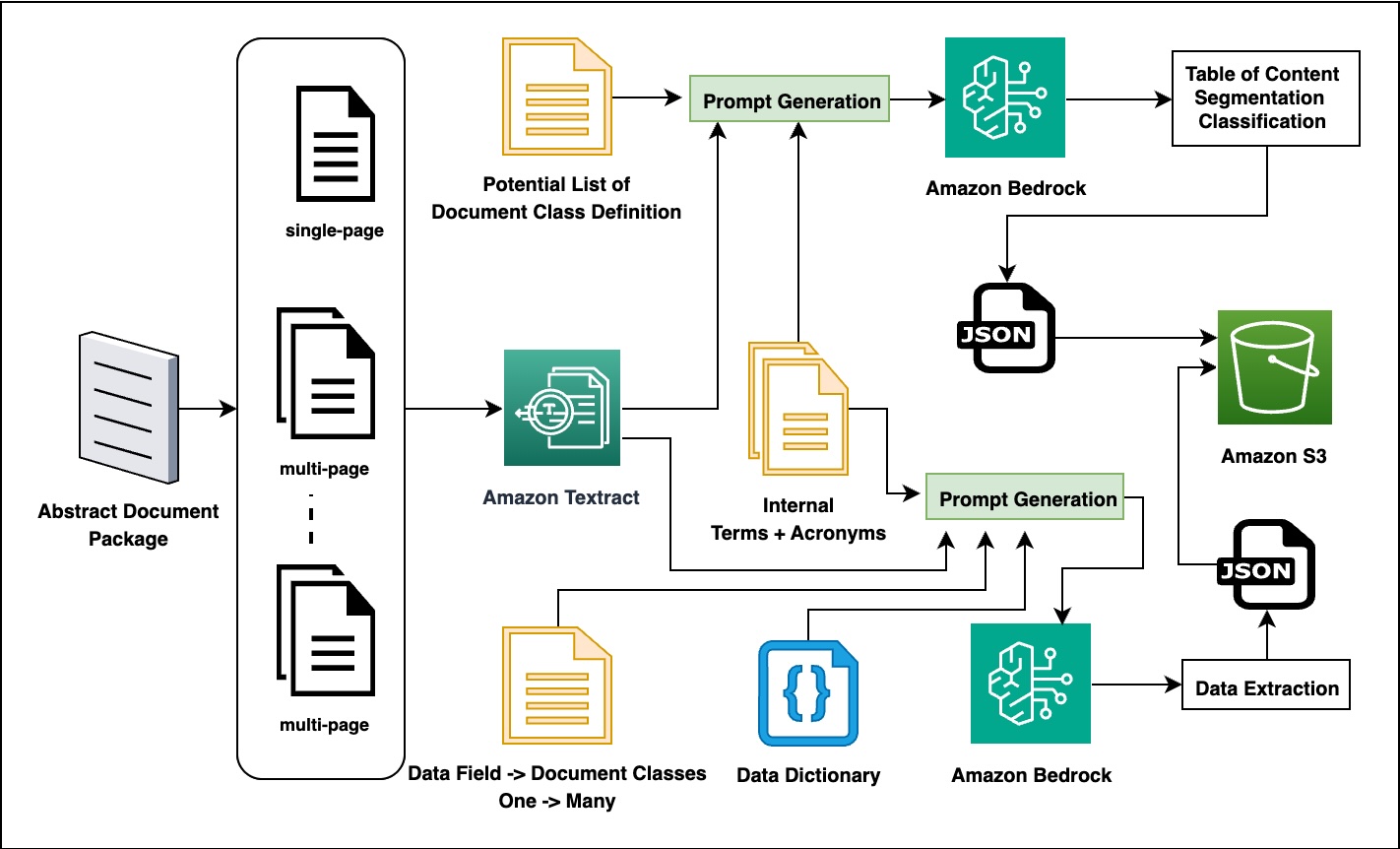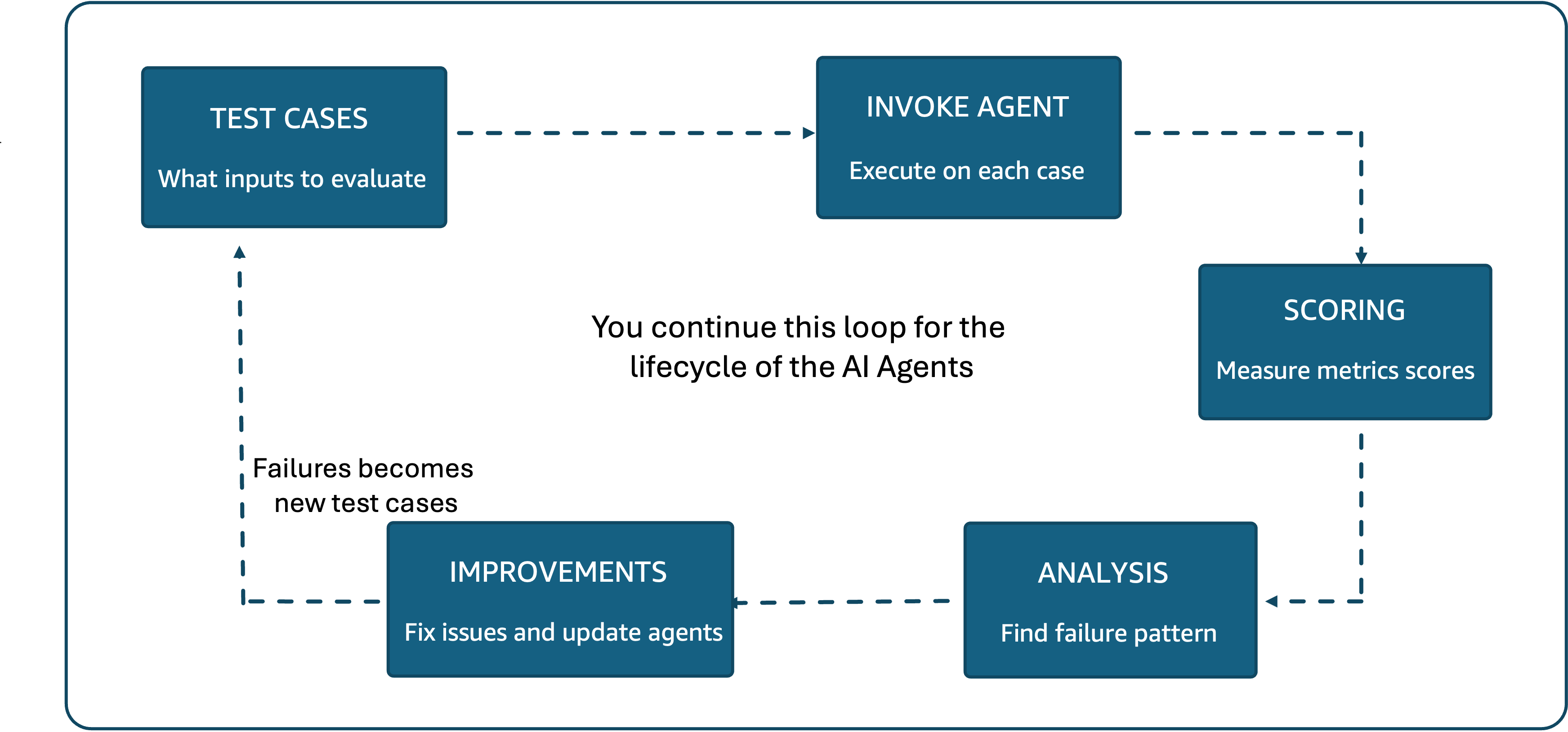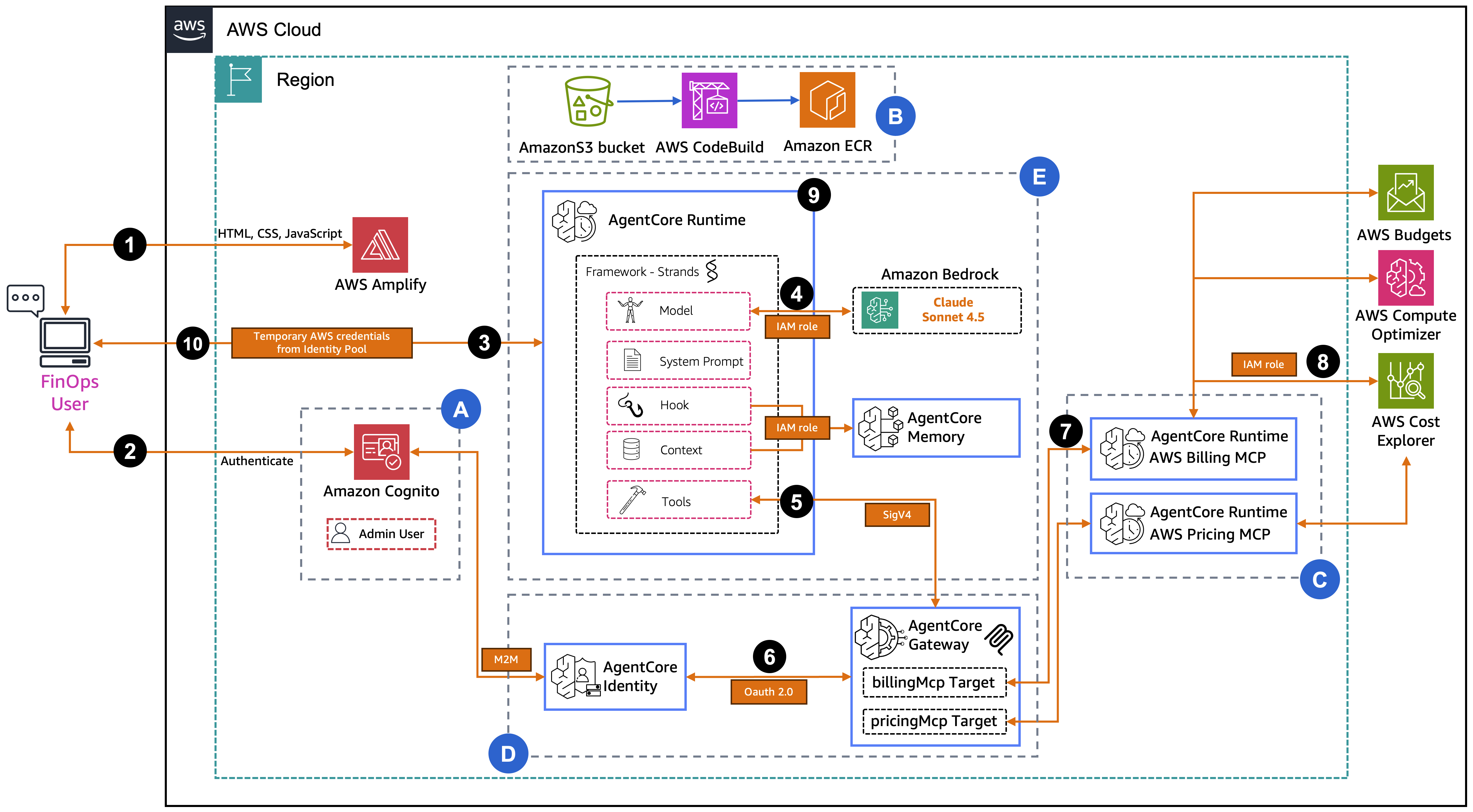