Video semantic search is unlocking new value across industries. The demand for video-first experiences is reshaping how organizations deliver content, and customers expect fast, accurate access to specific moments within video. For example, sports broadcasters need to surface the exact moment a player scored to deliver highlight clips to fans instantly. Studios need to find every scene featuring a specific actor across thousands of hours of archived content to create personalized trailers and promotional content. News organizations need to retrieve footage by mood, location, or event to publish breaking stories faster than competitors. The goal is the same: deliver video content to end users quickly, capture the moment, and monetize the experience.
Video is naturally more complex than other modalities like text or image because it amalgamates multiple unstructured signals: the visual scene unfolding on screen, the ambient audio and sound effects, the spoken dialogue, the temporal information, and the structured metadata describing the asset. A user searching for “a tense car chase with sirens” is asking about a visual event and an audio event at the same time. A user searching for a specific athlete by name may be looking for someone who appears prominently on screen but is never spoken aloud.
The dominant approach today grounds all video signals into text, whether through transcription, manual tagging, or automated captioning, and then applies text embeddings for search. While this works for dialogue-heavy content, converting video to text inevitably loses critical information. Temporal understanding disappears, and transcription errors emerge from visual and audio quality issues. What if you had a model that could process all modalities and directly map them into a single searchable representation without losing detail? Amazon Nova Multimodal Embeddings is a unified embedding model that natively processes text, documents, images, video, and audio into a shared semantic vector space. It delivers leading retrieval accuracy and cost efficiency.
In this post, we show you how to build a video semantic search solution on Amazon Bedrock using Nova Multimodal Embeddings that intelligently understands user intent and retrieves accurate video results across all signal types simultaneously. We also share a reference implementation you can deploy and explore with your own content.
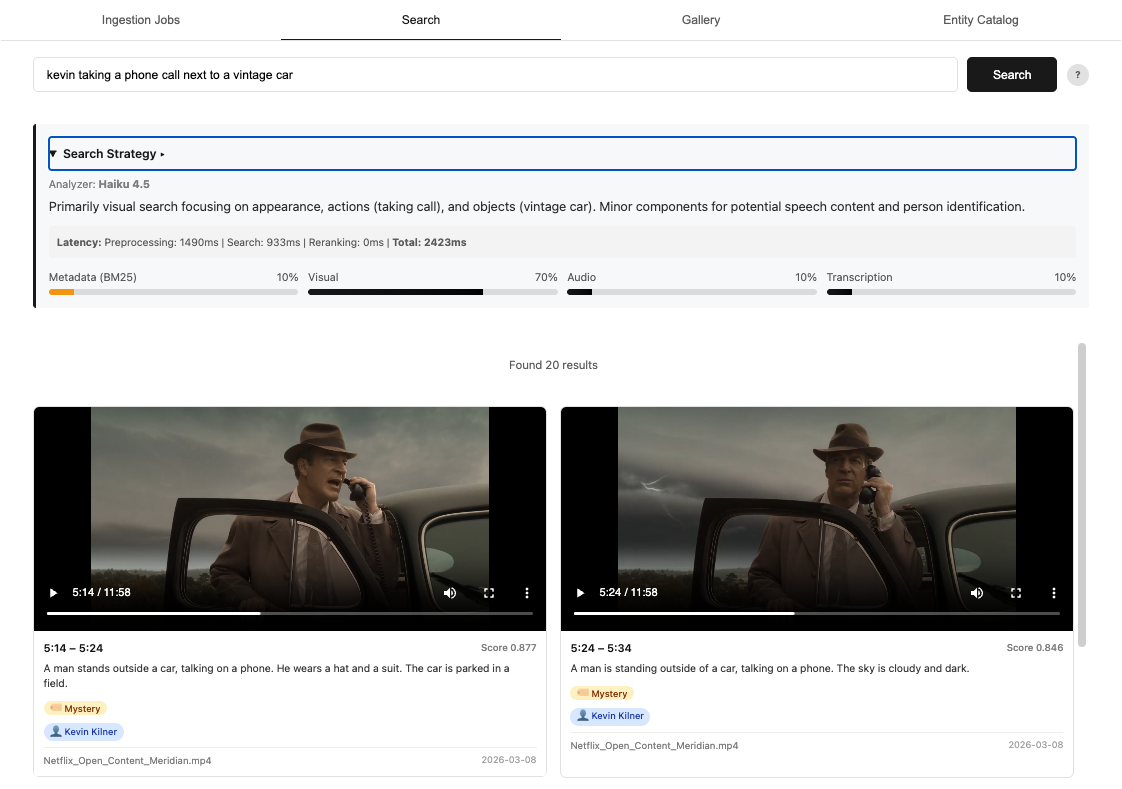
Figure 1: Example screenshot from final search solution
Solution overview
We built our solution on Nova Multimodal Embeddings combined with an intelligent hybrid search architecture that fuses semantic and lexical signals across all video modalities. Lexical search matches exact keywords and phrases, while semantic search understands meaning and context. We will explain our choice of this hybrid approach and its performance benefits in later sections.
