How Wipro PARI accelerates PLC code generation using Amazon Bedrock
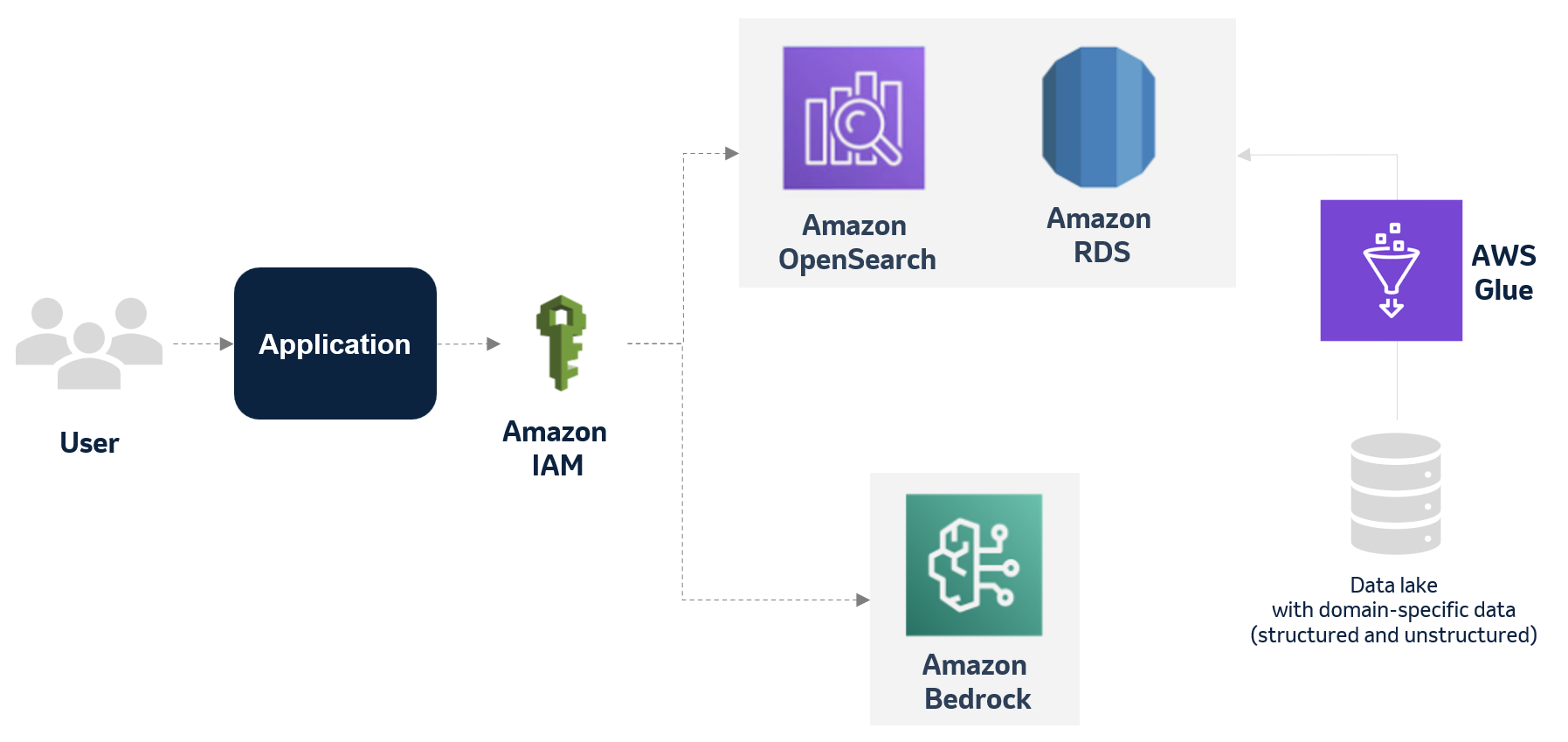
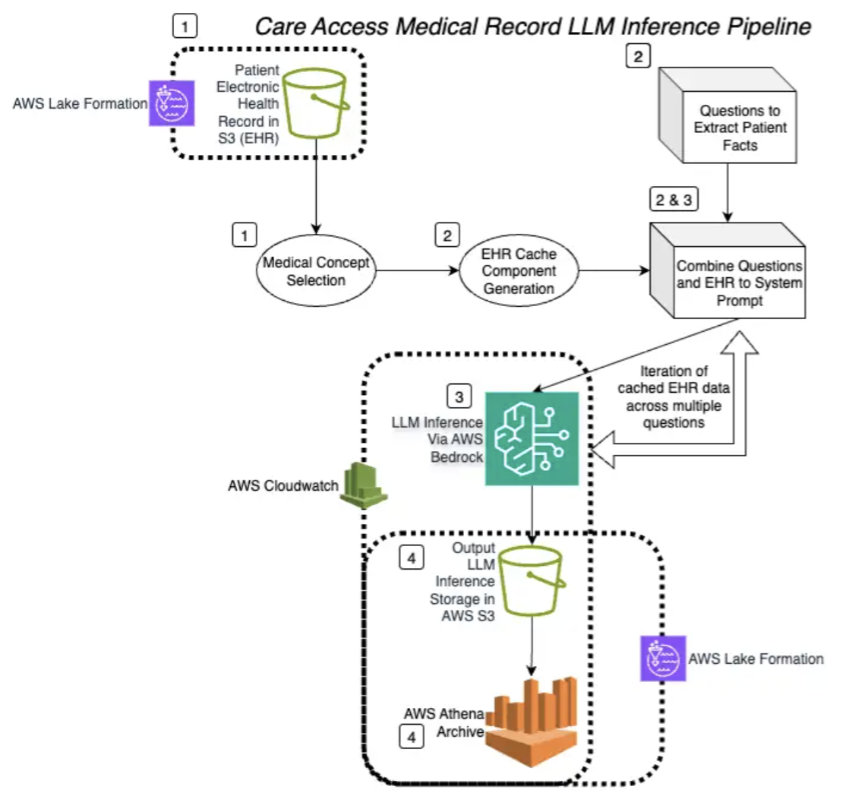
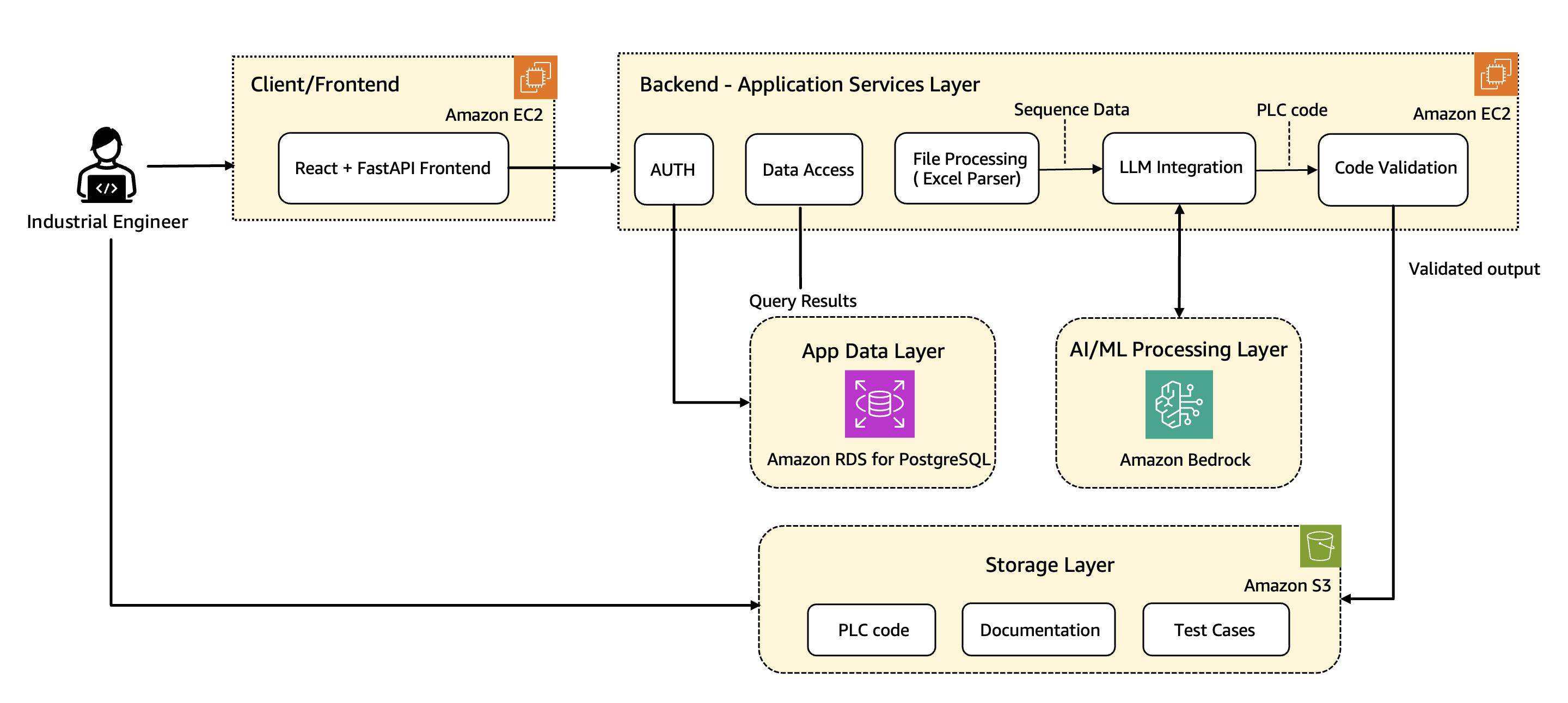
This post is co-written with Rejin Surendran from Wipro Enterprises Limited and Bakrudeen K from ShellKode. In manufacturing environments, industrial automation engineers face a significant challenge: how to rapidly convert complex process requirements into Programmable Logic Controller (PLC) ladder text code. This traditional, manual process typically requires 3-4 days per query, creating bottlenecks in production …
How Wipro PARI accelerates PLC code generation using Amazon Bedrock Read More »