Fine-tune OpenAI GPT-OSS models on Amazon SageMaker AI using Hugging Face libraries
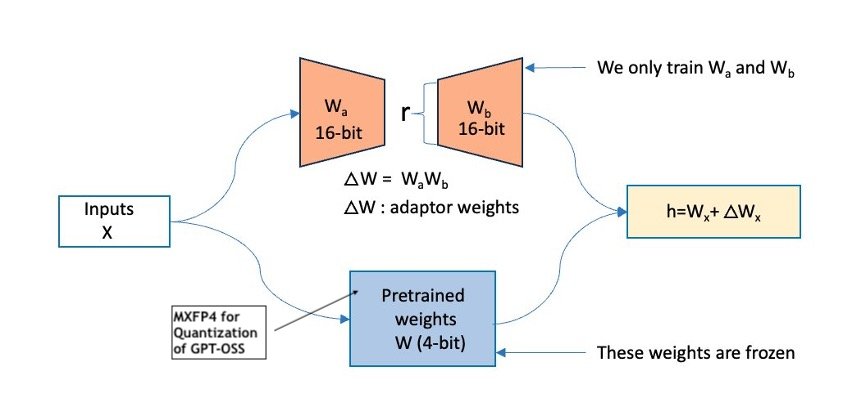
Released on August 5, 2025, OpenAI’s GPT-OSS models, gpt-oss-20b and gpt-oss-120b, are now available on AWS through Amazon SageMaker AI and Amazon Bedrock. These pre-trained, text-only Transformer models are built on a Mixture-of-Experts (MoE) architecture that activates only a subset of parameters per token, delivering high reasoning performance while reducing compute costs. They specialize in …
Fine-tune OpenAI GPT-OSS models on Amazon SageMaker AI using Hugging Face libraries Read More »