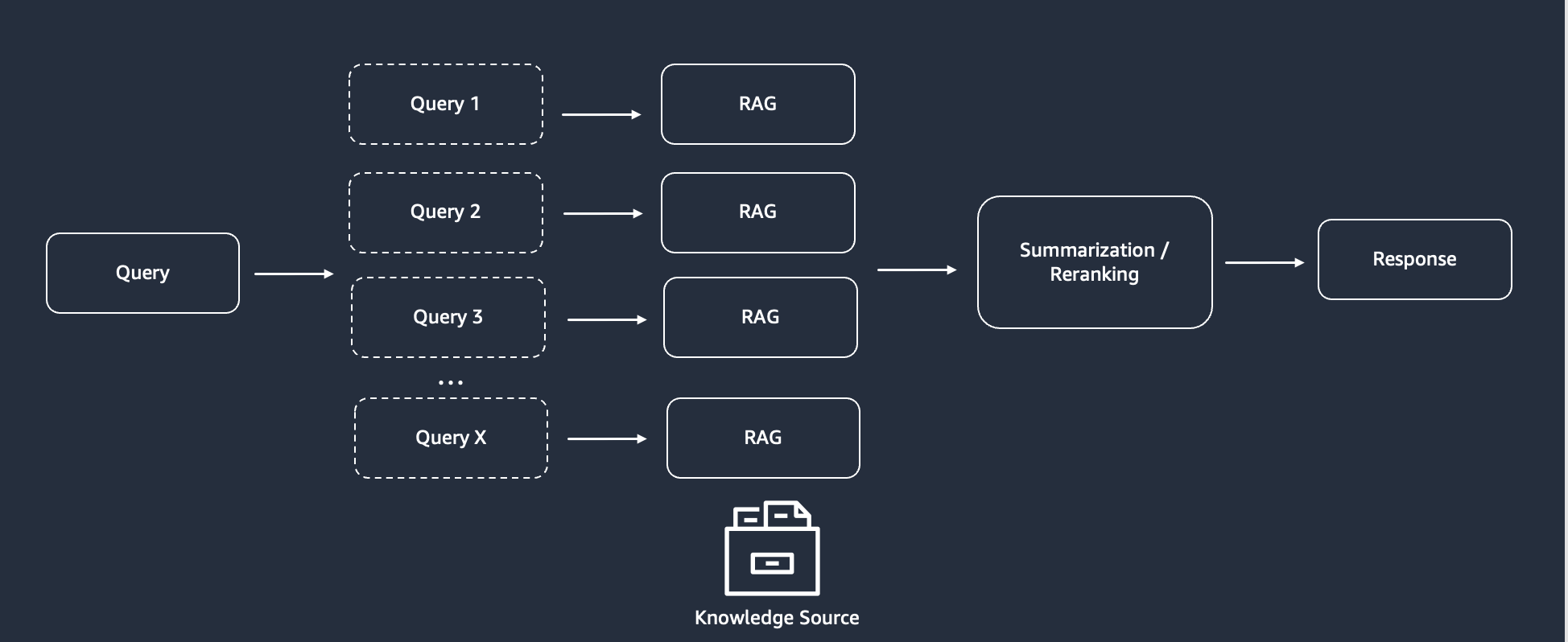
Multi-query RAG
Nippon uses the initial question and break it into n sub-questions using our choice of LLM (Anthropic’s Claude3 Sonnet on Amazon Bedrock). With this implementation, the quality of our responses has improved, and the query is answered in greater depth. Because this requires additional processing, the response time is slightly longer, which is justified by the quality of the response.
