
CMA assessment of mobile ecosystems
The CMA has announced an assessment of whether Google has “Strategic Market Status” (SMS) in the mobile ecosystem under the new Digital Markets, Competition and Consumer…
The CMA has announced an assessment of whether Google has “Strategic Market Status” (SMS) in the mobile ecosystem under the new Digital Markets, Competition and Consumer…

Amazon Bedrock Flows offers an intuitive visual builder and a set of APIs to seamlessly link foundation models (FMs), Amazon Bedrock features, and AWS services to build and automate user-defined generative AI workflows at scale. Amazon Bedrock Agents offers a fully managed solution for creating, deploying, and scaling AI agents on AWS. With Flows, you …

Security teams in highly regulated industries like financial services often employ Privileged Access Management (PAM) systems to secure, manage, and monitor the use of privileged access across their critical IT infrastructure. Security and compliance regulations require that security teams audit the actions performed by systems administrators using privileged credentials. Keystroke logging (the action of recording …
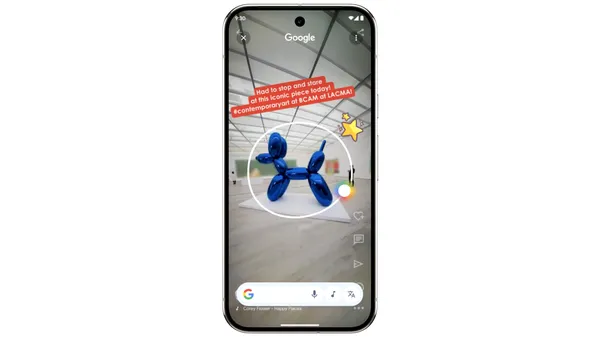
Last year, we introduced Circle to Search to help you easily circle, scribble or tap anything you see on your Android screen, and find information from the web without s…

This is a guest post authored by Asaf Fried, Daniel Pienica, Sergey Volkovich from Cato Networks. Cato Networks is a leading provider of secure access service edge (SASE), an enterprise networking and security unified cloud-centered service that converges SD-WAN, a cloud network, and security service edge (SSE) functions, including firewall as a service (FWaaS), a …
We are thrilled to continue our strategic partnership with OpenAI and to partner on Stargate. Today’s announcement is complementary to what our two companies have been working on together since 2019. The key elements of our partnership remain in place for the duration of our contract through 2030, with our access to OpenAI’s IP, our …
Microsoft and OpenAI evolve partnership to drive the next phase of AI Read More »

Businesses today deal with a reality that is increasingly complex and volatile. Companies across retail, manufacturing, healthcare, and other sectors face pressing challenges in accurate planning and forecasting. Predicting future inventory needs, setting achievable strategic goals, and budgeting effectively involve grappling with ever-changing consumer demand and global market forces. Inventory shortages, surpluses, and unmet customer …

Chat-based assistants have become an invaluable tool for providing automated customer service and support. This post builds on a previous post, Integrate QnABot on AWS with ServiceNow, and explores how to build an intelligent assistant using Amazon Lex, Amazon Bedrock Knowledge Bases, and a custom ServiceNow integration to create an automated incident management support experience. …
Enabling generative AI self-service using Amazon Lex, Amazon Bedrock, and ServiceNow Read More »

SAP and Microsoft are excited to announce a joint program, the RISE with SAP on Microsoft Azure Global Acceleration Program, aimed at accelerating and complementing the adoption of RISE with SAP. This program provides prescriptive guidance, proven recommendations and security principles to enable organizations’ transition seamlessly to the cloud while unlocking the full potential of …
Announcing Global Acceleration Program for RISE with SAP on Microsoft Azure Read More »

This post is co-written with Sujith R Pillai from Kyndryl. In this post, we show you how Kyndryl, an AWS Premier Tier Services Partner and IT infrastructure services provider that designs, builds, manages, and modernizes complex, mission-critical information systems, integrated Amazon Q Business with ServiceNow in a few simple steps. You will learn how to …
How Kyndryl integrated ServiceNow and Amazon Q Business Read More »