Get started with OpenAI GPT-5.6 Sol, Terra, and Luna on Amazon Bedrock
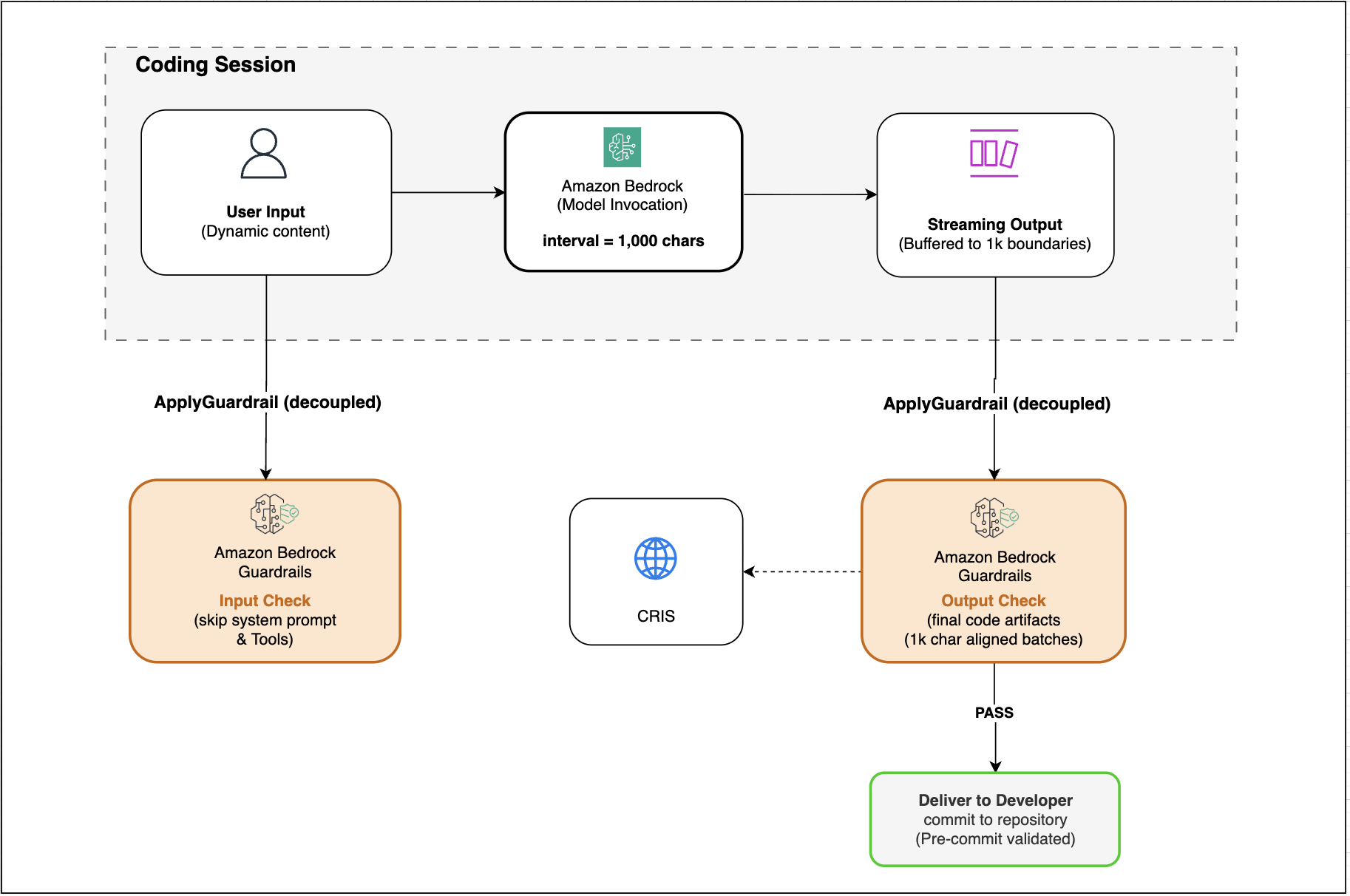
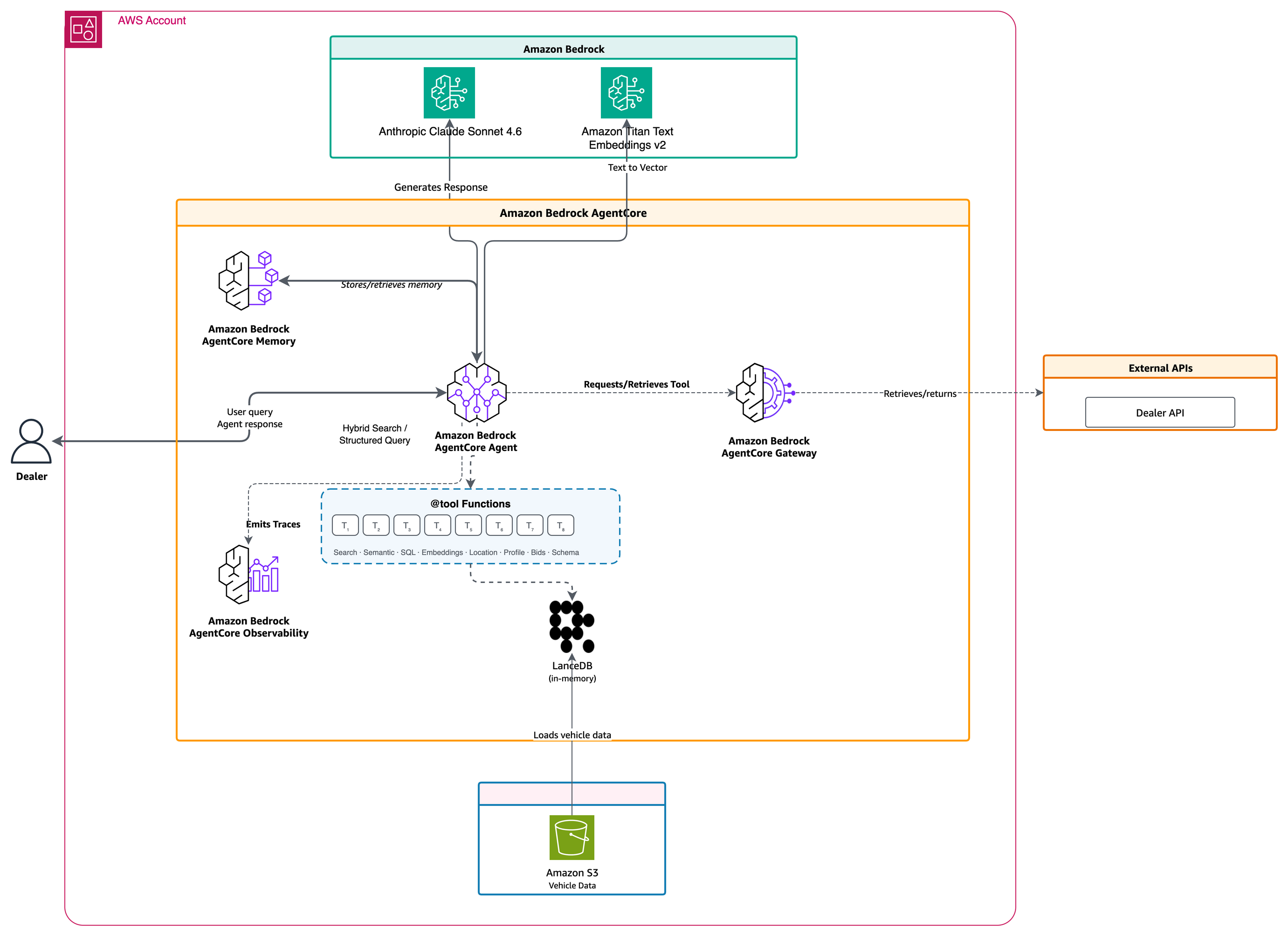
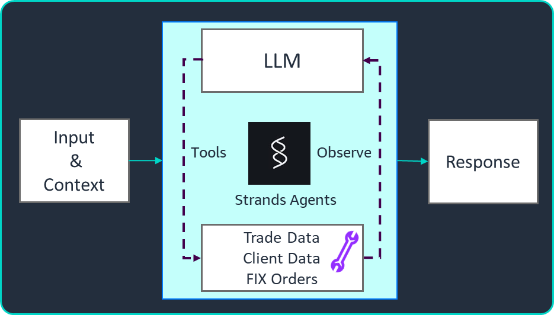