Results reranking
In a typical enterprise scenario where you have a large volume of documents, the ranking of the results might not be correct and accuracy could be reduced. For example, the default results returned from a vector database will be based on vector similarity criteria whose rank might not be accurate or relevant based on the user’s conversation history or the query context. In such scenarios, you can use another FM to look closely at the results and reorder them based on analysis of the context, relevance, and other criteria. After the results are reranked, you can be certain that the top results are highly relevant to the user context. Each document or search result is assigned a score based on criteria such as semantic similarity, contextual alignment, or domain-specific features, thereby increasing the overall accuracy of the final response, reducing hallucination, and improving user satisfaction. The key reranker strategies are:
- Cross-encoder reranking – Uses models specifically trained to assess the relevance between query-document pairs
- Hybrid reranking – Combines multiple signals such as vector similarity, keyword matching, recency, and so on
- Multi-stage retrieval – Retrieves a larger set using faster methods, then applies more computationally intensive reranking on a subset
Amazon Bedrock provides reranker models that calculate the relevance of the chunks for a given query, assigns a score for the chunk, and reorders the results based on the score. By using a reranker model in Amazon Bedrock, you can get highly relevant chunks in the search results, improving the overall response accuracy. Nippon has combined query reformulation with results reranking to improve the overall accuracy of the RAG solution using the Amazon Bedrock reranker models.
Metrics for RAG Evaluation
Because RAG solutions have multiple moving parts, you need to evaluate them against key success metrics to make sure that you get relevant and contextual data from the knowledge base. RAG evaluation should validate the generation of complete, correct, and grounded answers without hallucinations. You also need to evaluate the bias, safety, and trust of RAG solutions.
Amazon Bedrock Knowledge Bases provides built-in support for RAG evaluation, including quality metrics such as correctness, completeness, and faithfulness (hallucination detection); responsible AI metrics such as harmfulness, answer refusal, and stereotyping; and compatibility with Amazon Bedrock Guardrails. Nippon used RAG evaluation to compare against multiple evaluation jobs using custom datasets.
Nippon is currently evaluating additional techniques, including GraphRAG, metadata filtering, and agentic AI. We have briefly summarized the capabilities being evaluated at Nippon in the following sections.
GraphRAG
For applications that need to establish relationships with data that are hierarchically related (such as knowledge management, enterprise search, recommendation systems, and so on), Nippon uses a graph database instead of a vector database. GraphRAG applications use rich and interconnected entity relationships to identify the dependencies and excel in querying multi-dimensional relationships that further boost the context for FMs. In addition, with graph databases, Nippon can efficiently query and traverse the data, and their schema enables them to accommodate dynamic content. The graph databases help the FMs better understand the semantic relationship, uncover hidden patterns, adapt to dynamic knowledge bases, and provide better reasonability.
Amazon Bedrock Knowledge Bases supports fully managed GraphRAG, which uses the Amazon Neptune graph database.
Metadata filtering
In a few use cases, you might need to filter the documents in a knowledge base based on specific metadata values. For instance, government regulatory bodies release regulatory guidelines frequently, often with the same document names and only minor variations in the regulatory clauses. When your query is about a specific regulation, you want the most recent document to be returned. In such cases, you can rank the documents based on their modified date. Amazon Bedrock Knowledge Bases provide custom metadata as filters (such as modified date) to improve the quality of search results.
Amazon Bedrock Agents
With Amazon Bedrock Agents, you can orchestrate multi-step business processes using tools and information sources. Nippon is currently evaluating the latest FMs in Amazon Bedrock Agents for their AI assistant use case.
Solution flow
The following diagram shows the end-to-end flow of the Nippon AI assistant solution.
