
Google Doodles show how AI Mode can help you learn
Every day, students around the world search to learn and explore. Today through Wednesday, our Google homepage Doodles will feature three topics people frequently search…
Every day, students around the world search to learn and explore. Today through Wednesday, our Google homepage Doodles will feature three topics people frequently search…
Starting today, we’re bringing AI Mode, our most powerful AI search experience, to five new languages for users around the globe: Hindi, Indonesian, Japanese, Korean, an…

Learn how Google Research developed Simplify in the Google app for iOS to help you understand complex information more easily.
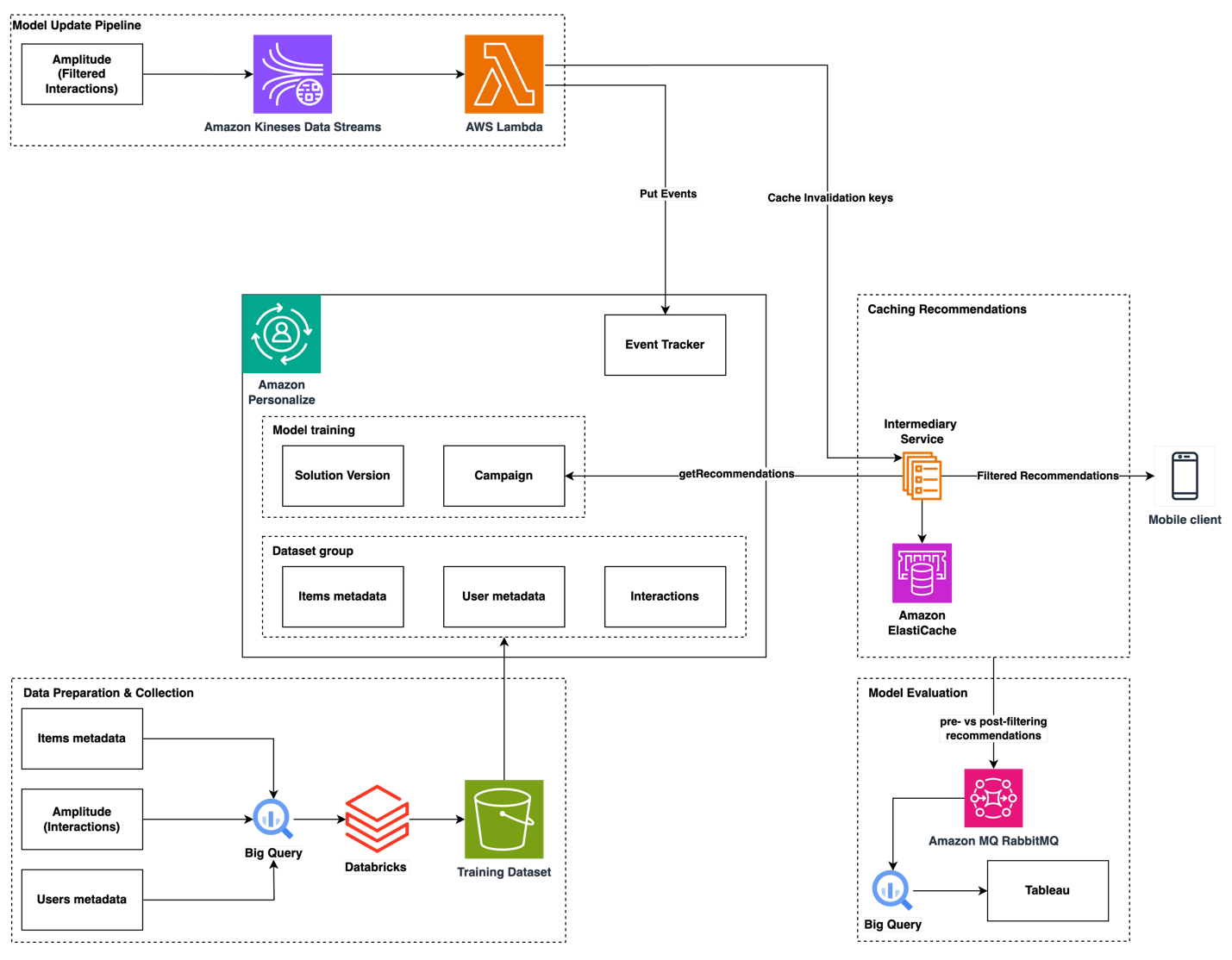
This post was written with Felipe Monroy, Ana Jaime, and Nikita Gordeev from Snoonu. Managing a massive product catalog in the ecommerce space has introduced new hurdles for retailers who are trying to efficiently connect customers with the items they truly want. Traditional one-size-fits-all approaches often result in lost opportunities and reduced customer engagement. For …
The power of AI in driving personalized product discovery at Snoonu Read More »
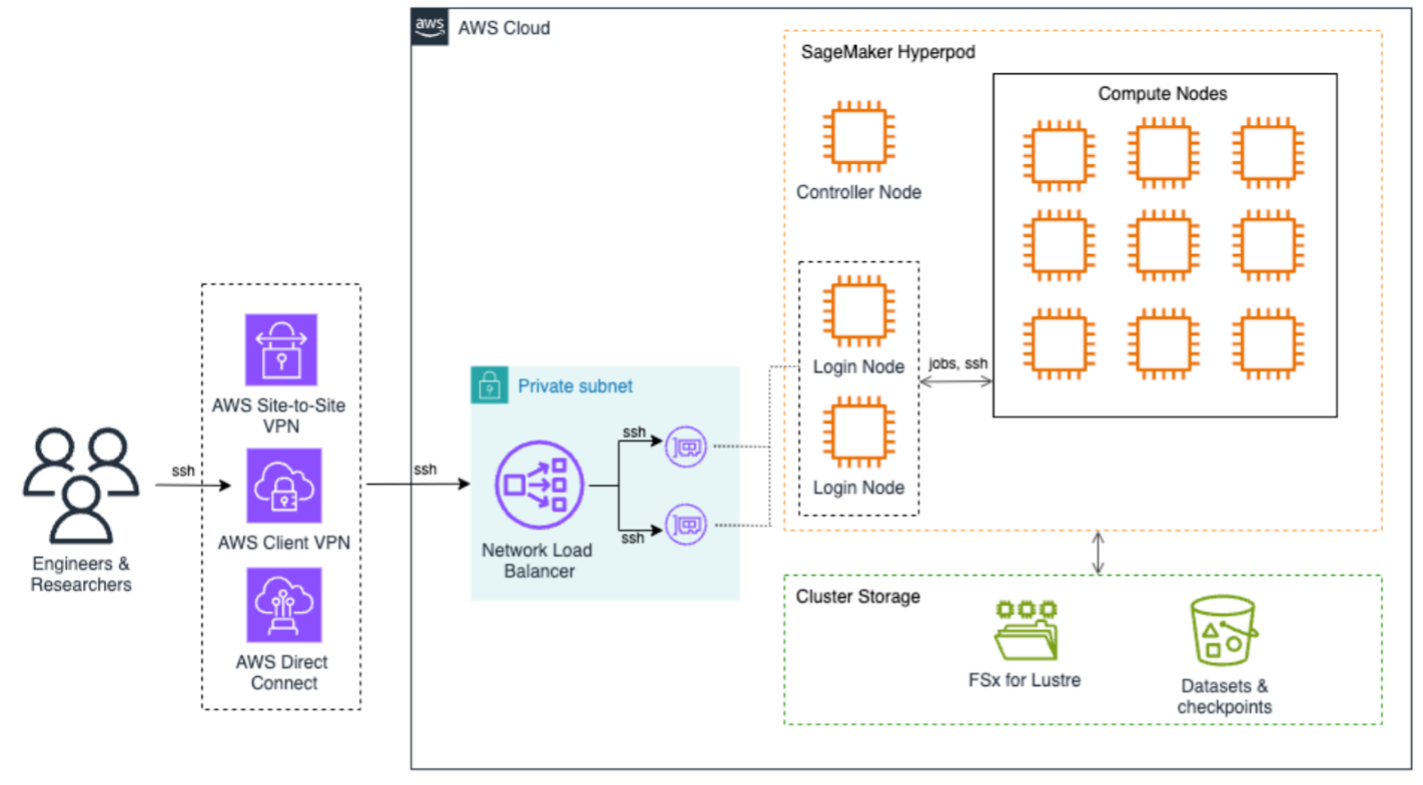
This post was written with Mohamed Hossam of Brightskies. Research universities engaged in large-scale AI and high-performance computing (HPC) often face significant infrastructure challenges that impede innovation and delay research outcomes. Traditional on-premises HPC clusters come with long GPU procurement cycles, rigid scaling limits, and complex maintenance requirements. These obstacles restrict researchers’ ability to iterate …
