High service quality is crucial to the reliability of the Azure platform and its hundreds of services. Continuously monitoring the platform service health enables our teams to promptly detect and mitigate incidents that may impact our customers. In addition to automated triggers in our system that react when thresholds are breached and customer-report incidents, we employ Artificial Intelligence-based Operations (AIOps) to detect anomalies. Incident management is a complex process, and it can be a challenge to manage the scale of Azure, and the teams involved to resolve an incident efficiently and effectively with the rich domain knowledge needed. I’ve asked our Azure Core Insights Team to share how they employ the Triangle System using AIOps to drive quicker time to resolution to ultimately benefit user experience.
—Mark Russinovich, Azure CTO at Microsoft
Optimizing incident management
Incidents are managed by designated responsible individuals (DRIs) who are tasked with investigating incoming incidents to manage how and who needs to resolve the incident. As our product portfolio expands, this process becomes increasingly complex as the incident logged against a particular service may not be the root cause and could stem from any number of dependent services. With hundreds of services in Azure, it is nearly impossible for any one person to have domain knowledge in every area. This presents a challenge to the efficiency of manual diagnosis, resulting in redundant assignments and extended Time to Mitigate (TTM). In this blog, we’ll dive into how large language models, generative AI, and the Triangle System help us leverage automation and feedback loops for more efficient incident management.
AI agents are becoming more mature due to the improving reasoning ability of large language models (LLMs), enabling them to articulate all the steps involved in their thought processes. Traditionally, LLMs have been used for generative tasks like summarization without leveraging their reasoning capabilities for real-world decision-making. We saw a use case for this capability and built AI agents to make the initial assignment decisions for incidents, saving time and reducing redundancy. These agents use LLMs as their brain, allowing them to think, reason, and utilize tools to perform actions independently. With better reasoning models, AI agents can now plan more effectively, overcoming previous limitations in their ability to “think” comprehensively. This approach will not only improve efficiency but also enhance the overall user experience by ensuring quicker resolution of incidents.
Introducing the Triangle System
The Triangle System is a framework that employs AI agents to triage incidents. Each AI agent represents the engineers of a specific team and is encoded with domain knowledge of the team to triage issues. It has two advanced functions: Local Triage and Global Triage.
Local Triage System
The Local Triage System is a single agent framework that uses a single agent to represent each team. These single agents provide a binary decision to either accept or reject an incoming incident on behalf of its team, based on historical incidents and existing troubleshooting guides (TSGs). TSGs are a set of guidelines that engineers document to troubleshoot common patterns of issues. These TSGs are used to train the agent to accept or reject incidents and provide the reasoning behind the decision. Additionally, the agent can recommend the team to which the incident should be transferred to, based on the TSGs.
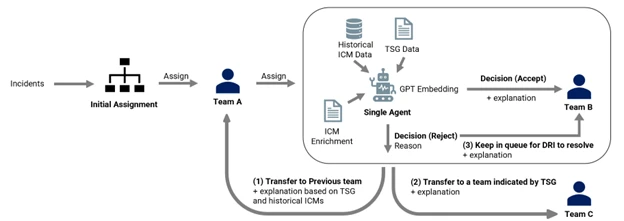
As shown in Figure 1, the Local Triage system begins when an incident enters a service team’s incident queue. Based on the training from historical incidents and TSGs, the single agent employs Generative Pretrained Transformer (GPT) embeddings to capture the semantic meanings of words and sentences. Semantic distillation involves extracting semantic information from the incident that is closely related to incident being triaged. The single agent will then decide to accept or reject the incident. If accepted, the agent will provide the reasoning, and the incident will be handed off to an engineer to review. If rejected, the agent will either send it back to the previous team, transfer to a team indicated by the TSG, or keep it in the queue for an engineer to resolve.
Figure 1: Local Triage system workflow
The Local Triage system has been in production in Azure since mid-2024. As of Jan 2025, 6 teams are in production with over 15 teams in the process of onboarding. The initial results are promising, with agents achieving 90% accuracy and one team saw a reduction in their TTM of 38%, significantly reducing the impact to customers.
Global Triage System
The Global Triage System aims to route the incident to the correct team. The system coordinates across all the single agents via a multi-agent orchestrator to identify the team that the incident should be routed to. As shown in Figure 2, the multi agent orchestrator selects suitable team candidates for the incoming incident, negotiates with each agent to find the correct team, further reducing TTM. This is a similar approach to patients coming into the emergency room, where the nurse briefly assesses symptoms and directs each patient to their specialist. As we further develop the Global Triage System, agents will continue to expand their knowledge and improve their decision-making abilities, greatly improving not only the user experience by mitigating customer issues quickly but also improving developer productivity by reducing manual toil.
Figure 2: Global Triage system workflow
Looking forward
We plan to expand coverage by adding more agents from different teams that will broaden the knowledge base to improve the system. Some of the ways we plan to do this include:
Extend the incident triage system to work for all teams: By extending the system to all teams, we aim to enhance the overall knowledge of the system enabling it to handle a wide range of issues. Creating a unified approach to incident management would lead to more efficient and consistent handling of incidents.
Optimize the LLMs to swiftly identify and recommend solutions by correlating error logs with the specific code segments responsible for the issue: Optimizing LLMs to quickly identify, correlate, and recommend solutions will significantly speed up the troubleshooting process. It allows the system to provide precise recommendations, reducing the time engineers spend on debugging and leading to faster resolution of issues for customers.
Expand auto mitigating known issues: Implementing an automated system to mitigate known issues will reduce TTM improving customer experience. This will also reduce the number of incidents that require manual intervention, enabling engineers to focus on delighting customers.
We first introduced AIOps as part of this blog series in February 2020 where we highlighted how integrating AI into Azure’s cloud platform and DevOps processes enhances service quality, resilience, and efficiency through key solutions including hardware failure prediction, pre-provisioning services, and AI-based incident management. AIOps continues to play a critical role today to predict, protect, and mitigate failures and impacts to the Azure platform and improve customer experience.
By automating these processes, our teams are empowered to quickly identify and address issues, ensuring a high-quality service experience for our customers. Organizations looking to enhance their own service reliability and developer productivity can do so by integrating AI agents into their incident management processes designed in the Triangle System. Read the Triangle: Empowering Incident Triage with Multi-LLM-Agents paper from Microsoft Research.
Thank you to the Azure Core Insights and M365 Team for their contributions to this blog: Alison Yao, Data Scientist; Madhura Vaidya, Software Engineer; Chrysmine Wong, Technical Program Manager; Ze Li, Principal Data Scientist Manager; Sarvani Sathish Kumar, Principal Technical Program Manager; Murali Chintalapati, Partner Group Software Engineering Manager; Minghua Ma, Senior Researcher; and Chetan Bansal, Sr Principal Research Manager.
The post Optimizing incident management with AIOps using the Triangle System appeared first on Microsoft Azure Blog.