Foundation models deliver impressive out-of-the-box performance for general tasks, but many organizations need models to consume their business knowledge. Model customization helps you bridge the gap between general-purpose AI and your specific business needs when building applications that require domain-specific expertise, enforcing communication styles, optimizing for specialized tasks like code generation, financial reasoning, or ensuring compliance with industry regulations. The challenge lies in how to customize effectively. Traditional supervised fine-tuning delivers results, but only if you have thousands of carefully labeled examples showing not just the correct final answer, but also the complete reasoning path to reach it. For many real-world applications, especially those tasks where multiple valid solution paths exist, creating these detailed step-by-step demonstrations can sometimes be expensive, time-consuming.
In this post, we explore reinforcement fine-tuning (RFT) for Amazon Nova models, which can be a powerful customization technique that learns through evaluation rather than imitation. We’ll cover how RFT works, when to use it versus supervised fine-tuning, real-world applications from code generation to customer service, and implementation options ranging from fully managed Amazon Bedrock to multi-turn agentic workflows with Nova Forge. You’ll also learn practical guidance on data preparation, reward function design, and best practices for achieving optimal results.
A new paradigm: Learning by evaluation rather than imitation
What if you could teach a car to not only learn all the paths on a map, but to also learn how to navigate if a wrong turn is taken? That’s the core idea behind reinforcement fine-tuning (RFT), a model customization technique we’re excited to bring to Amazon Nova models. RFT shifts the paradigm from learning by imitation to learning by evaluation. Instead of providing thousands of labeled examples, you provide prompts and define what makes a final answer correct through test cases, verifiable outcomes, or quality criteria. The model then learns to optimize those criteria through iterative feedback, discovering its own path to correct solutions.
RFT supports model customization for code generation and math reasoning by verifying outputs automatically, eliminating the need for providing detailed step by step reasoning. We made RFT available across our AI services to meet you wherever you are in your AI journey: start simple with the fully-managed experience available in Amazon Bedrock, gain more control with SageMaker Training Jobs, scale to advanced infrastructure with SageMaker HyperPod, or unlock frontier capabilities with Nova Forge for multi-turn conversations and custom reinforcement learning environments.
In December 2025, Amazon launched the Nova 2 family—Amazon’s first models with built-in reasoning capabilities. Unlike traditional models that generate responses directly, reasoning models like Nova 2 Lite engage in step-by-step problem decomposition, performing intermediate thinking steps before producing final answers. This extended thinking process mirrors how humans approach complex analytical tasks. When combined with RFT, this reasoning capability becomes particularly powerful, RFT can optimize not just what answer the model produces, but how it reasons through problems, teaching it to discover more efficient reasoning paths while reducing token usage. As of today, RFT is only supported with text-only use cases.
Real-World Use Cases
RFT excels in scenarios where you can define and verify correct outcomes, but creating detailed step-by-step solution demonstrations at scale is impractical. Below are some of the use cases, where RFT can be a good option:
- Code generation: You want code that’s not just correct, but also efficient, readable, and handles edge cases gracefully, such as qualities you can verify programmatically through test execution and performance metrics.
- Customer service: You need to evaluate whether replies are helpful, maintain your brand’s voice, and strike the right tone for each situation. These are judgment calls that can’t be reduced to simple rules but can be assessed by an AI judge trained on your communication standards.
- Other applications: Content moderation, where context and nuance matter; multi-step reasoning tasks like financial analysis or legal document review; and tool usage, where you need to teach models when and how to call APIs or query databases. In each case, you can define and verify correct outcomes programmatically, even when you can’t easily demonstrate the step-by-step reasoning process at scale.
- Exploration-heavy problems: Use cases like game playing and strategy, resource allocation, and scheduling benefit from cases where the model uses different approaches and learns from feedback.
- Limited labeled data scenarios: Use cases where limited labeled datasets are available like domain-specific applications with few expert-annotated examples, new problem domains without established solution patterns, expensive-to-label tasks (medical diagnosis, legal analysis). In these use cases, RFT helps to optimize the rewards computed from the reward functions.
How RFT Works
RFT operates through a three-stage automated process (shown in Figure 1):
Stage 1: Response generation – The actor model (the model you’re customizing) receives prompts from your training dataset and generates multiple responses per prompt—typically 4 to 8 variations. This diversity gives the system a range of responses to evaluate and learn from.