Accelerating HPC and AI research in universities with Amazon SageMaker HyperPod Read More »
This post is co-written by Jake Friedman, President + Co-founder of Wildlife. Amazon Nova is enhancing sports fan engagement through an immersive Formula 1 (F1)-inspired experience that turns traditional spectators into active participants. This post explores the Real-Time Race Track (RTRT), an interactive experience built using Amazon Nova in Amazon Bedrock, that lets fans design, …
Exploring the Real-Time Race Track with Amazon Nova Read More »
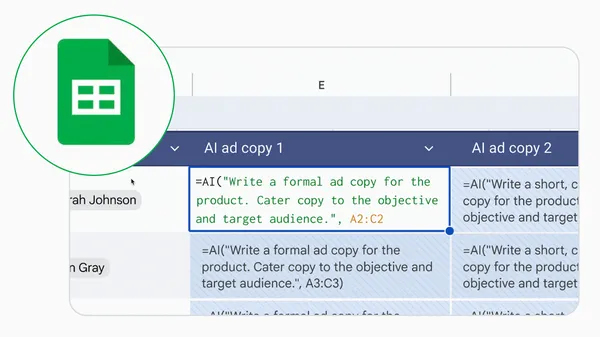
Learn how to get AI insights in one easy step in Google Sheets.

Although careful prompt crafting can yield good results, achieving professional-grade visual consistency often requires adapting the underlying model itself. Building on the prompt engineering and character development approach covered in Part 1 of this two-part series, we now push the consistency level for specific characters by fine-tuning an Amazon Nova Canvas foundation model (FM). Through …
Build character consistent storyboards using Amazon Nova in Amazon Bedrock – Part 2 Read More »

The art of storyboarding stands as the cornerstone of modern content creation, weaving its essential role through filmmaking, animation, advertising, and UX design. Though traditionally, creators have relied on hand-drawn sequential illustrations to map their narratives, today’s AI foundation models (FMs) are transforming this landscape. FMs like Amazon Nova Canvas and Amazon Nova Reel offer …
Build character consistent storyboards using Amazon Nova in Amazon Bedrock – Part 1 Read More »

Learn more about all the editing tools inside Google Photos’ Create tab, like Photo to video, animations and more.