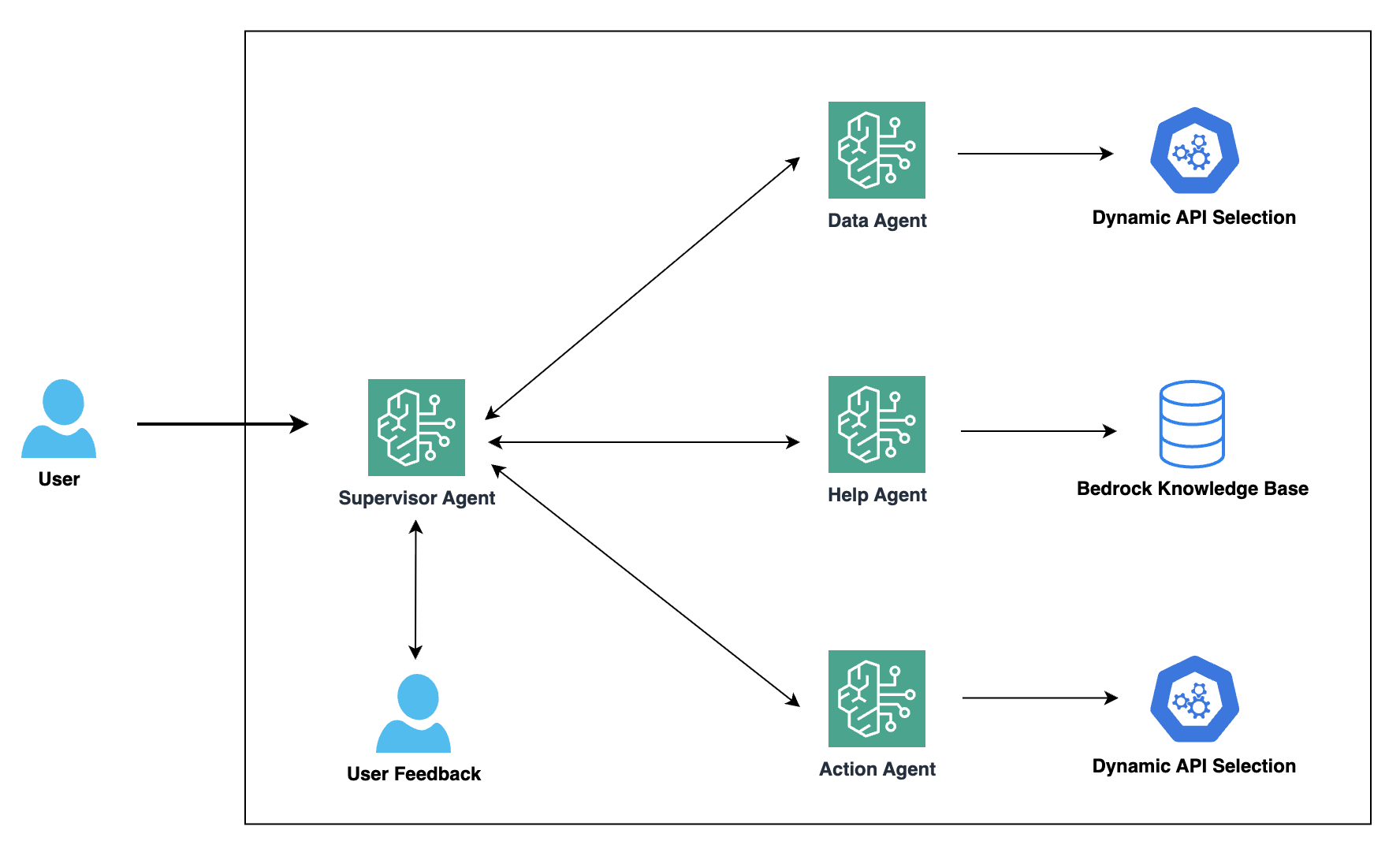
Accelerate enterprise solutions with agentic AI-powered consulting: Introducing AWS Professional Service Agents
AWS Professional Services set out to help organizations accelerate their cloud adoption with expert guidance and proven methodologies. Today, we’re at a pivotal moment in consulting. Just as cloud computing transformed how enterprises build technology, agentic AI is transforming how consulting services deliver value. We believe in a future where intelligent agents work alongside expert …