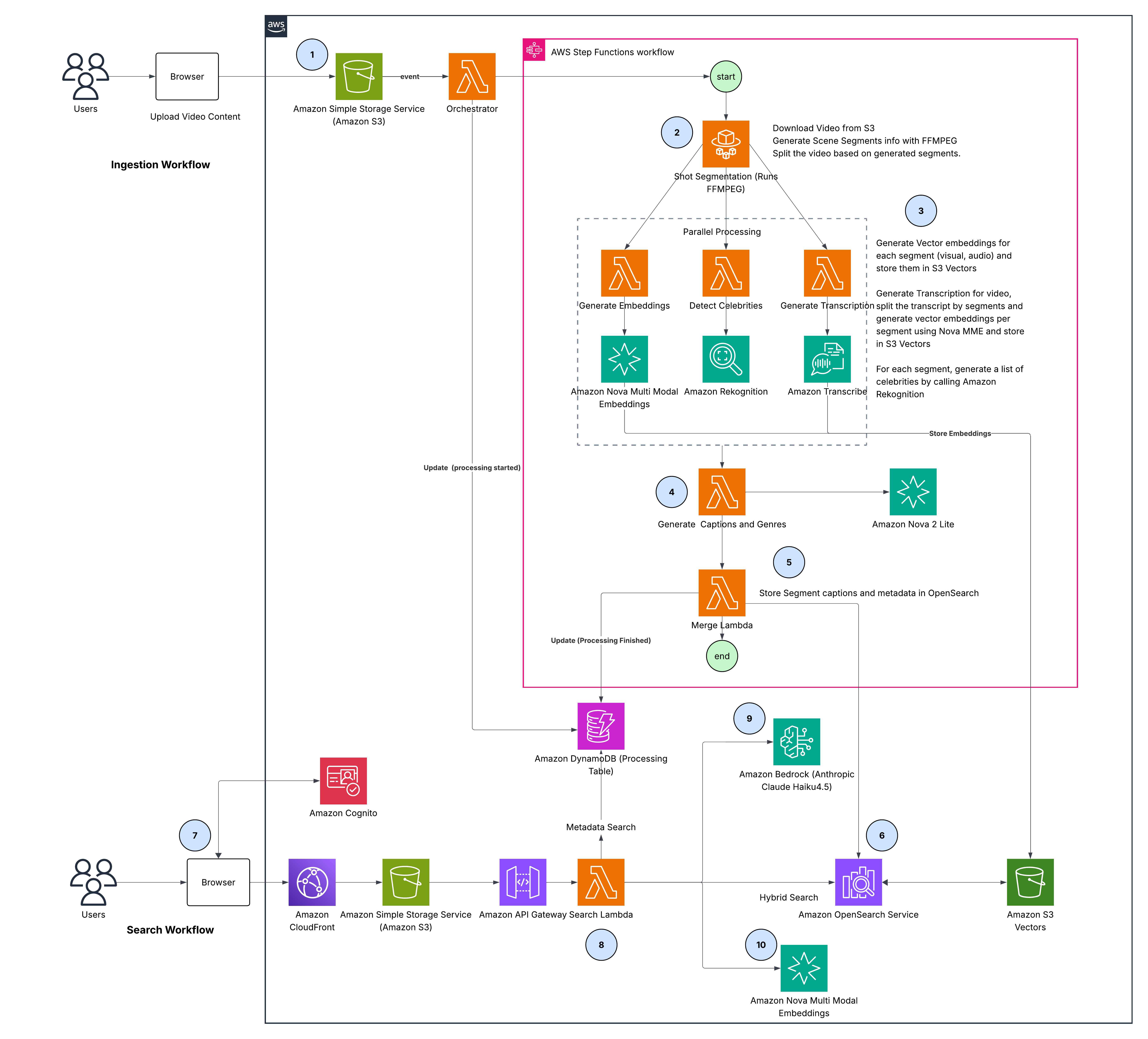
Figure 2: End-to-end solution architecture
The architecture consists of two phases: an ingestion pipeline (steps 1-6) that processes video into searchable embeddings, and a search pipeline (steps 7-10) that routes user queries intelligently across those representations and merges results into a ranked list. Here are details for each of the steps:
- Upload – Videos uploaded via browser are stored in Amazon Simple Storage Service (Amazon S3), triggering the Orchestrator AWS Lambda to update Amazon DynamoDB status and start the AWS Step Functions pipeline
- Shot segmentation – AWS Fargate uses FFmpeg scene detection to split video into semantically coherent segments
- Parallel processing – Three concurrent branches process each segment:
- Embeddings: Nova Multimodal Embeddings generates 1024-dimensional vectors for visual and audio, stored in Amazon S3 Vectors
- Transcription: Amazon Transcribe converts speech to text, aligned to segments. Amazon Nova Multimodal Embeddings generates text embeddings stored in Amazon S3 Vectors
- Celebrity detection: Amazon Rekognition identifies known individuals, mapped to segments by timestamp
- Caption & genre generation – Amazon Nova 2 Lite synthesizes segment-level captions and genre labels from visual content and transcripts
- Merge – AWS Lambda assembles all metadata (captions, transcripts, celebrities, genre) and retrieves embeddings from Amazon S3 Vectors
- Index – Complete segment documents with metadata and vectors that are bulk-indexed into Amazon OpenSearch Service
- Authentication – Users authenticate via Amazon Cognito and access the front end through Amazon CloudFront
- Query processing – Amazon API Gateway routes requests to Search Lambda, which executes two parallel operations: intent analysis and query embedding
- Intent analysis – Amazon Bedrock (using Anthropic Claude Haiku) assigns relevance weights (0.0-1.0) across visual, audio, transcription, and metadata modalities
- Query embedding – Nova Multimodal Embeddings embeds the query three times for visual, audio, and transcription similarity search
