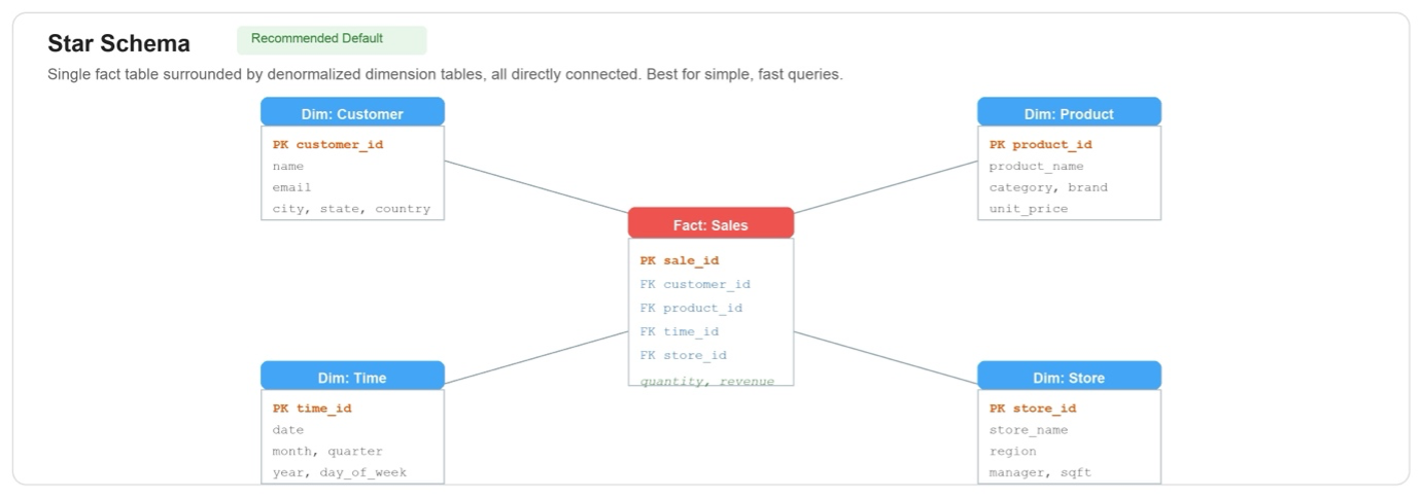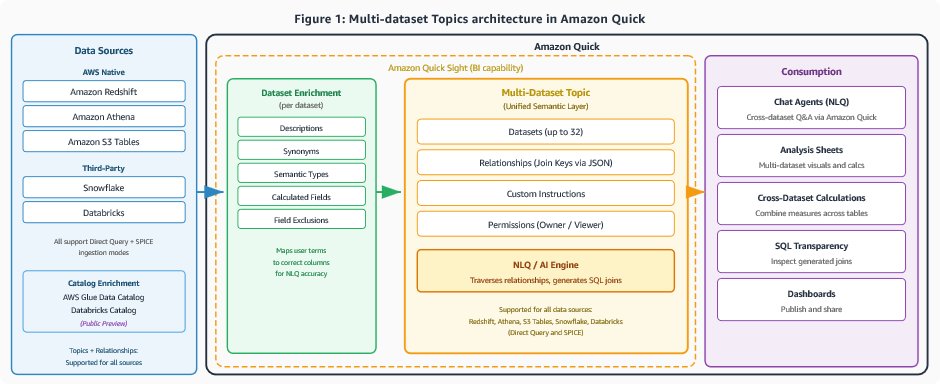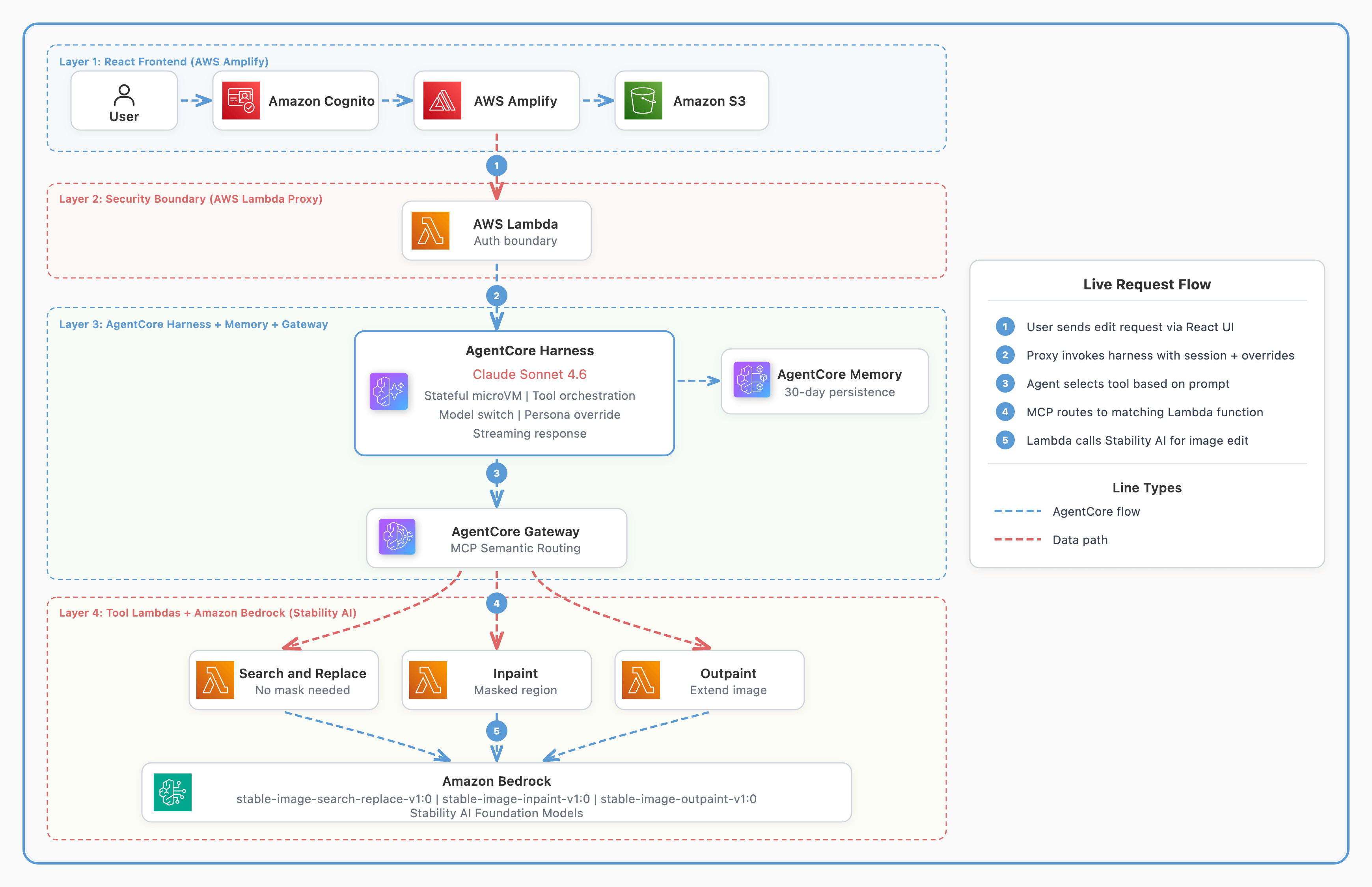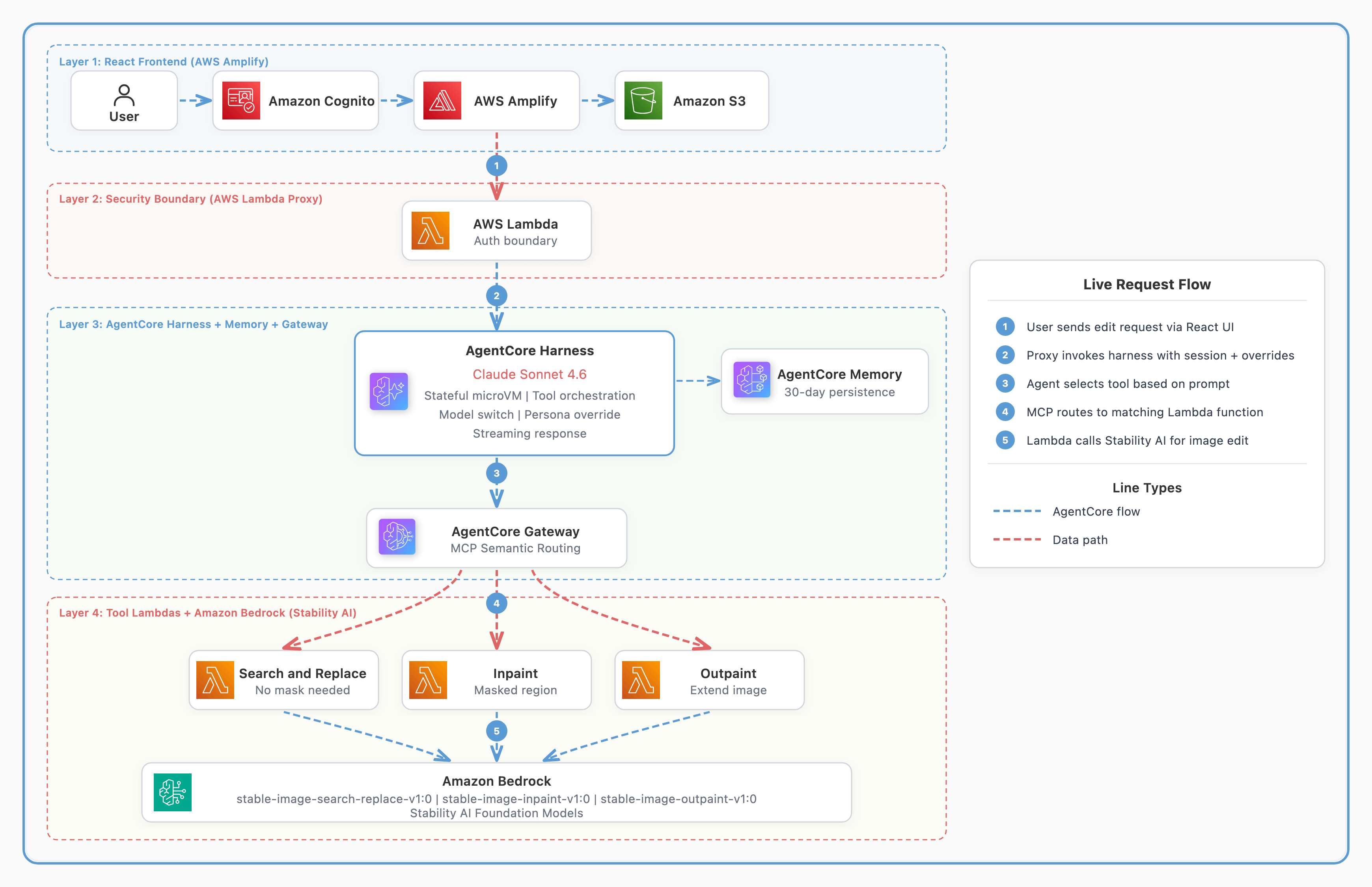