
Create new worlds in Project Genie with these 4 tips
Learn more about Google DeepMind’s Project Genie and how to write prompts to create your own worlds.
Learn more about Google DeepMind’s Project Genie and how to write prompts to create your own worlds.

Gemini 3.1 Flash-Lite is our fastest and most cost-efficient Gemini 3 series model yet.

In this first post in a two-part series, we examine how retailers can implement a virtual try-on to improve customer experience. In part 2, we will further explore real-world applications and benefits of this innovative technology. Every fourth piece of clothing bought online is returned to the retailer, feeding into America’s $890 billion returns problem …
Building a scalable virtual try-on solution using Amazon Nova on AWS: part 1 Read More »
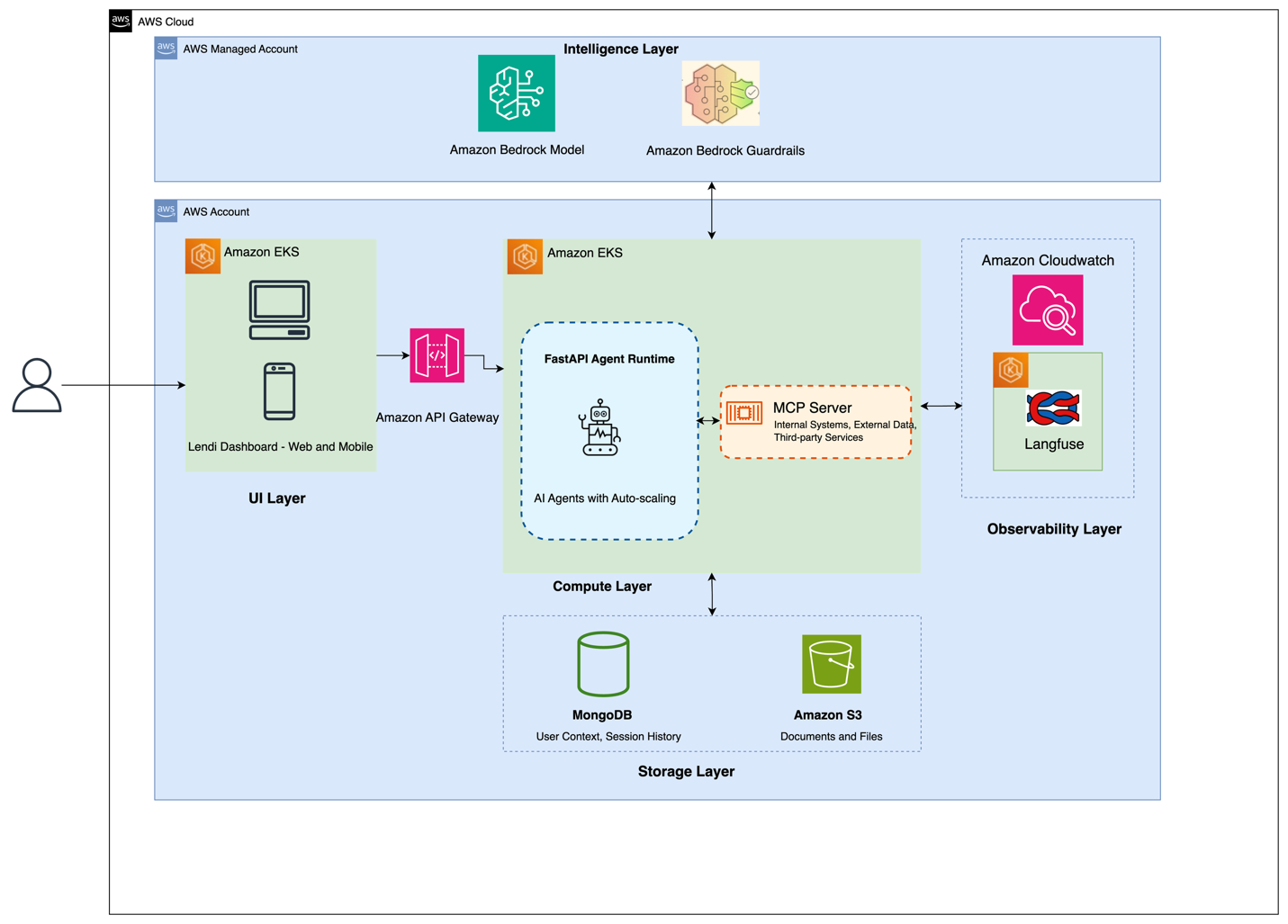
This post was co-written with Davesh Maheshwari from Lendi Group and Samuel Casey from Mantel Group. Most Australians don’t know whether their home loan is still competitive. Rates shift, property values move, personal circumstances change—yet for the average homeowner, staying informed of these changes is difficult. It’s often their largest financial commitment, but it’s also …
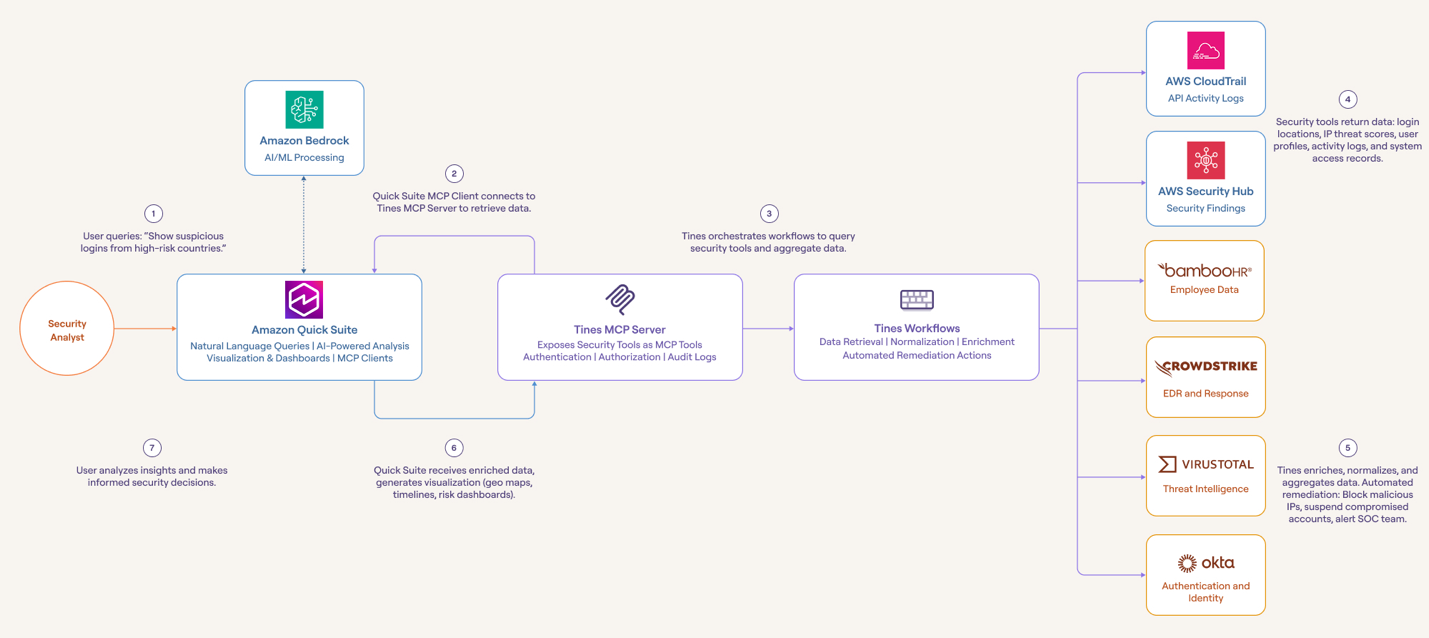
Organizations face challenges in quickly detecting and responding to user account security events, such as repeated login attempts from unusual locations. Although security data exists across multiple applications, manually correlating information and making corrective actions often delays effective response. With Amazon Quick Suite and Tines, you can automate the investigation and remediation process by integrating …
How Tines enhances security analysis with Amazon Quick Suite Read More »
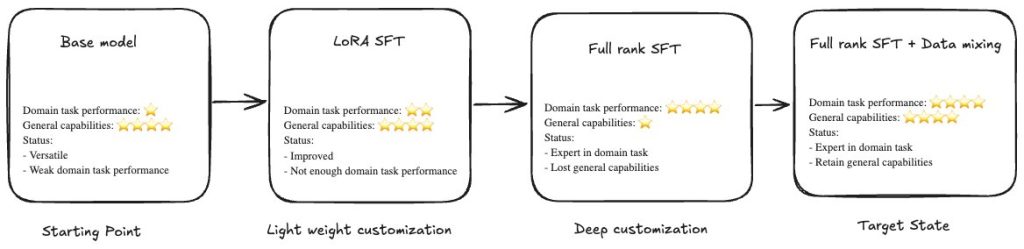