This flexible architecture addresses four key design decisions that most video search systems overlook: maintaining temporal context, handling multimodal queries, scaling across massive content libraries, and optimizing retrieval accuracy. A complete reference implementation is available on GitHub, and we encourage you to follow along with the following walkthrough to see how each decision contributes to accurate, scalable search across all signal types.
Segmentation for context continuity
Before generating any embeddings, you need to divide your video into searchable units, and the boundaries you draw have a direct impact on search accuracy. Each segment becomes the atomic unit of retrieval. If a segment is too short, it loses the surrounding context that gives a moment its meaning. If it is too long, it fuses multiple topics or scenes together, diluting relevance and making it harder for the search system to surface the right moment. For simplicity, you can start with fixed-length chunks. Nova Multimodal Embeddings supports up to 30 seconds per embedding, giving you flexibility to capture complete scenes. However, be aware that fixed boundaries may arbitrarily truncate a scene mid-action or split a sentence mid-thought, disrupting the semantic meaning that makes a moment retrievable, as shown in the following figure.

Figure 3: Video segmentation strategies
The goal is semantic continuity: each segment should represent a coherent unit of meaning rather than an arbitrary slice of time. Fixed 10-second blocks are straightforward to produce, but they ignore the natural structure of the content. A scene change mid-segment splits a visual idea across two chunks, degrading both retrieval precision and embedding quality.
To solve this, we use FFmpeg‘s scene detection to identify where the visual content actually changes. FFmpeg is an open source multimedia framework widely used for video processing, format conversion, and analysis. The _detect_scenes function that follows runs ffprobe (FFmpeg’s associated tool for media inspection) against the video and returns a list of timestamps, each marking a scene boundary:
The output is a simple list of timestamps like 12.345, 28.901, 45.678, each marking a natural boundary where the scene shifts.