Stage 2: Reward computation – Instead of comparing responses to labeled examples, the system evaluates quality using reward functions. You have two options:
- Reinforcement learning via verifiable rewards (RLVR): Rule-based graders implemented as AWS Lambda functions, perfect for objective tasks like code execution or math problem verification where you can programmatically check correctness.
- Reinforcement learning from AI feedback (RLAIF): AI-based judges that evaluate responses based on criteria you configure, ideal for subjective tasks like assessing helpfulness, creativity, or adherence to brand voice.
Stage 3: Actor model training – The system uses the scored prompt-response pairs to train your model through a reinforcement learning algorithm, like Group Relative Policy Optimization (GRPO), optimized for language models. The model learns to maximize the probability of generating high-reward responses while minimizing low-reward responses. This iterative process continues until the model achieves your desired performance.
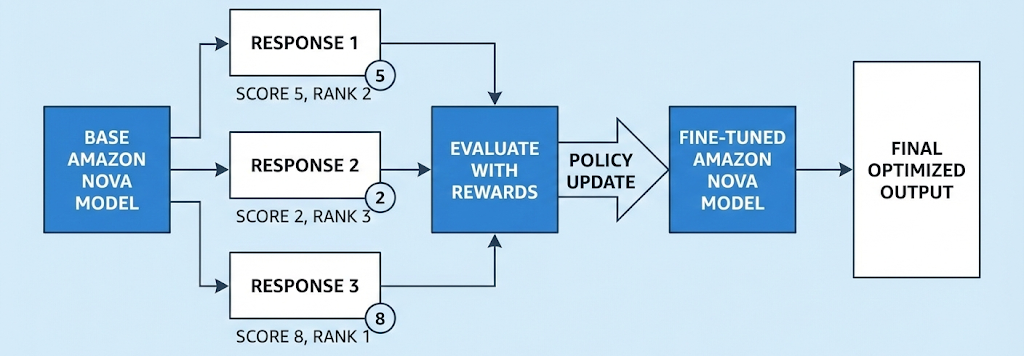
Figure 1: Illustration of how single pass of RFT works
Key Benefits of RFT
The following are the key benefits of RFT:
- No massive, labeled datasets required – RFT only needs prompts and a way to evaluate quality. If using Bedrock RFT, you can even leverage existing Bedrock API invocation logs as RFT data, eliminating the need for specially created datasets.
- Optimized for verifiable outcomes – Unlike supervised fine-tuning that requires explicit demonstrations of how to reach correct answers, RFT is optimized for tasks where you can define and verify correct outcomes, but multiple valid reasoning paths may exist.
- Reduced token usage – By optimizing the model’s reasoning process, RFT can reduce the number of tokens required to accomplish a task, lowering both cost and latency in production.
- Secure and monitored – Your proprietary data never leaves AWS’s secure environment during the customization process, and you get real-time monitoring of training metrics to track progress and ensure quality.
Implementation tiers: From simple to complex
Amazon offers multiple implementation paths for reinforcement fine-tuning with Nova models, ranging from fully managed experiences to customizable infrastructure. By following this tiered approach you can match your RFT implementation to your specific needs, technical expertise, and desired level of control.
