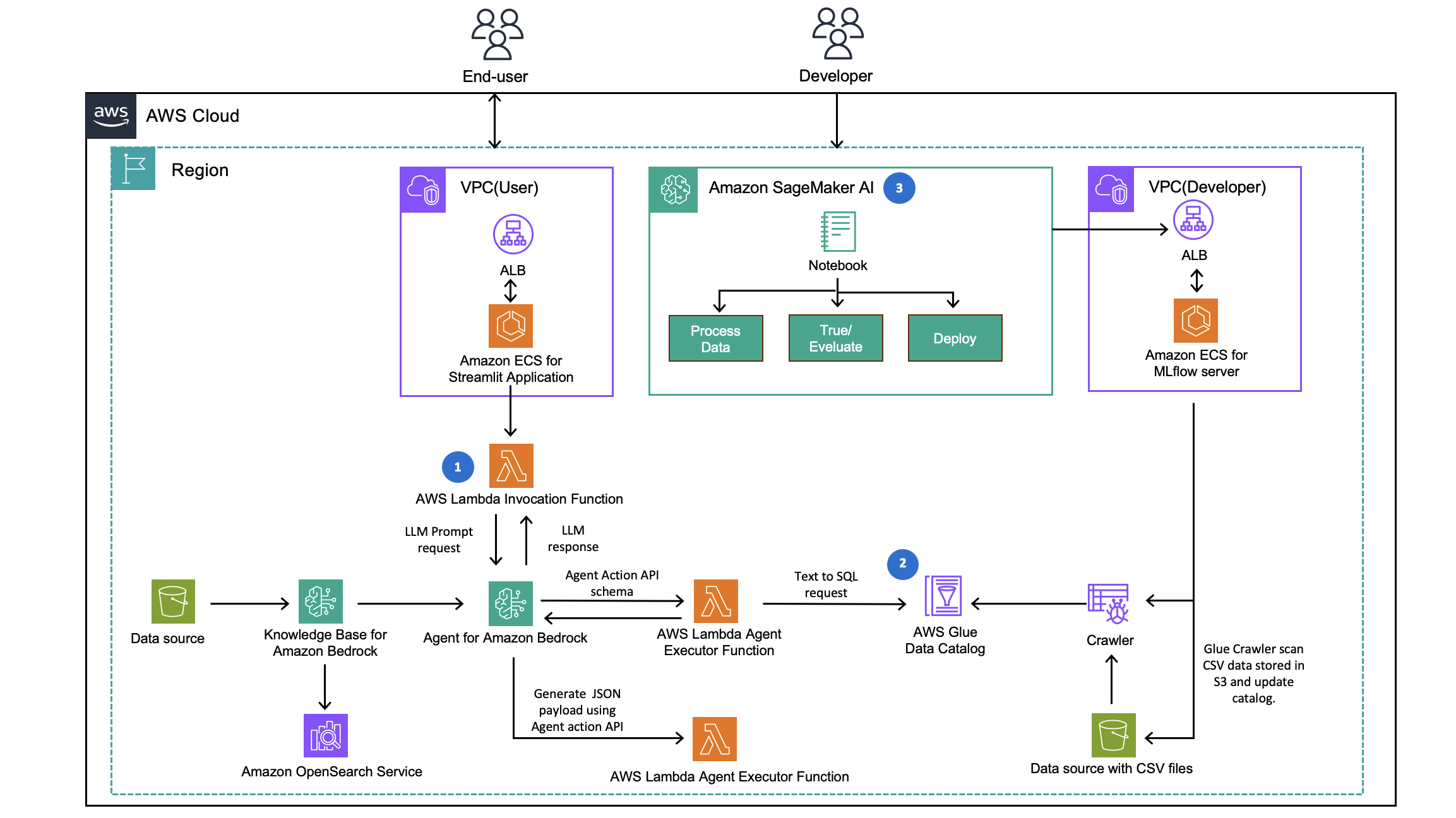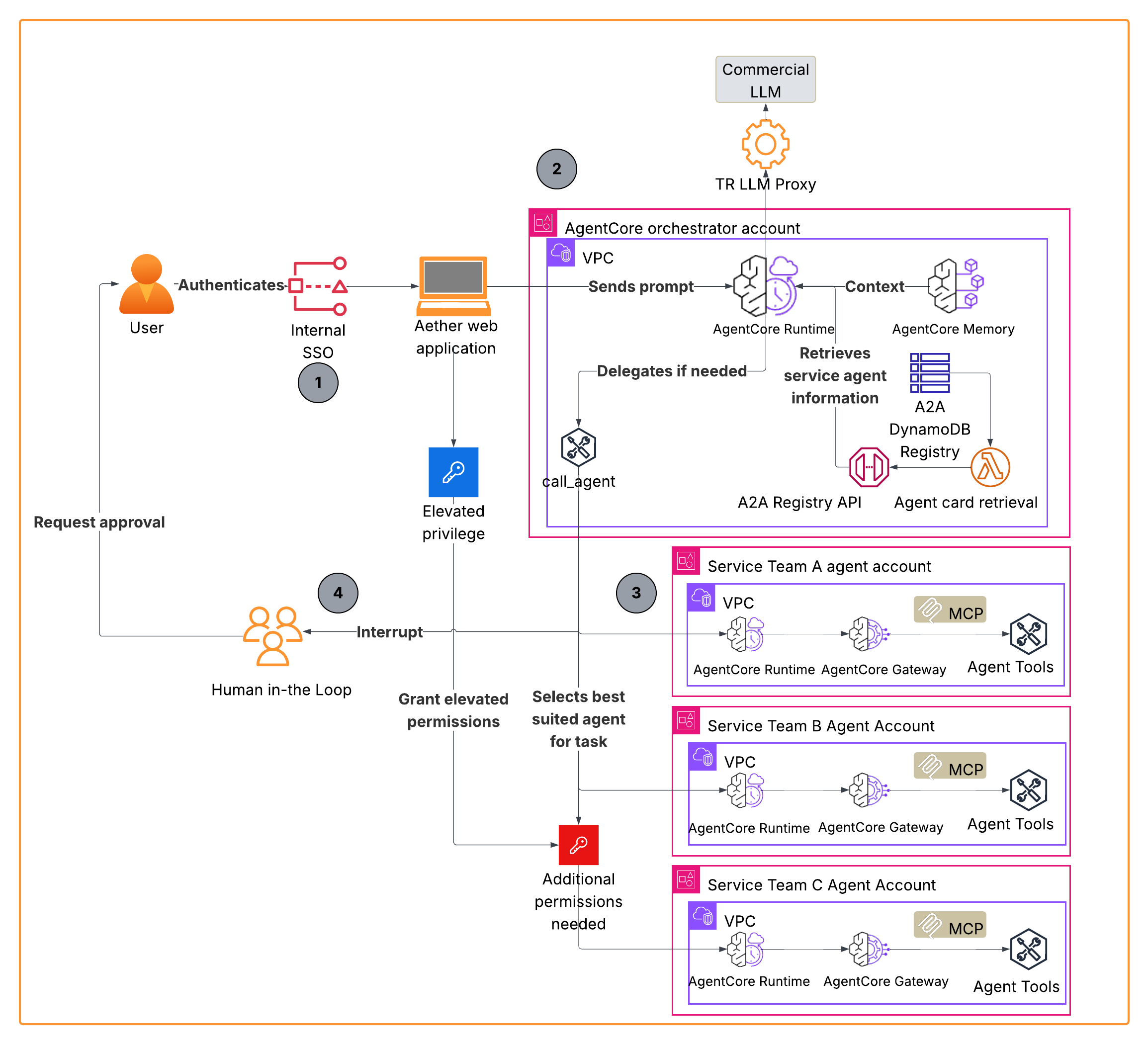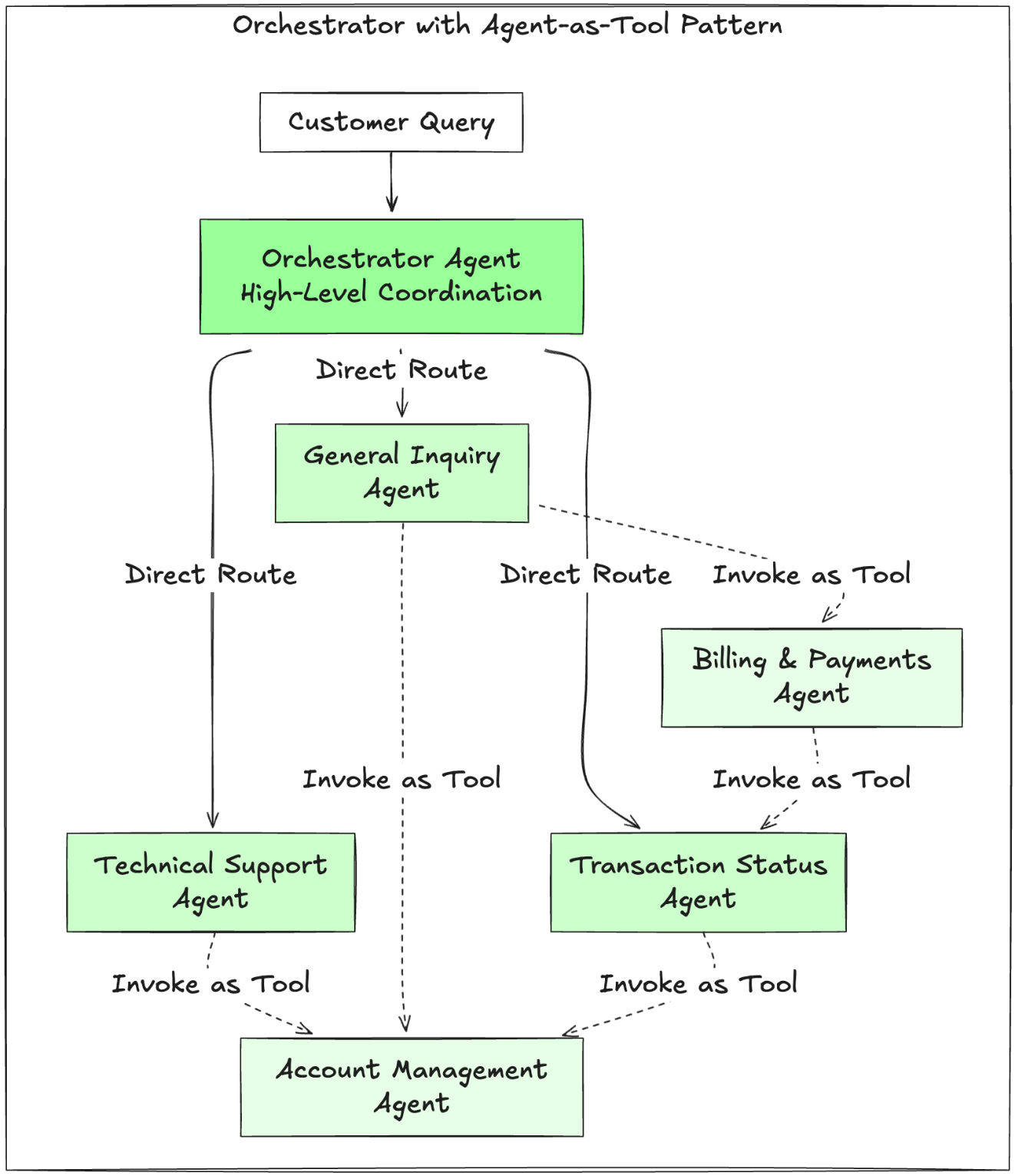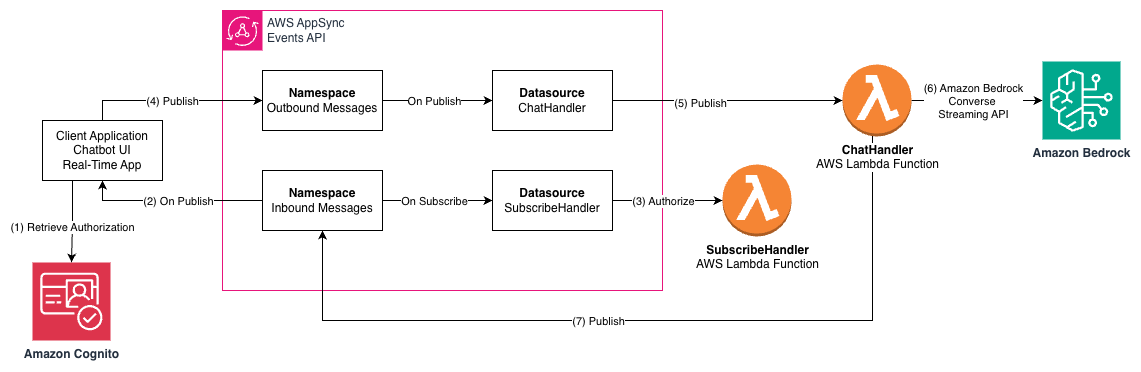