With those boundaries in hand, the segmentation algorithm snaps each cut to the nearest scene change within an acceptable window, targeting around 10 seconds with a minimum of 5 seconds and a maximum of 15 seconds from the current start. If no scene changes fall in that range, it falls back to a hard cut at the target duration. The result is a set of segments that feel natural: 8.3s, 11.1s, 9.8s, 12.4s, 7.6s, each aligned to a real scene boundary rather than a fixed ticker.
This simple shot-based segmentation makes sure segment boundaries align with natural visual transitions rather than cutting arbitrarily. The target segment duration should be calibrated based on your content type and use case: action-heavy content with frequent cuts may benefit from visual segmentation like this, while documentary or interview content with longer takes may work better with longer, topic-based segmentation. For more advanced segmentation techniques, including audio-based topic segmentation and combined visual and audio approaches, we recommend reading Media2Cloud on AWS Guidance: Scene and Ad-Break Detection and Contextual Understanding for Advertising Using Generative AI.
Generate separate embeddings for visual, audio, and transcript signals
With segments defined, the choice of embedding model is where the largest quality gap opens between approaches. The dominant approach today grounds all video signals into text before generating embeddings, but as we established earlier, video carries far more meaning than any transcript or caption can express. Visual action, ambient sound, on-screen text, and entity context are either lost entirely or approximated through imprecise descriptions.
Nova Multimodal Embeddings changes this fundamentally because it is a video-native model that can generate embeddings in two modes. The combined mode fuses visual and audio signals into a unified representation, capturing the most important signals together. This approach benefits storage cost and retrieval latency by requiring only a single embedding per segment. Alternatively, the AUDIO_VIDEO_SEPARATE mode generates distinct visual and audio embeddings. This approach provides maximum representation in modality-specific embeddings and gives you better control over when to search visual content versus audio content.