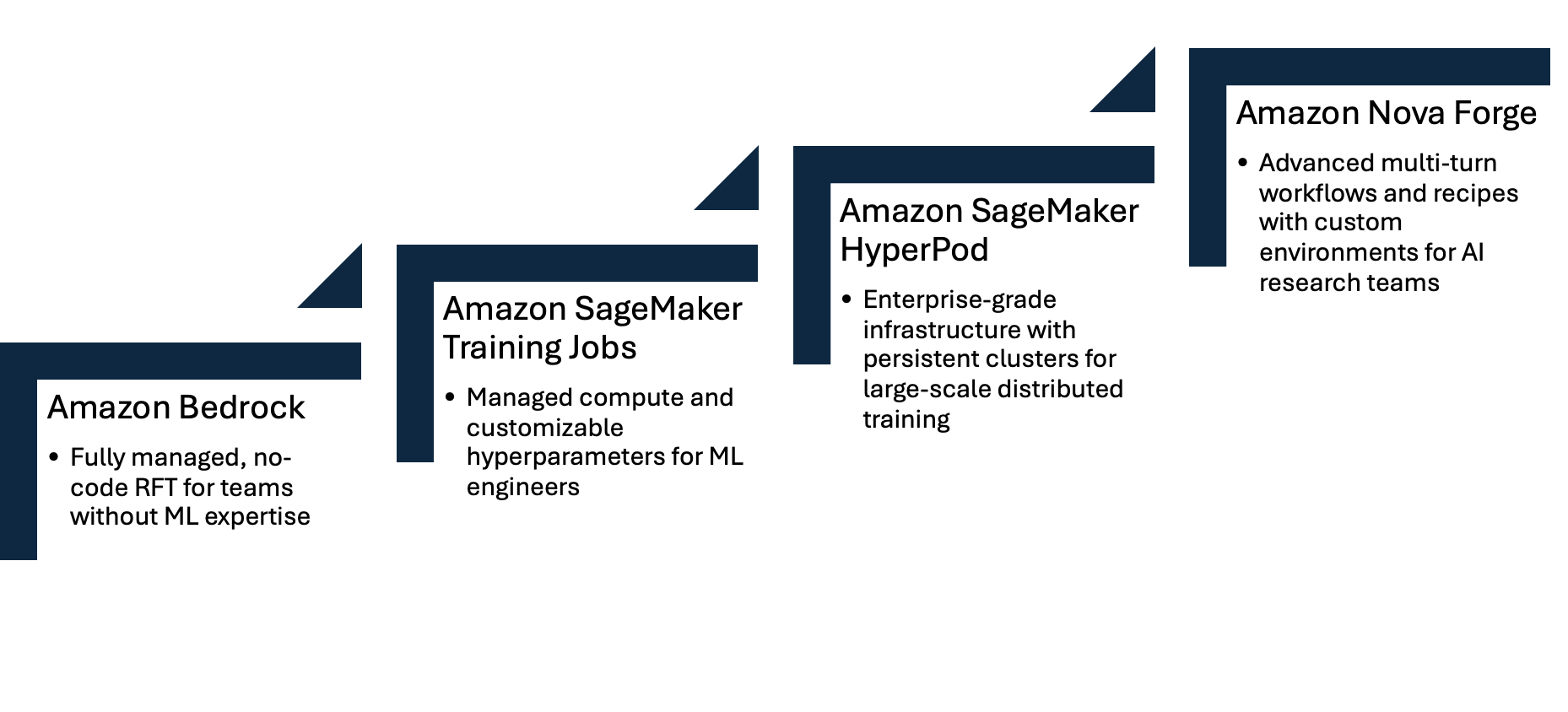
Amazon Bedrock
Amazon Bedrock provides an entry point to RFT with a fully managed experience that requires minimal ML expertise. Through the Amazon Bedrock console or API, you can upload your training prompts, configure your reward function as an AWS Lambda, and launch your reinforcement fine-tuning job with just a few clicks. Bedrock handles all infrastructure provisioning, training orchestration, and model deployment automatically. This approach works well for straightforward use cases where you need to optimize specific criteria without managing infrastructure. The simplified workflow makes RFT accessible to teams without dedicated ML engineers while still delivering powerful customization capabilities. Bedrock RFT supports both RLVR (rule-based rewards) and RLAIF (AI-based feedback) approaches, with built-in monitoring and evaluation tools to track your model’s improvement. To get started, see the Amazon Nova RFT GitHub repository.
SageMaker Training Jobs
For teams that need more control over the training process, Amazon SageMaker Training Jobs offer a flexible middle ground with managed compute and ability to tweak multiple hyperparameters. You can also save intermediate checkpoints and use them to create iterative training workflows like chaining supervised fine-tuning (SFT) and RFT jobs to progressively refine your model. You have the flexibility to choose between LoRA and full-rank training approaches, with full control over hyperparameters. For deployment, you can choose between Amazon Bedrock for fully managed inference or Amazon SageMaker endpoints where you control instance types, batching, and performance tuning. This tier is ideal for ML engineers and data scientists who need customization beyond Amazon Bedrock but don’t require dedicated infrastructure. SageMaker Training Jobs also integrate seamlessly with the broader Amazon SageMaker AI ecosystem for experiment tracking, model registry, and deployment pipelines. Amazon Nova RFT on SageMaker Training Job uses YAML recipe files to configure training jobs. You can obtain base recipes from the SageMaker HyperPod recipes repository.