Build a serverless AI Gateway architecture with AWS AppSync Events
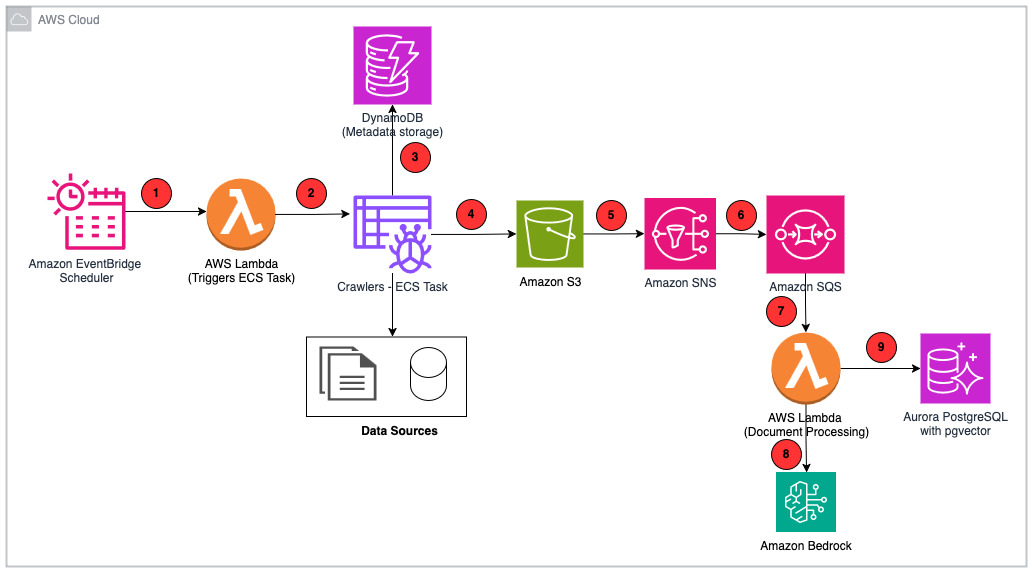
AWS AppSync Events can help you create more secure, scalable Websocket APIs. In addition to broadcasting real-time events to millions of Websocket subscribers, it supports a crucial user experience requirement of your AI Gateway: low-latency propagation of events from your chosen generative AI models to individual users. In this post, we discuss how to use …
Build a serverless AI Gateway architecture with AWS AppSync Events Read More »