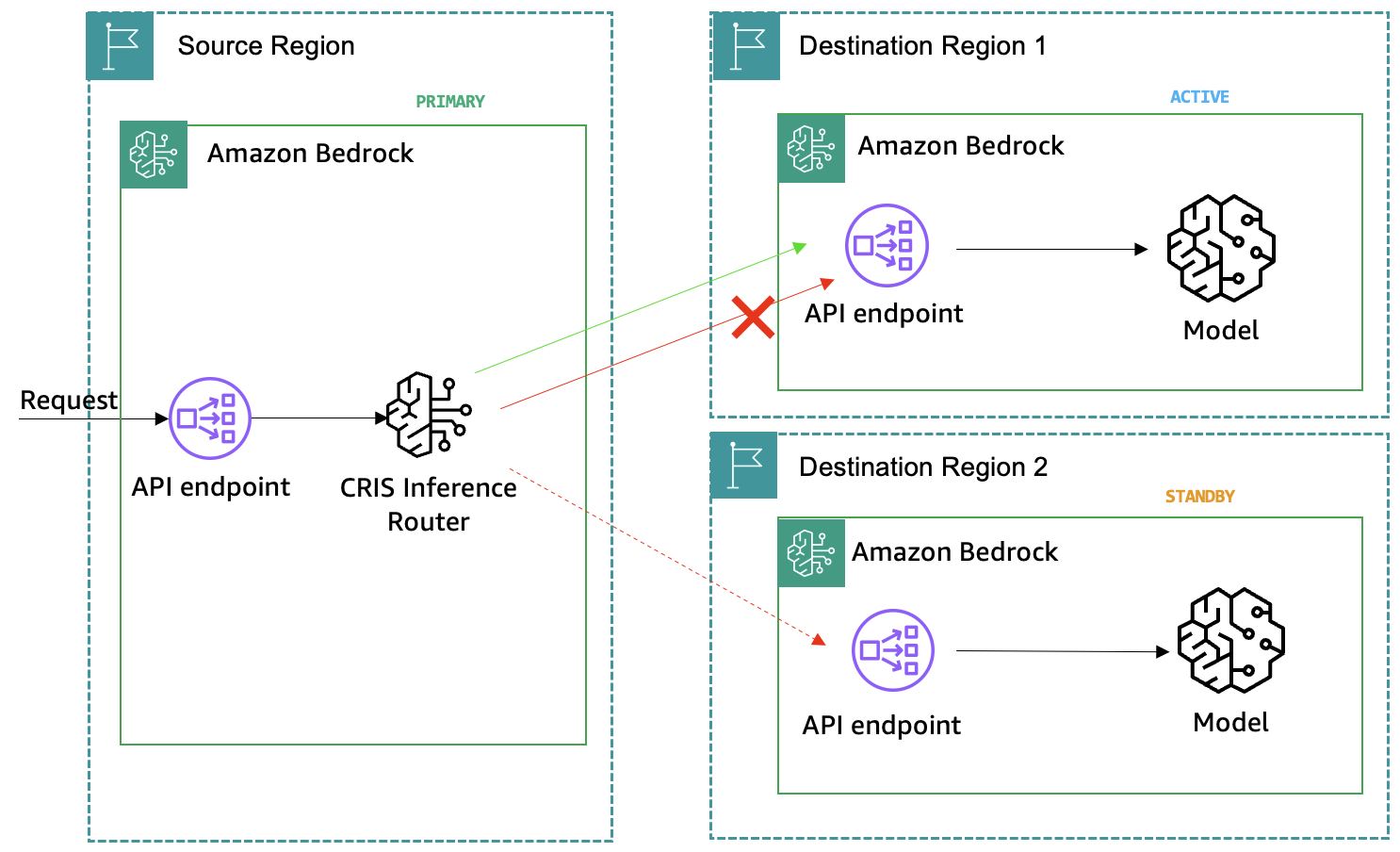
Implementing resilience patterns with Amazon Bedrock and LLM gateway
Implementing resilience patterns for large language model (LLM) inference is critical as generative AI workloads move from experimentation to production at scale. With LLM powered apps now in production, organizations need ways to keep LLM inference highly available, responsive, and cost-effective at scale. Existing resilience best practices like static stability and implementing backoffs and retries […]
Implementing resilience patterns with Amazon Bedrock and LLM gateway Read More »