Best practices:
- Data format: Use JSONL format with one JSON object per line.
- Reference answers: Include ground truth values that your reward function will compare against model predictions.
- Start small: Begin with 100 examples to validate your approach before scaling.
- Custom fields: Add any metadata your reward function needs for evaluation.
- Reward Function: Design for speed and scalability using AWS Lambda.
- To get started with Amazon Nova RFT job on Amazon SageMaker Training Jobs, see the SFT and RFT notebooks.
SageMaker HyperPod
SageMaker HyperPod delivers enterprise-grade infrastructure for large-scale RFT workloads with persistent Kubernetes-based clusters optimized for distributed training. This tier builds on all the features available in SageMaker Training Jobs—including checkpoint management, iterative training workflows, LoRA and full-rank training options, and flexible deployment— on a much larger scale with dedicated compute resources and specialized networking configurations. The RFT implementation in HyperPod is optimized for higher throughput and faster convergence through state-of-the-art asynchronous reinforcement learning algorithms, where inference servers and training servers work independently at full speed. These algorithms account for this asynchrony and implement cutting-edge techniques used to train foundation models. HyperPod also provides advanced data filters that give you granular control over the training process and reduce the chances of crashes. You gain granular control over hyperparameters to maximize throughput and performance. HyperPod is designed for ML platform teams and research organizations that need to push the boundaries of RFT at scale. Amazon Nova RFT uses YAML recipe files to configure training jobs. You can obtain base recipes from the SageMaker HyperPod recipes repository.
- For more information, see the RFT based evaluation to get started with Amazon Nova RFT job on Amazon SageMaker HyperPod.
Nova Forge
Nova Forge provides advanced reinforcement feedback training capabilities designed for AI research teams and practitioners in building sophisticated agentic applications. By breaking free from single-turn interaction and Lambda timeout constraints, Nova Forge enables complex, multi-turn workflows with custom-scaled environments running in your own VPC. This architecture gives you complete control over trajectory generation, reward functions, and direct interaction with training and inference servers capabilities essential for frontier AI applications that standard RFT tiers cannot support. Nova Forge uses Amazon SageMaker HyperPod as the training platform along with providing other features such as data mixing with the Amazon Nova curated datasets along with intermediate checkpoints.
Key Features:
- Multi-turn conversation support
- Reward functions with >15-minute execution time
- Additional algorithms and tuning options
- Custom training recipe modifications
- State-of-the-art AI techniques