In our implementation, we even added a third speech embedding derived from Amazon Transcribe. This embedding is created from aligning complete sentence transcripts to the embedding segment timestamps, before and after, preserving the semantic integrity of spoken language and ensuring that a complete thought is never split across two embeddings.
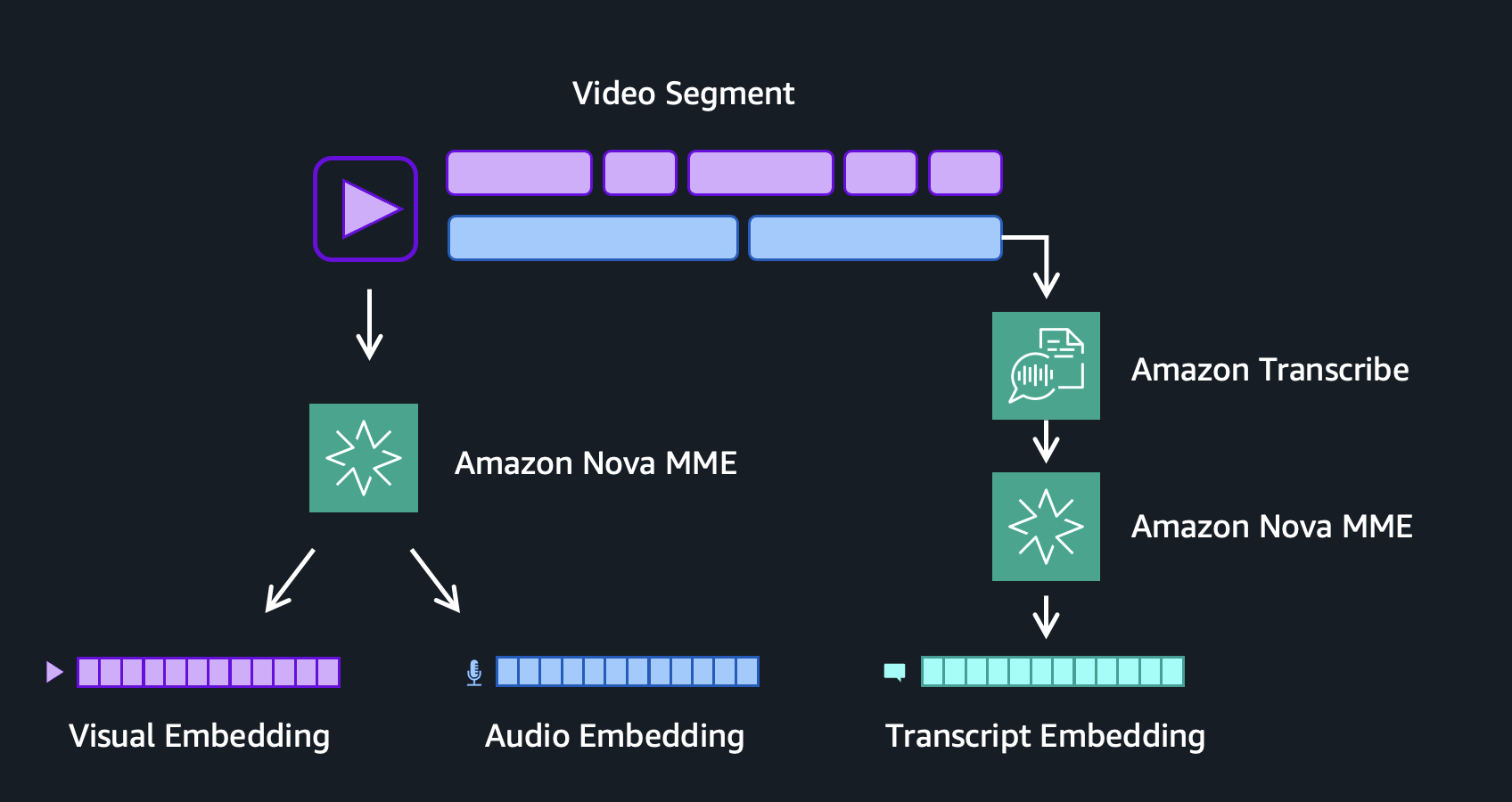
Figure 4: Visual, audio, and speech embedding generation per video segment
Together, these three embeddings cover the full signal space of a video segment. The visual embedding captures what the camera sees: objects, scenes, actions, colors, and spatial composition. The audio embedding captures what the microphone hears: music, sound effects, ambient noise, and the acoustic texture of a scene. The transcript embedding captures what people say, representing the semantic meaning of spoken dialogue and narration. Collapsing all three signals into a single combined embedding compresses distinct modalities into one vector. This blurs the boundaries between what is seen, heard, and spoken, and loses the fine-grained detail that makes each signal useful on its own. Keeping them separate gives you precise control to dial each modality up or down based on query intent, allowing the search pipeline to match against the modality most likely to contain the answer.
Combine metadata and embeddings for hybrid search
Even with three independent embeddings covering visual, audio, and spoken content, there is still a class of queries the system cannot answer well. Embeddings are designed to capture semantic similarity. They excel at finding a “tense crowd moment” or a “sun setting over water” because those are concepts with rich visual and audio meaning. But when a user searches for a specific name, product model number, geolocation, or a particular date, embeddings will likely fail. These are discrete entities with little semantic signals on their own. This is where hybrid search comes in. Rather than relying on embeddings alone, the system runs two parallel retrieval paths as shown in the following figure: a semantic path that matches against your visual, audio, and transcript embeddings to capture conceptual similarity, and a lexical path that performs exact keyword and entity matching against structured metadata.