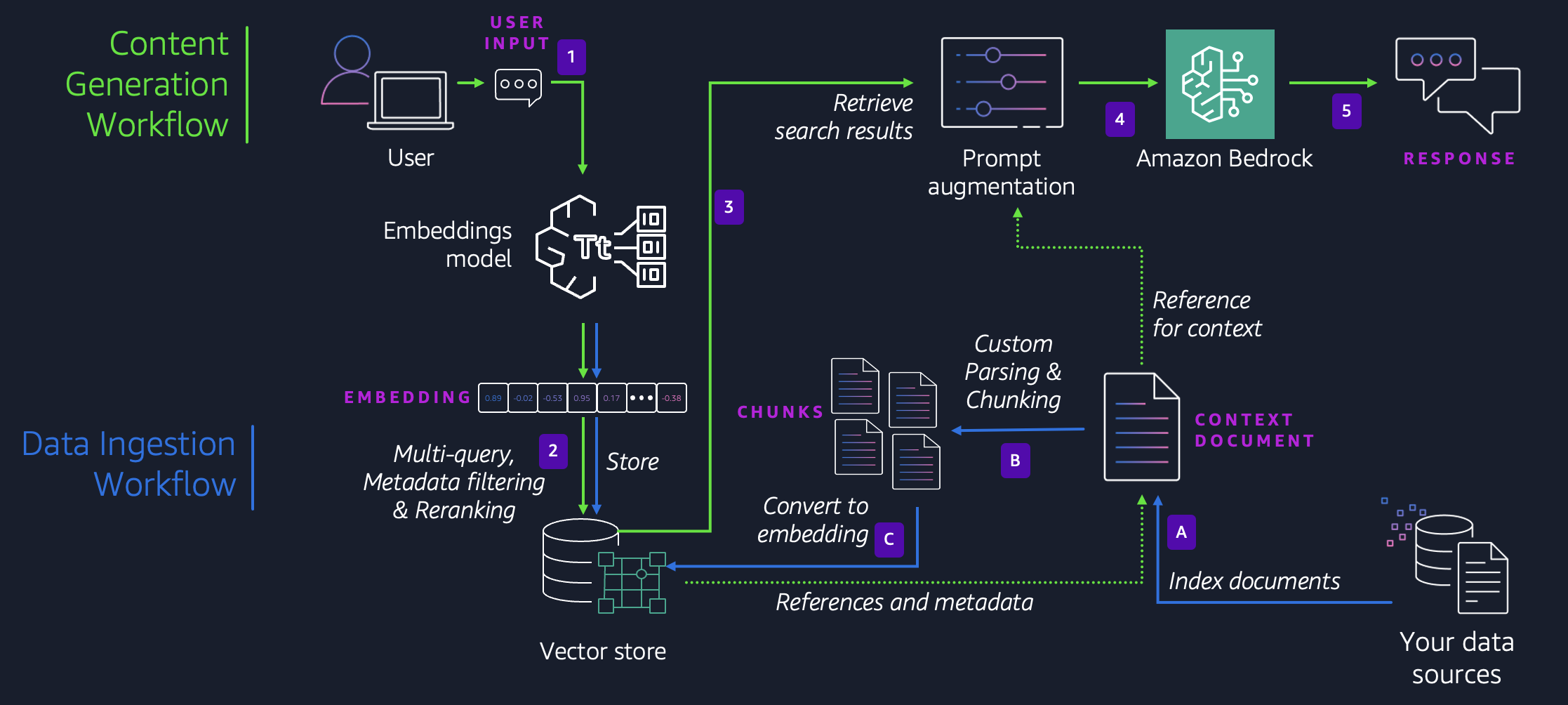
End-to-end flow of the Nippon AI assistant solution
The data ingestion workflow consists of the following steps:
- The documents from the data source are prepared for ingestion.
- Nippon uses custom parsing to extract the relevant details from complex elements like tables, graphs, and images. They use custom chunking to create the chunks.
- They use an embedding model from Amazon Bedrock to convert the content chunks to vector embeddings and store them in the vector database.
The content generation workflow is as follows:
- The user’s query is converted into embeddings by the Amazon Bedrock embedding model.
- Nippon uses multi-query RAG by creating multiple variants of the query and executing them in parallel. The obtained results are reranked using a reranker model for higher accuracy.
- The prompt is augmented with the references from the source documents to create citations
- The augmented prompt is sent to Amazon Bedrock.
- Amazon Bedrock creates and sends the final response to the user.
Nippon plans to use agentic AI implementation in the future for automating the data retrieval, indexing, and ingestion.