Each tier in this progression builds on the previous one, offering a natural growth path as your RFT needs to evolve. Start with Amazon Bedrock for initial experiments, move to SageMaker Training Jobs as you refine your approach, and graduate to HyperPod or Nova Forge using HyperPod for specialized use cases. This flexible architecture ensures you can implement RFT at the level of complexity that matches your current needs while providing a clear path forward as those needs grow.
Systematic approach to reinforcement fine-tuning (RFT)
Reinforcement fine-tuning (RFT) progressively improves pre-trained models through structured, reward-based learning iterations. The following is a systematic approach to implementing RFT.
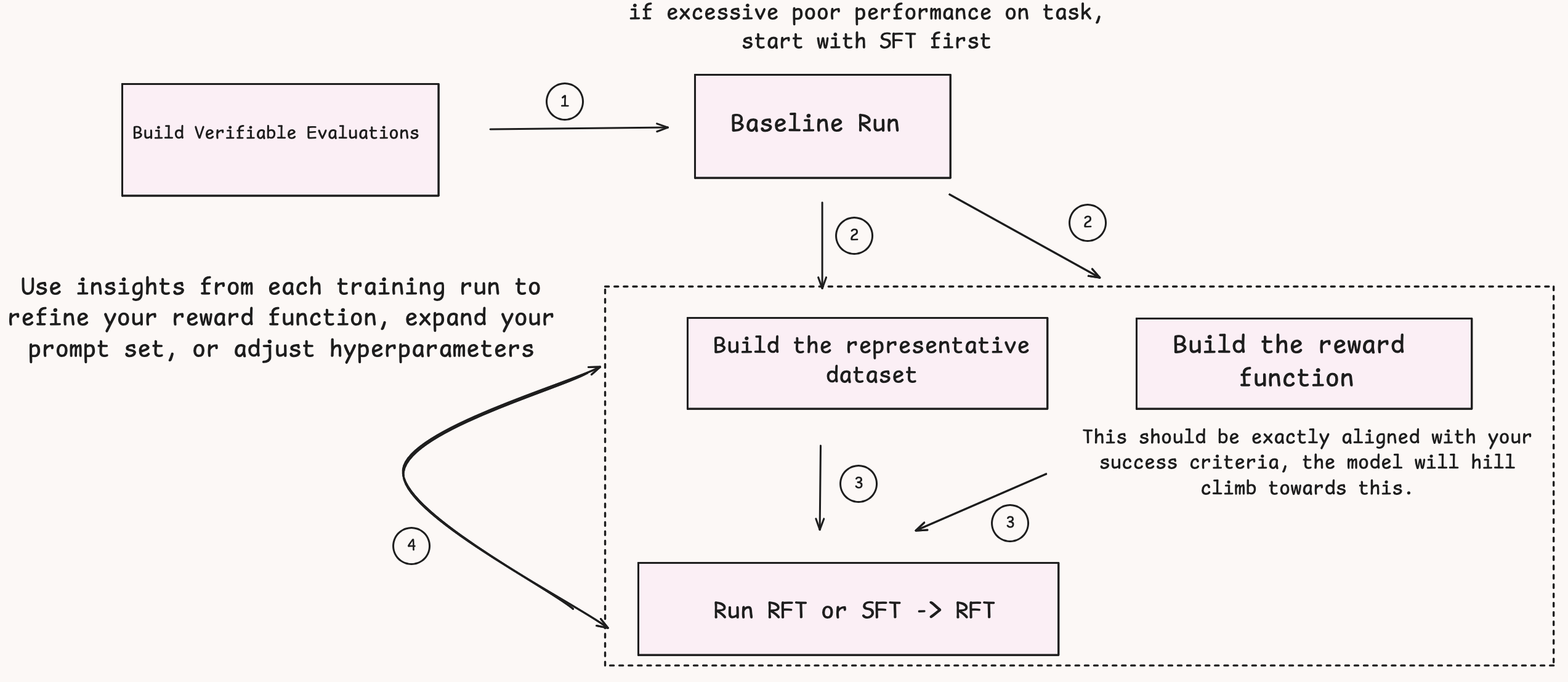
Step 0: Evaluate baseline performance
Before starting RFT, evaluate whether your model performs at a minimally acceptable level. RFT requires that the model can produce at least one correct solution among several attempts during training.
Key requirement: Group relative policies require outcome diversity across multiple rollouts (typically 4-8 generations per prompt) to learn effectively. The model needs at least one success or at least one failure among the attempts so it can distinguish between positive and negative examples for reinforcement. If all rollouts consistently fail, the model has no positive signal to learn from, making RFT ineffective. In such cases, you should first use supervised fine-tuning (SFT) to establish basic task capabilities before attempting RFT. In cases where the failure modes are primarily due to lack of knowledge, in those cases as well SFT might be more effective starting point, whereas if the failure modes are due to poor reasoning, then RFT might be a better option to optimize on reasoning quality.
Step 1: Identify the right dataset and reward function
Select or create a dataset of prompts that represent the scenarios your model will encounter in production. More importantly, design a reward function that:
- Crisply follows what your evaluation metrics track: Your reward function should directly measure the same qualities you care about in production.
- Captures what you need from the model: Whether that’s correctness, efficiency, style adherence, or a combination of objectives.
Step 2: Debug and iterate
Monitor training metrics and model rollouts throughout the training process
Training metrics to watch:
- Reward trends over time (should generally increase)
- Policy divergence (KL) from the base model
- Generation length over time
Model rollout analysis:
- Sample and review generated outputs at regular intervals
- Track how the model’s behavior evolves across training steps
Common issues and solutions
Issues solvable directly in the reward function:
- Format correctness: Add reward penalties for malformed outputs
- Language mixing: Penalize unwanted language switches
- Generation length: Reward appropriate response lengths for your use case
Issues requiring dataset/prompt improvements:
- Limited coverage: Create a more comprehensive prompt set covering various difficulty
- Lack of exploration diversity: Ensure prompts allow the model to explore diverse scenarios and edge cases
RFT is an iterative process. Use insights from each training run to refine your reward function, expand your prompt set, or adjust hyperparameters before the next iteration.