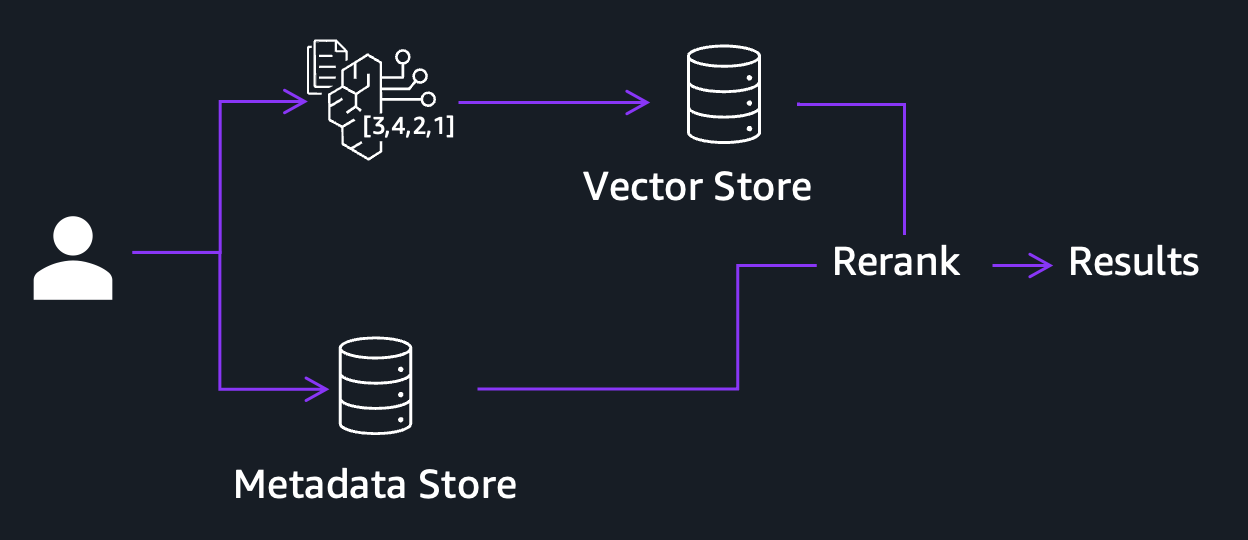
Figure 5: Hybrid search pipeline combining semantic and lexical retrieval
How much metadata do you need? The answer depends on your content type, organization, and use case, and capturing everything upfront is impractical. For illustration purposes, we selected a few categories of metadata to represent common types of metadata in media and entertainment content.
First, we selected video title and datetime to represent technical metadata extracted directly from the content catalog or file metadata. Then we added segment captions, genre, and celebrity recognition to represent contextual metadata, generated using Amazon Nova 2 Lite and Amazon Rekognition. Captions are generated from the video and transcript of each segment, giving the model both visual and spoken context. Genre is predicted from the full video transcript across all segments, which is cheaper and more reliable than re-sending all video clips. Celebrity identification is handled by Amazon Rekognition, which recognizes known public figures appearing on screen without requiring custom training.
Example prompts used for caption generation and genre classification are shown in the following examples:
The concept extends naturally to other metadata types. Technical metadata may include resolution or file size, while contextual metadata might include location, mood, or brand. The right balance depends on your search use case. Additionally, overlaying metadata filters during retrieval can further enhance search scalability and accuracy by narrowing the search space before semantic matching.
Optimize search relevance with intent-aware query routing
Now you have three embeddings and metadata, four searchable dimensions. But how do you know when to use which for a given query? Intent is everything. To solve this, we built an intelligent intent analysis router that uses the Haiku model to analyze each incoming query and assign weight to each modality channel: visual, audio, transcript, and metadata. See the example search query in the following figure.