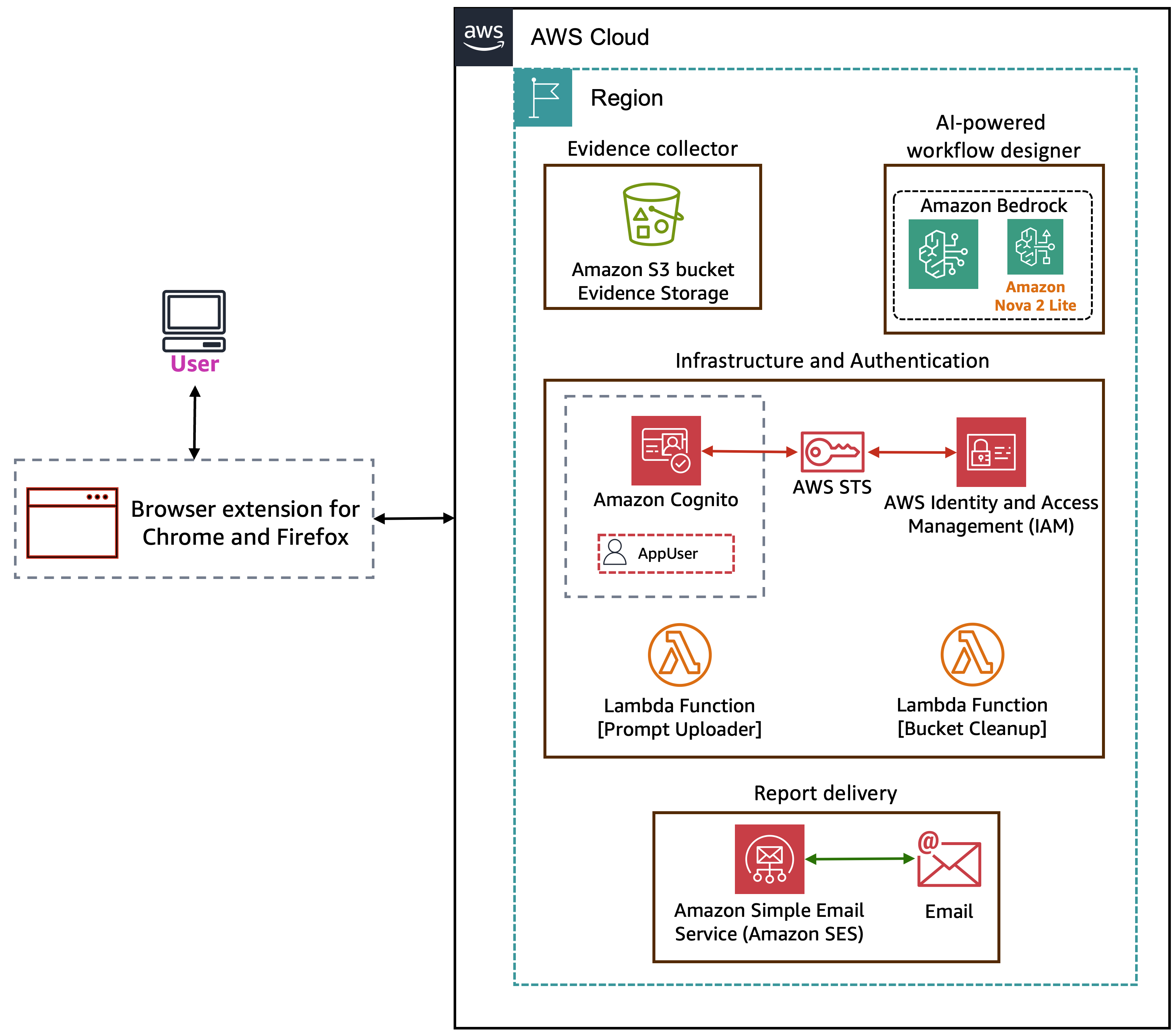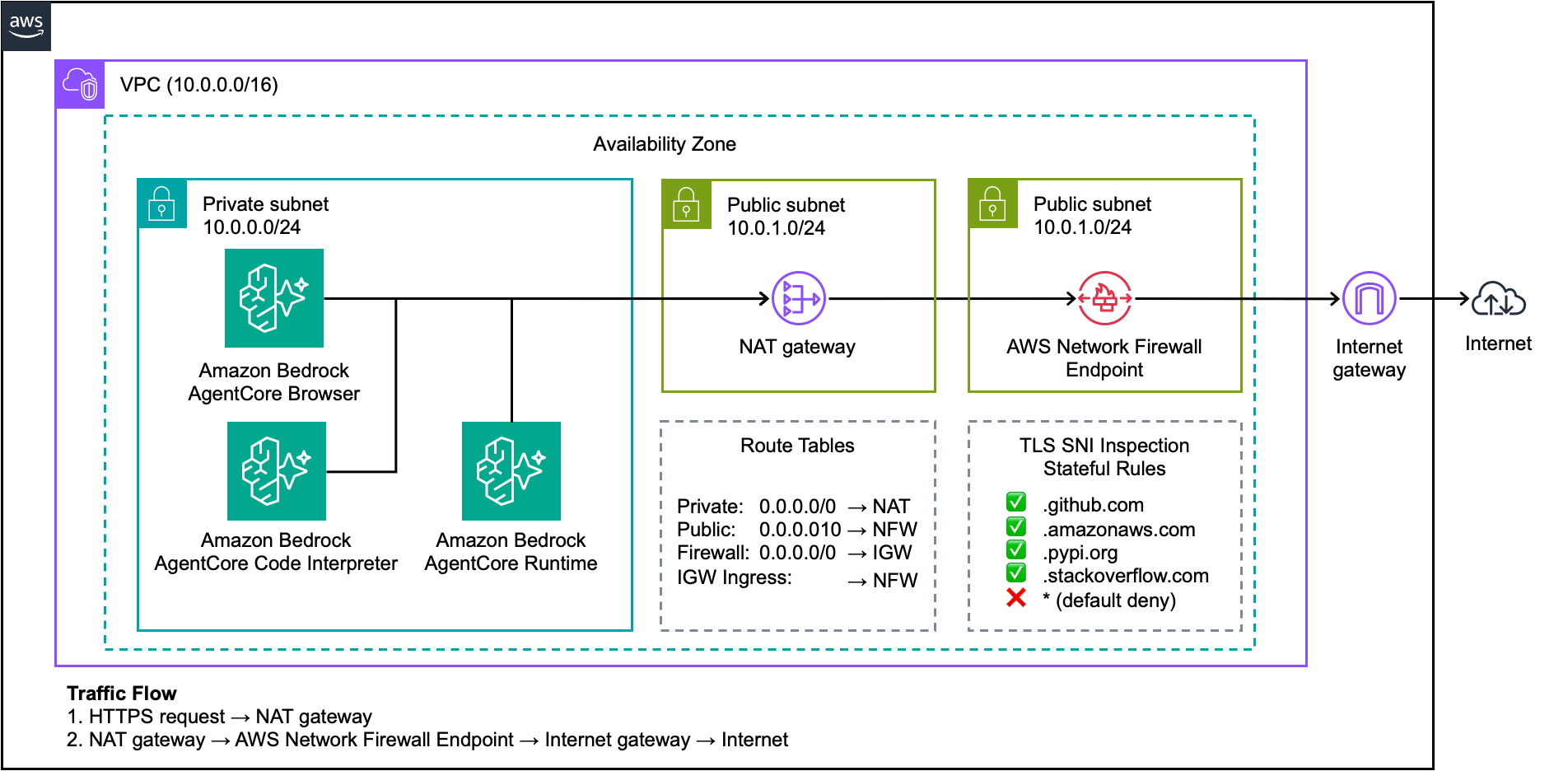
Control which domains your AI agents can access
AI agents that can browse the web open powerful possibilities—from research automation to real-time data gathering. However, giving an AI agent unrestricted internet access raises security and compliance concerns. What if the agent accesses unauthorized websites? What if sensitive data is exfiltrated to external domains? Amazon Bedrock AgentCore provides managed tools that enable AI agents …