Key RFT features and when to choose what
This section outlines the key features of RFT through a systematic breakdown of its core components and capabilities for effective model optimization.
Full Rank compared to LoRA
RFT supports two training approaches with different resource tradeoffs. Full Rank training updates all model parameters during training, providing maximum model adaptation potential but requiring more computational resources and memory. Low-Rank Adaptation (LoRA) offers parameter-efficient fine-tuning that updates only a small subset of parameters through lightweight adapter layers while keeping most of the model frozen.
LoRA requires significantly less computational resources and results in smaller model artifacts. Importantly, LoRA models deployed in Amazon Bedrock support on-demand inference—you don’t need dedicated instances and only pay for the tokens you use. This makes LoRA an excellent default starting point: you can quickly iterate and validate your customized model without upfront infrastructure costs. As your traffic demand grows or high-performance requirements justify the investment, you can transition to full rank training with dedicated provisioned throughput instances for maximum throughput and lowest latency.
Reasoning compared to non-reasoning
RFT supports both reasoning and non-reasoning models, each optimized for different types of tasks. Reasoning models generate explicit intermediate thinking steps before producing final answers, making them ideal for complex analytical tasks like mathematical problem-solving, multi-step logical deduction, and code generation where showing the reasoning process adds value. You can configure reasoning effort levels—high for maximum reasoning capability or low for minimal overhead. Non-reasoning models provide direct responses without showing intermediate reasoning steps, optimizing speed and cost. They’re best suited for tasks like chat-bot style Q&A where you want faster execution without the reasoning overhead, though this may result in lower quality outputs compared to reasoning mode. The choice depends on your task requirements: use reasoning mode when the intermediate thinking steps improve accuracy, and you need maximum performance on complex problems. Use non-reasoning mode when you prioritize speed and cost efficiency over the potential quality improvements that explicit reasoning provides.
When to Use RFT compared to SFT
| Method | When it works best | Strengths | Limitations |
| Supervised fine‑tuning (SFT) | Well‑defined tasks with clear desired outputs, for example, “Given X, the correct output is Y.” | • Directly teaches factual knowledge (for example, “Paris is the capital of France”) • Ideal when you have high‑quality prompt‑response pairs • Provides consistent formatting and specific output structures | • Requires explicit, labeled examples for every desired behavior • May struggle with tasks that involve ambiguous or multiple valid solutions |
| Reinforcement fine‑tuning (RFT) | Scenarios where a reward function can be defined, even if only one valid solution exists | • Optimizes complex reasoning tasks • Generates its own training data efficiently, reducing the need for many human‑labeled examples • Allows balancing competing objectives (accuracy, efficiency, style) | • Needs the model to produce at least one correct solution among several attempts (typically 4‑8) • If the model consistently fails to generate correct solutions, RFT alone will not be effective |
Case study: Financial Analysis Benchmark (FinQA) optimization with RFT
In this case study, we will walk users through an example case study of FinQA, a financial analysis benchmark, and use that to demonstrate the optimization achieved in responses. In this example we will use 1000 samples from the FinQA public dataset.
Step 1: Data preparation
Prepare the dataset in a format that’s compatible with RFT schema as mentioned RFT on Nova. RFT data follows the OpenAI conversational format. Each training example is a JSON object containing. For our FinQA dataset, post formatting an example data point in train.jsonl will look as shown below:
Required fields:
- messages: Array of conversational turns with system, user, and optionally assistant roles
- reference_answer: Expected output or evaluation criteria for reward calculation
Optional fields:
- id: Unique identifier for tracking and deduplication
- tools: Array of function definitions available to the model
- Custom metadata fields: Any additional metadata to be used while calculating rewards (for example,
task_id,difficulty_level,domain)
Step 2: Building the reward and grader function
The reward function is the core component that evaluates model responses and provides feedback signals for training. It must be implemented as an AWS Lambda function that accepts model responses and returns reward scores. Currently, AWS Lambda functions come with a limitation of up to 15 minutes execution time. Adjust the timeout of the Lambda function based on your needs.
Best practices:
The following are the recommendations to optimize your RFT implementation:
- Start small: Begin with 100-200 examples and few training epochs.
- Baseline with SFT first: If reward scores are consistently low, perform SFT before RFT.
- Design efficient reward functions: Execute in seconds, minimize external API calls.
- Monitor actively: Track average reward scores, watch for overfitting.