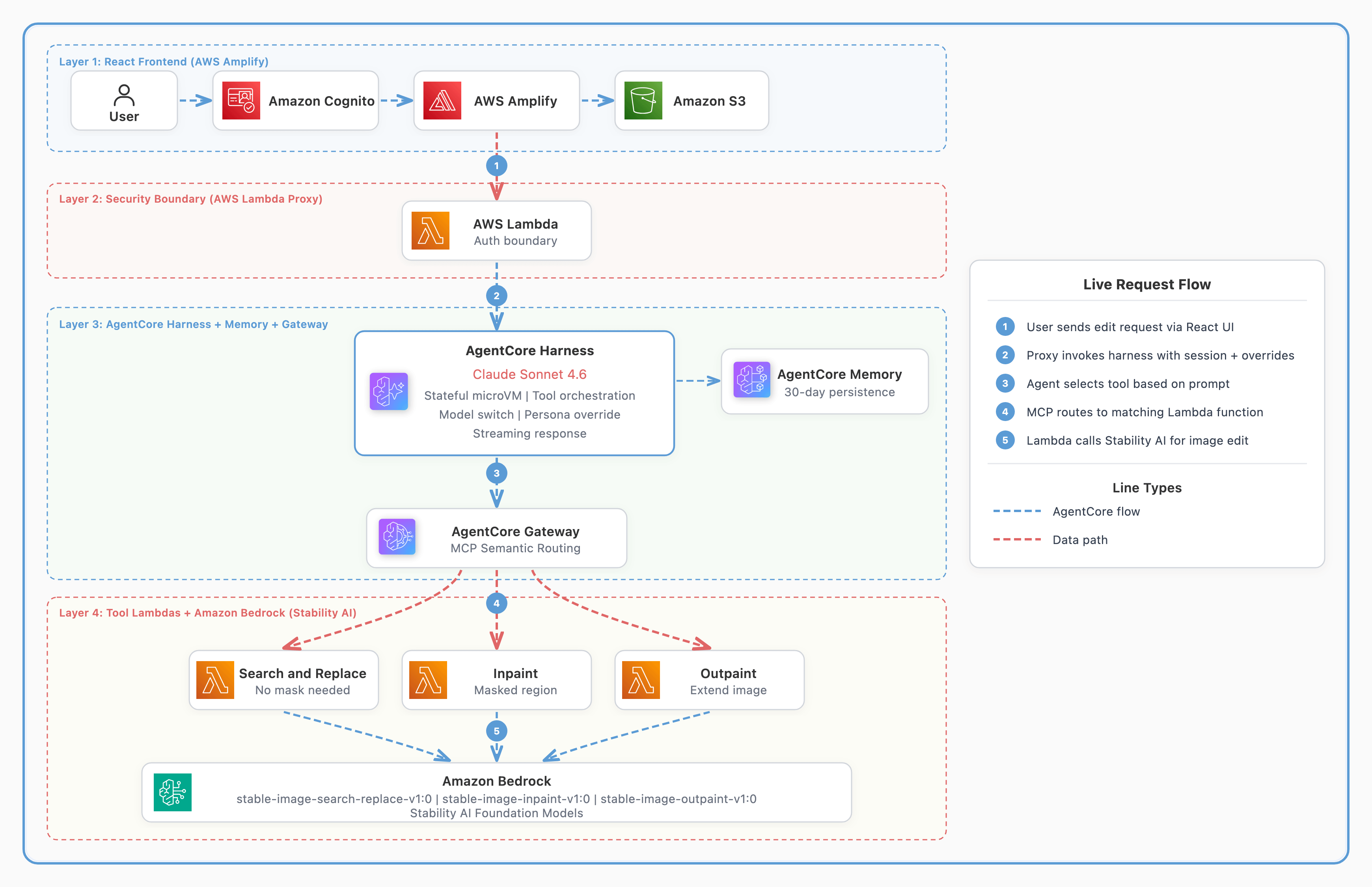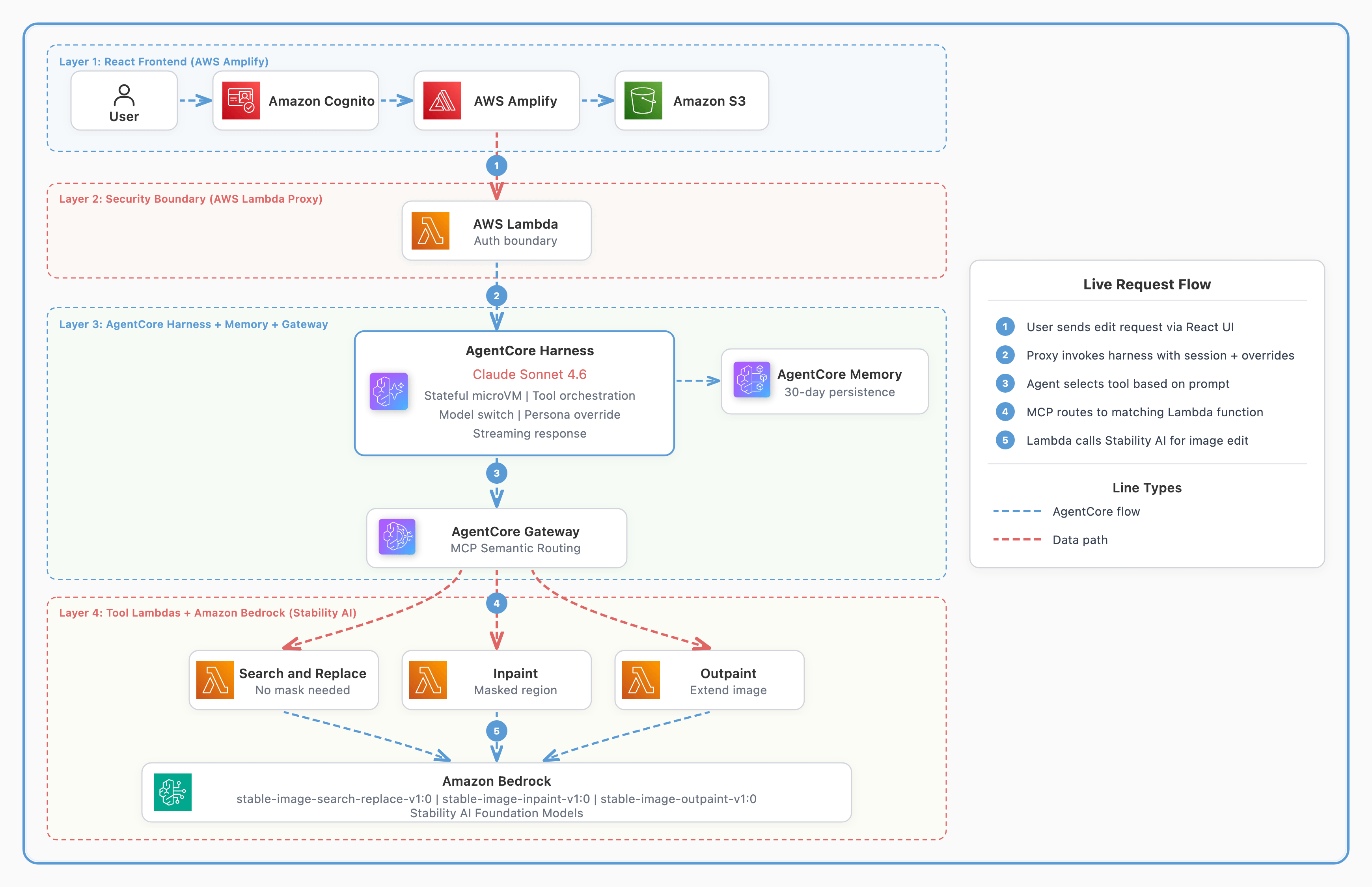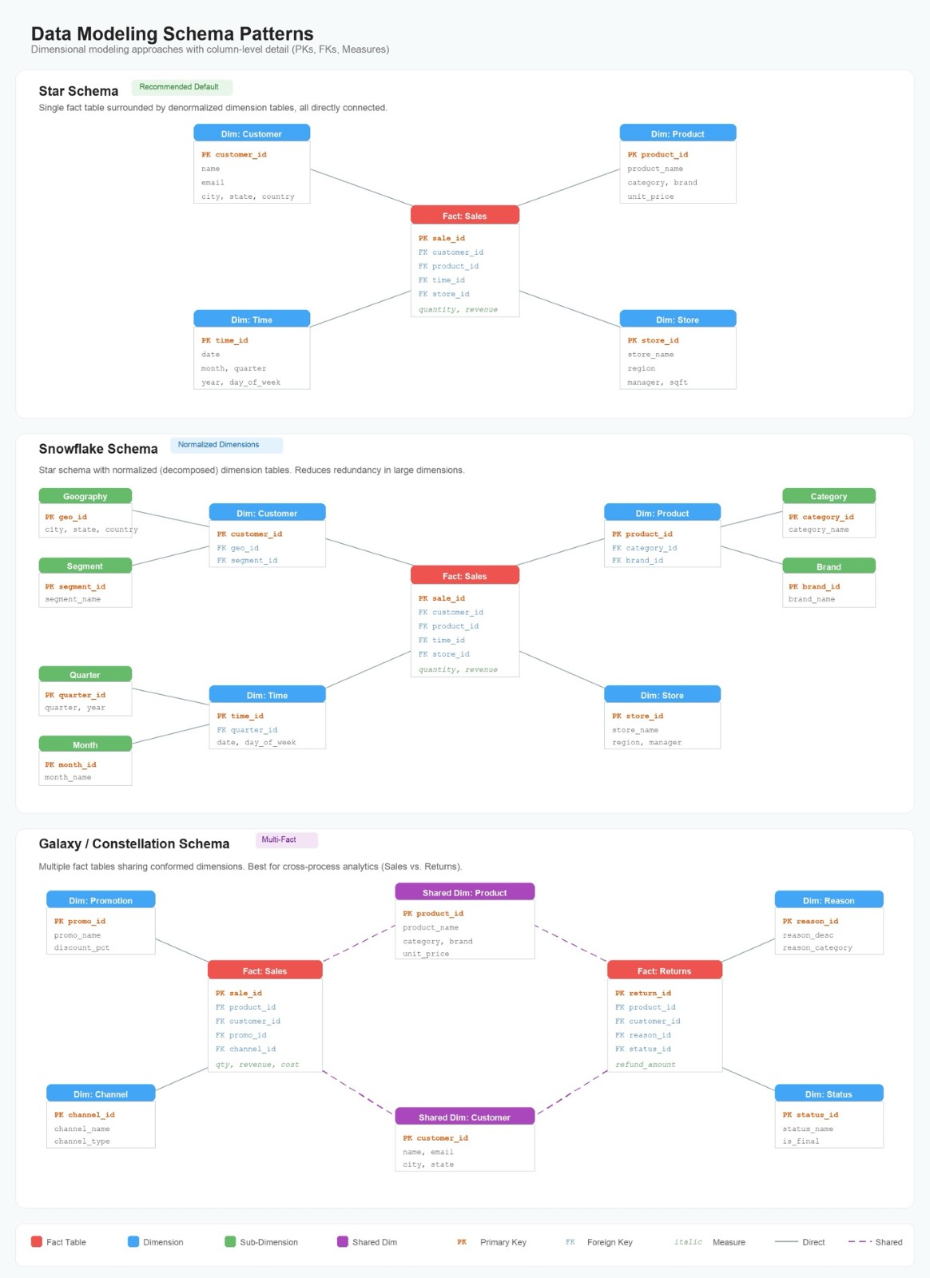
Data modeling best practices for Amazon Quick Sight multi-dataset relationships
Business intelligence analysts routinely face the same challenge at the start of every analytics project: the data needed to answer a single business question lives across multiple tables. Sales transactions sit in one place, customer demographics and product attributes in another, while returns, forecasts, and operational metrics occupy still others. Until now, combining these tables […]
Data modeling best practices for Amazon Quick Sight multi-dataset relationships Read More »