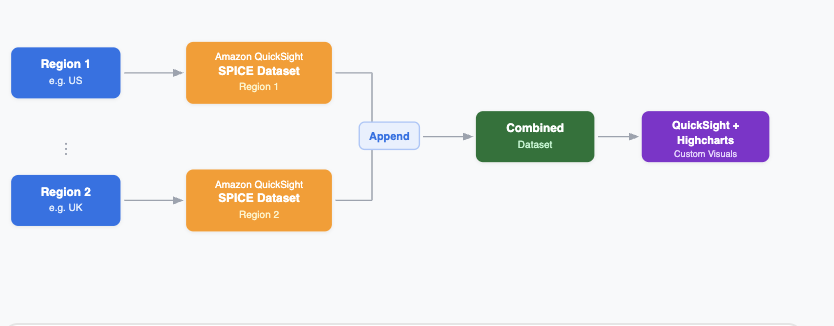
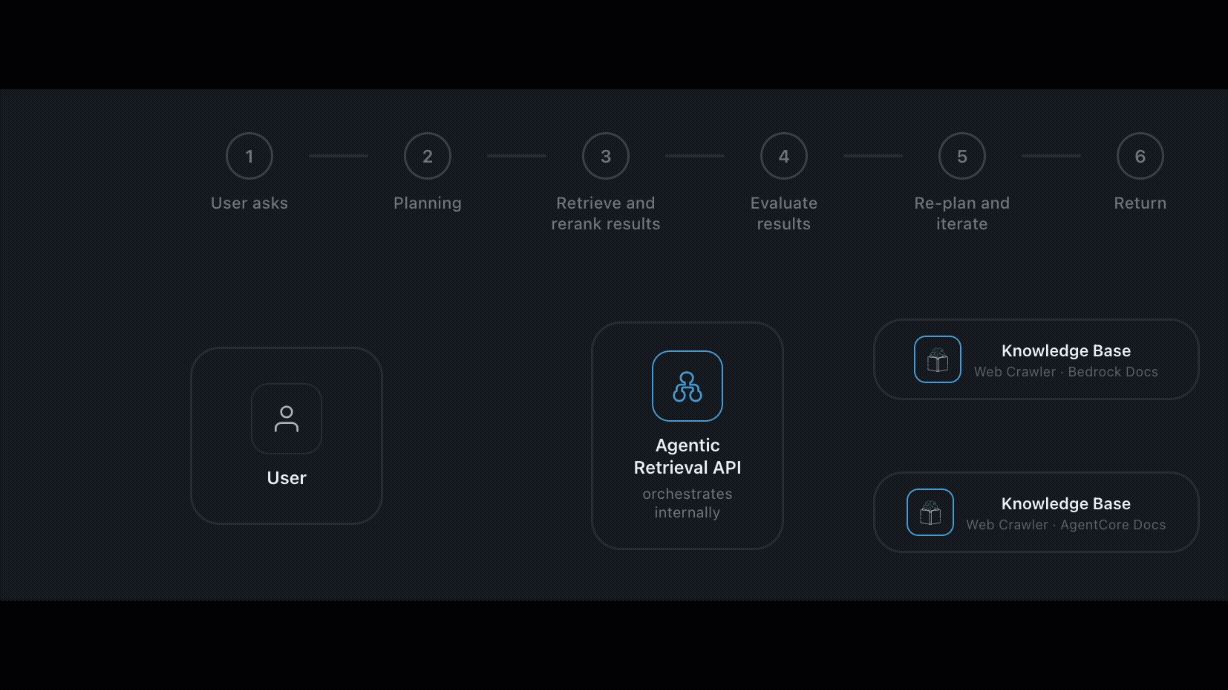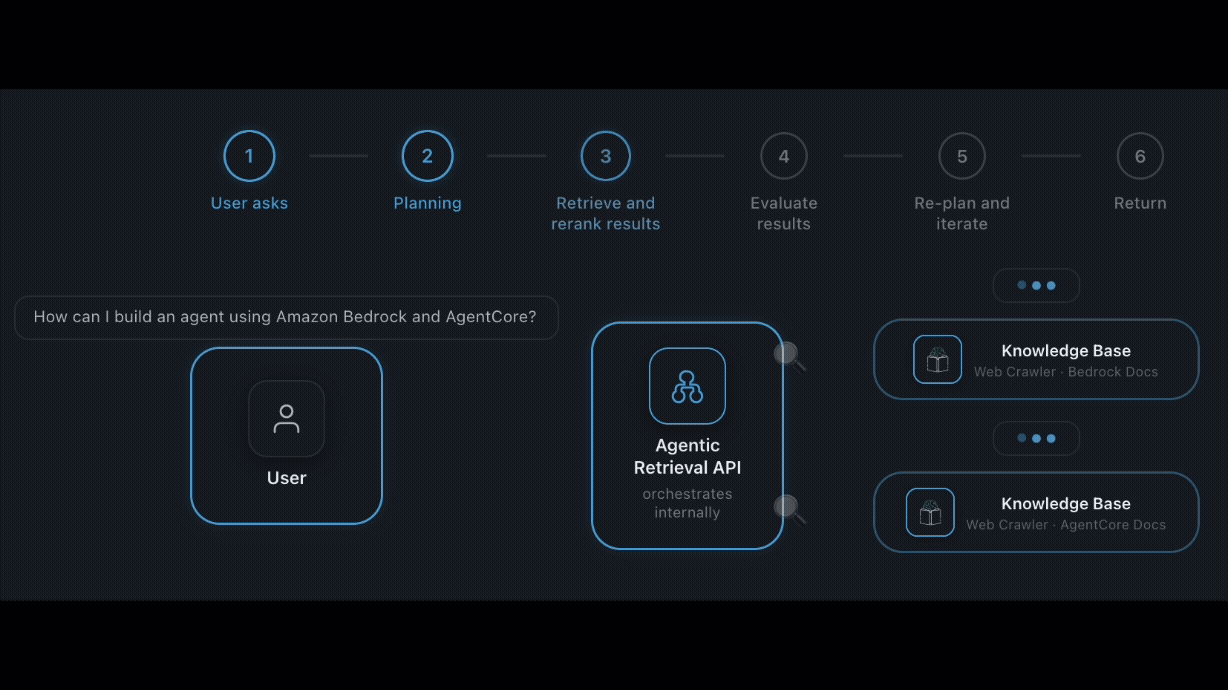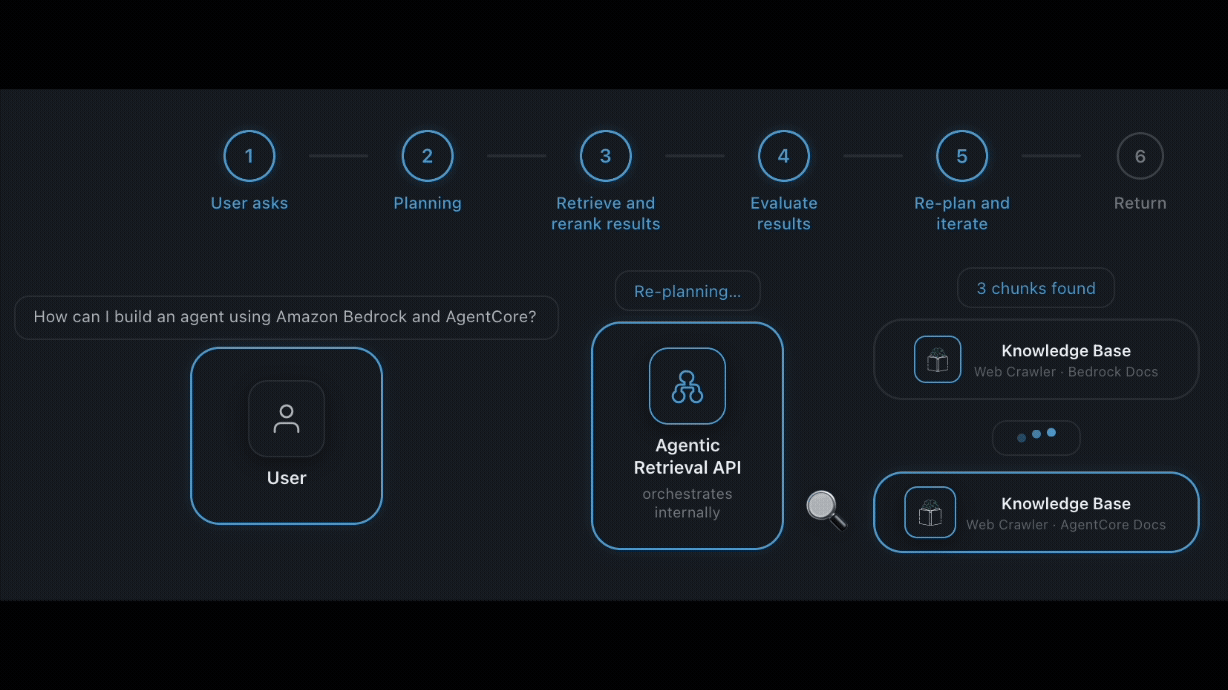