- Optimize data quality: Ensure diverse, representative examples.
Step 3: Launching the RFT job
Once we have data prepared, we will launch RFT using a SageMaker Training Jobs. The two key inputs for launching the RFT job are the input dataset (input_data_s3) and the reward function Lambda ARN. Here we use the RFT container and RFT recipe as defined in the following example. The following is a snippet of how you can kick off the RFT Job: rft_training_job =rft_launcher(train_dataset_s3_path, reward_lambda_arn)
Function:
Note: To lower the cost of this experiment, you can set instance count to 2 instead of 4 for LoRA
Step 4: Launching the RFT Eval Job
Once the RFT job is completed, you can also take the checkpoint generated after RFT and use that to evaluate the model. This checkpoint can then be used in an evaluation recipe, overriding the base model, and executed in our evaluation container. The following is a snippet of how you can use the generated checkpoint for evaluation. Note the same code can also be used for running a baseline evaluation prior to checkpoint evaluation.
- For baselining use:
- For post RFT evaluation use:
Function:
Step 5: Monitoring the RFT metrics and iterating accordingly
Once the Jobs are launched, you can monitor the Job progress in Amazon CloudWatch logs for SageMaker Training Jobs to look at the RFT specific metrics. You can also monitor the CloudWatch logs of your reward Lambda function to verify how the rollouts and rewards are working. It is good practice to validate the reward Lambda function is calculating rewards as expected and is not getting into “reward hacking” (maximizing the reward signal in unintended ways that don’t align with the actual objective).
Review the following key metrics:
- Critic reward distribution metrics: These metrics (critic/rewards/mean, critic/rewards/max, critic/rewards/min) help in finding how the reward shape looks like and if the rewards are on a path of gradual increase.
- Model exploratory behavior metrics: This metrics help us in understanding the exploratory nature of the model. The higher actor/entropy indicates higher policy variation and model’s ability to explore newer paths.
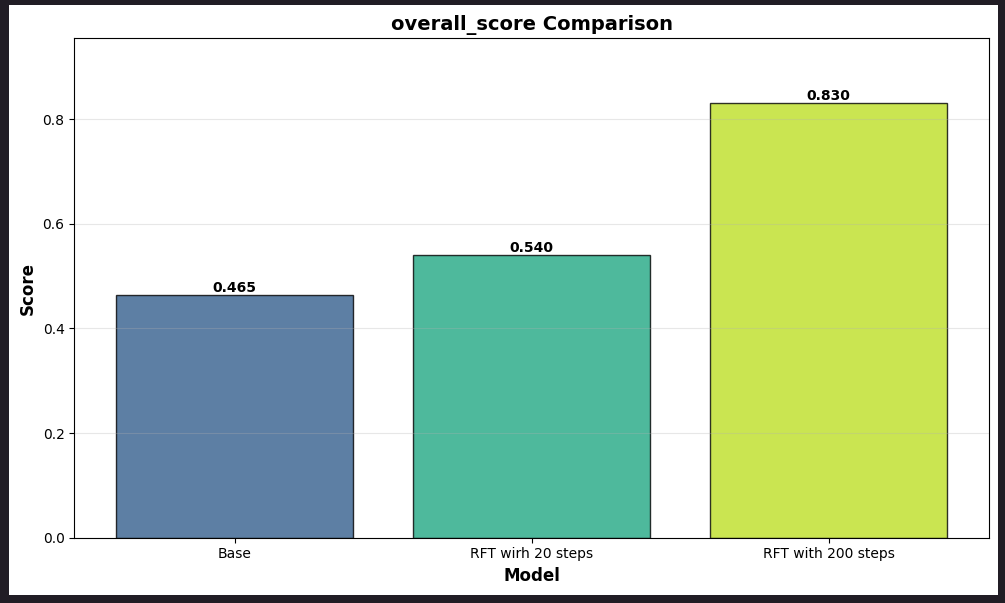
Conclusion
With RFT you can perform model customization through evaluation-based learning, requiring only prompts and quality criteria rather than massive, labeled datasets. For fully managed implementation, start with Amazon Bedrock. If you need more flexible control, move to SageMaker Training Jobs. For enterprise-scale workloads, SageMaker HyperPod provides the necessary infrastructure. Alternatively, explore Nova Forge for multi-turn agentic applications with custom reinforcement learning environments.
About the authors