“Kevin taking a phone call next to a vintage car”
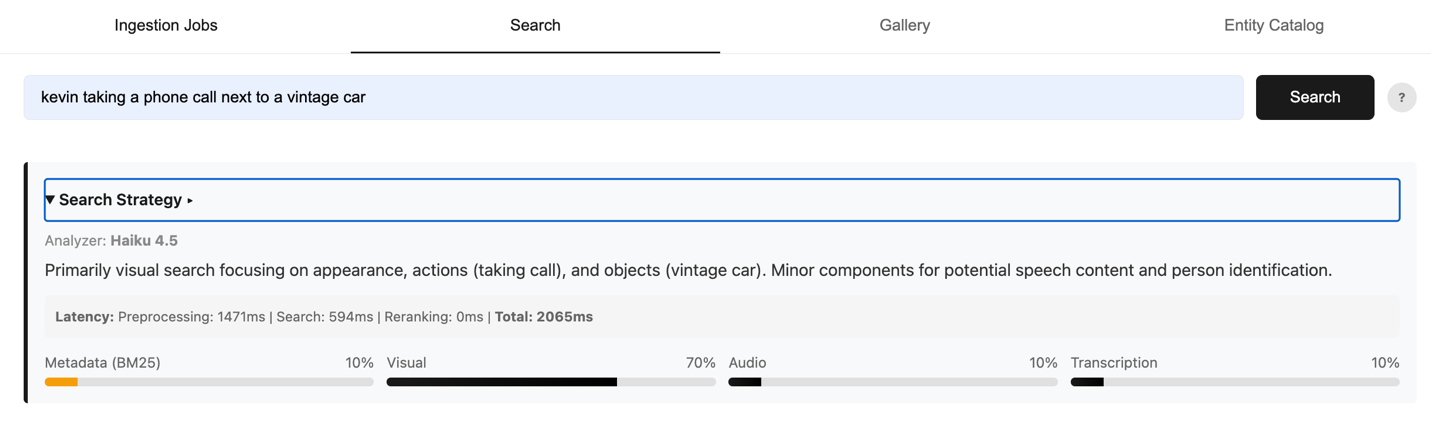
Figure 6: Example query with intelligently weights assigned based on search intent
The Haiku model is prompted to return a JSON object with weights that sum to 1.0, along with a brief reasoning trace explaining the assignment. See the following prompt:
The weights directly control which sub-queries execute. Any modality below a 5% weight threshold is skipped entirely, eliminating unnecessary embedding API calls and reducing search latency without sacrificing accuracy. The remaining channels execute in parallel, each searching its own index independently. Results from all active channels are then scored using a weighted arithmetic mean. BM25 scores (a lexical relevance measure based on term frequency and document length) and cosine similarity scores (a geometric measure of how closely two embedding vectors point in the same direction) live on very different scales. To address this, each sub-query’s scores are first normalized to a 0-1 range, then combined using the router’s intent weights:
We chose the weighted arithmetic mean as our reranking technique because it directly incorporates query intent through the router’s weights. Unlike Reciprocal Rank Fusion (RRF), which treats all active channels equally regardless of intent, the weighted mean amplifies channels the router deems most relevant for a given query. From our testing, this produced more accurate results for our search tasks.
Choose the right storage strategy for vectors and metadata
The final design decision is where and how to store it all. Each video segment produces up to three embeddings and a set of metadata fields, and how you store them determines both your search performance and your cost at scale. We split this across two services with complementary roles: Amazon S3 Vectors for vector storage, and Amazon OpenSearch Service for hybrid search.
S3 Vectors stores three vector indices per project, one for each embedding type:
nova-visual-{project_id}# visual embeddingsnova-audio-{project_id}# audio embeddingsnova-transcription-{project_id}# transcript embeddings
OpenSearch holds one index per project, where each document represents a single video segment containing both text fields for BM25 search and vector fields for k-nearest neighbors (kNN) search:
We chose S3 Vectors for its cost-to-performance benefits. Amazon S3 Vectors reduces the cost for storing and querying vectors by up to 90% compared to alternative specialized solutions. If search latency is not critical for your use case, S3 Vectors is a strong default choice. If you need the lowest possible latency, we recommend using vectors in memory with the OpenSearch Hierarchical Navigable Small World (HNSW) engine.
Finally, it is worth calling out that some use cases require searching within longer, semantically dense video segments such as a full interview, a multi-minute documentary scene, or an extended product demonstration. Most multimodal embedding models, including Nova Multimodal Embeddings, have a maximum input duration of 30 seconds, which means a 3-minute clip cannot be embedded as a single unit. Attempting to do so would either fail or force chunking that loses the broader context.
The nested vector support in OpenSearch addresses this by allowing a single document to contain multiple sub-segment embeddings:
At query time, OpenSearch scores the document based on the best-matching sub-segment rather than a single averaged representation, so a long scene can match a specific visual moment within it while still being returned as one coherent result.