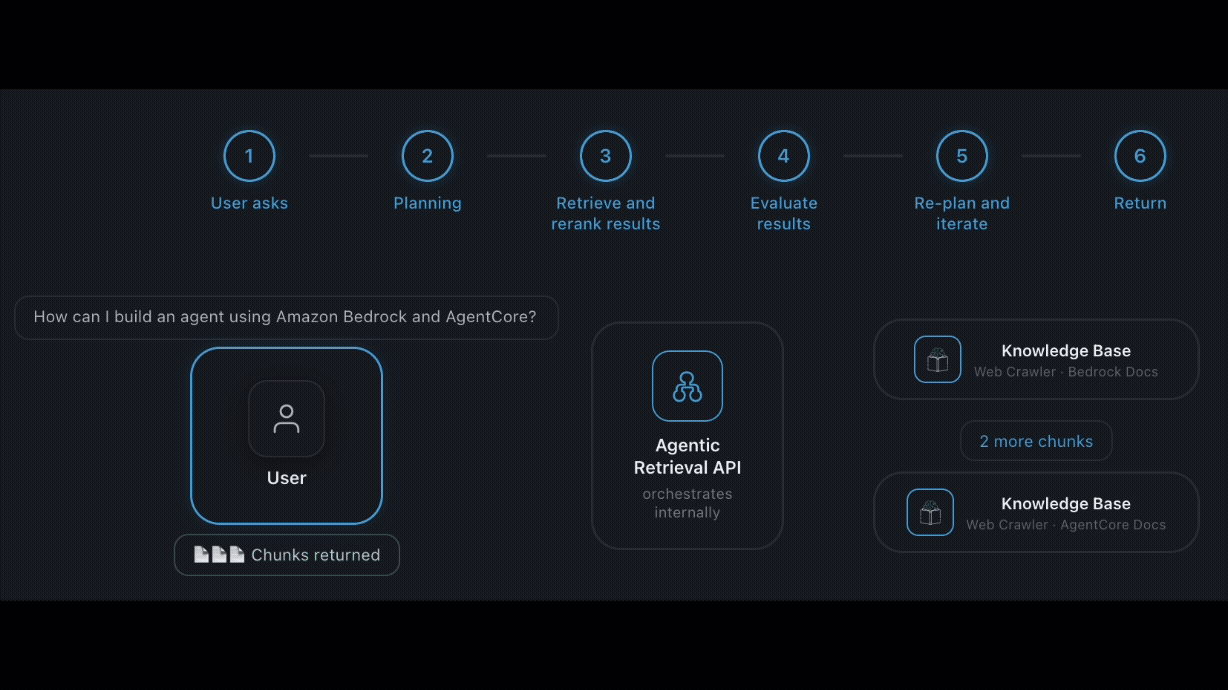
This post is co-written with Chris Dickens from OpenAI. Developers building agentic coding, long-horizon reasoning, and high-volume inference workloads want frontier models they can call through familiar APIs, without operating separate model infrastructure. OpenAI GPT-5.6 Sol, Terra, and Luna are now generally available on Amazon Bedrock. The three models cover workloads from autonomous coding agents […]
Get started with OpenAI GPT-5.6 Sol, Terra, and Luna on Amazon Bedrock Read More »