Large language models (LLMs) perform well on general tasks but struggle with specialized work that requires understanding proprietary data, internal processes, and industry-specific terminology. Supervised fine-tuning (SFT) adapts LLMs to these organizational contexts. SFT can be implemented through two distinct methodologies: Parameter-Efficient Fine-Tuning (PEFT), which updates only a subset of model parameters, offering faster training …
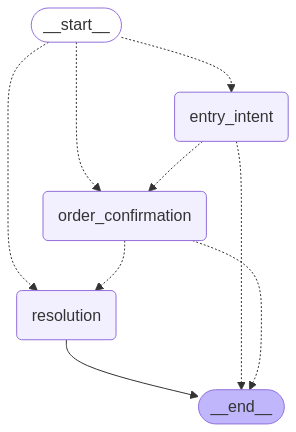
Customer service teams face a persistent challenge. Existing chat-based assistants frustrate users with rigid responses, while direct large language model (LLM) implementations lack the structure needed for reliable business operations. When customers need help with order inquiries, cancellations, or status updates, traditional approaches either fail to understand natural language or can’t maintain context across multistep …

Are you struggling to balance generative AI safety with accuracy, performance, and costs? Many organizations face this challenge when deploying generative AI applications to production. A guardrail that’s too strict blocks legitimate user requests, which frustrates customers. One that’s too lenient exposes your application to harmful content, prompt attacks, or unintended data exposure. Finding the …

Google is partnering with the Massachusetts AI Hub to provide every Baystater with no-cost access to Google’s AI training.

There’s a lot of excitement right now about AI enabling mainframe application modernization. Boards are paying attention. CIOs are getting asked for a plan. AI is a genuine accelerator for COBOL modernization but to get results, AI needs additional context that source code alone can’t provide.Here’s what we’ve learned working with 400+ enterprise customers: mainframe …
Learnings from COBOL modernization in the real world Read More »