Results
Nippon saw the following improvements after implementing RAG:
- Accuracy was increased by more than 95%
- Hallucination was reduced by 90–95%
- They were able to add source chunks and file links (through file metadata), which improves the user confidence in the response
- The time needed to generate a report was reduced from 2 days to approximately 10 minutes
Summary
In this post, we discussed RAG and some of the challenges associated with processing large volumes of documents. We explained the advanced RAG methods used in the Nippon AI assistant, including enhanced parsing using Amazon Bedrock Knowledge Bases and third-party models. In addition, we explained query reformulation and multi-query RAG techniques—such as generating multiple queries, reranking results, using GraphRAG, and applying metadata filtering. Finally, we described the end-to-end solution implemented for the Nippon AI assistant. These methods are generally available and are not built by or belong only to Nippon.
Explore Amazon Bedrock Knowledge Bases for RAG use cases by using advanced RAG features such as FM as a parser, query reformulation, reranker models, GraphRAG, and others to implement highly accurate RAG solutions. You can also use Amazon Bedrock Guardrails to build responsible AI solutions by enforcing content and image safeguards and enabling automated reasoning checks.
Please note that RAG methods mentioned in the blog are generally available to all and are not built by or belong only to Nippon.
About the authors
 Shailesh Shivakumar is an FSI Sr. Solutions Architect with AWS India. He works with financial enterprises such as banks, NBFCs, and trading enterprises to help them design secure cloud systems and accelerate their cloud journey. He builds demos and proofs of concept to demonstrate the art of the possible on the AWS Cloud. He leads other initiatives such as customer enablement workshops, AWS demos, cost optimization, and solution assessments to make sure AWS customers succeed in their cloud journey. Shailesh is part of Machine Learning TFC at AWS, handling generative AI and machine learning-focused customer scenarios. Security, serverless, containers, and machine learning in the cloud are his key areas of interest.
Shailesh Shivakumar is an FSI Sr. Solutions Architect with AWS India. He works with financial enterprises such as banks, NBFCs, and trading enterprises to help them design secure cloud systems and accelerate their cloud journey. He builds demos and proofs of concept to demonstrate the art of the possible on the AWS Cloud. He leads other initiatives such as customer enablement workshops, AWS demos, cost optimization, and solution assessments to make sure AWS customers succeed in their cloud journey. Shailesh is part of Machine Learning TFC at AWS, handling generative AI and machine learning-focused customer scenarios. Security, serverless, containers, and machine learning in the cloud are his key areas of interest.
 Abhinav Pandey is a seasoned Data Scientist on the Technology team at Nippon Life India Asset Management Ltd, with over 18 years of industry experience, primarily in BFSI, who is passionate about using generative AI and agentic AI to transform business operations. With a proven track record of applying data for strategic decision-making and business growth, he excels at extracting actionable insights from complex datasets using cutting-edge analytical techniques. A strategic thinker and innovative problem solver, he has developed data-driven strategies that enhance operational efficiency and profitability while working effectively with cross-functional teams to align data initiatives with business objectives. In his leadership role, he has driven data science initiatives, fostered innovation, maintained a results-driven approach, and continuously adapted to evolving technologies to stay ahead of industry trends.
Abhinav Pandey is a seasoned Data Scientist on the Technology team at Nippon Life India Asset Management Ltd, with over 18 years of industry experience, primarily in BFSI, who is passionate about using generative AI and agentic AI to transform business operations. With a proven track record of applying data for strategic decision-making and business growth, he excels at extracting actionable insights from complex datasets using cutting-edge analytical techniques. A strategic thinker and innovative problem solver, he has developed data-driven strategies that enhance operational efficiency and profitability while working effectively with cross-functional teams to align data initiatives with business objectives. In his leadership role, he has driven data science initiatives, fostered innovation, maintained a results-driven approach, and continuously adapted to evolving technologies to stay ahead of industry trends.