Performance results: How the optimized approach outperforms the baseline
To validate our design decisions, we benchmarked the optimized hybrid search against Nova Multimodal Embeddings baseline AUDIO_VIDEO_COMBINED mode using 10 internal long-form videos (5-20 minutes) evaluated across 20 queries spanning visual, audio, transcript, and metadata-focused searches. The baseline uses a single unified vector per 10-second segment with one index and one kNN query. Our optimized approach generates separate visual, audio, and transcript embeddings, enriches segments with structured metadata, and applies intent-aware routing that dynamically weights modality channels. The following figure shows results across four standard retrieval metrics:
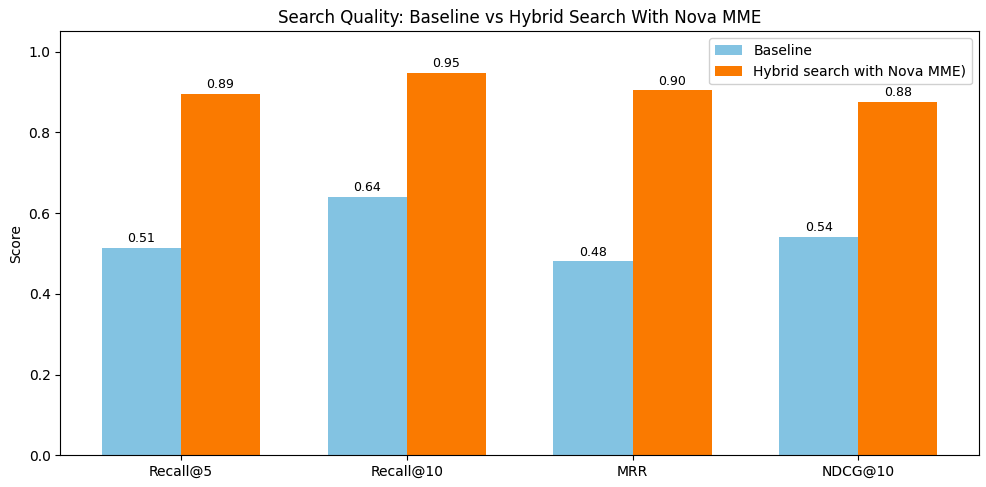
Figure 7: Performance Comparison Across Retrieval Metrics for Hybrid Search with Nova MME vs. Baseline
The following table captures key metrics:
| Recall@5 | Recall@10 | MRR | NDCG@10 | |
| Hybrid search W/ Nova Multimodal Embeddings | 90% | 95% | 90% | 88% |
| Baseline | 51% | 64% | 48% | 54% |
Key metrics explained:
- Recall@5: Of all relevant segments, what fraction appears in the top 5 results? This means the coverage of the search results.
- Recall@10: Of all relevant segments, what fraction appears in the top 10 results? This means the coverage of the search results.
- MRR (Mean Reciprocal Rank): 1/rank of the first relevant result, averaged across queries. This measures how quickly you find something relevant.
- NDCG@10: Normalized Discounted Cumulative Gain rewards relevant results ranked higher and penalizes those ranked lower. This is a standard ranking quality metric.
The results show substantial improvements across all metrics. The optimized hybrid search achieved 90+% Recall@5 and Recall@10 versus 51% and 64% for the baseline (~40% lift on coverage accuracy). MRR jumped from 48% to 90%, and NDCG@10 rose from 54% to 88%. These 30-40 percentage point gains validate our core architectural decisions: semantic segmentation preserves content continuity, separate embeddings provide precise search control, metadata enrichment captures factual entities, and intent-aware routing makes sure the right signals drive each query. By treating each modality independently while intelligently combining them based on query intent, the system adapts to diverse search patterns and delivers consistently relevant results as your video archive scales.
Clean up
To avoid incurring future charges, delete the resources used in this solution by removing the AWS CloudFormation stack. For detailed commands, refer to the GitHub repository.
Conclusion
In this post, we showed how to build a video semantic search solution on AWS using Nova Multimodal Embeddings, covering four key design decisions: segmentation for semantic continuity, multimodal embeddings that capture visual, audio, and speech signals independently, metadata that fills the precision gap for entity-specific queries, and a data structure that organizes everything for efficient retrieval at scale. Together with an intelligent intent analysis router and weighted reranking, these decisions transform a fragmented set of signals into a unified, accurate search experience that understands video. More optimizations can be done to further tune search accuracy, including model customization for the intent routing layer. Read Part 2 to go deeper on those techniques. For a production-ready implementation of this video search and metadata management technique at scale, see the Guidance for a Media Lake on AWS.
About the authors

