Modern AI applications demand fast, cost-effective responses from large language models, especially when handling long documents or extended conversations. However, LLM inference can become prohibitively slow and expensive as context length increases, with latency growing exponentially and costs mounting with each interaction.
LLM inference requires recalculating attention mechanisms for the previous tokens when generating each new token. This creates significant computational overhead and high latency for long sequences. Key-value (KV) caching addresses this bottleneck by storing and reusing key-value vectors from previous computations, reducing inference latency and time-to-first-token (TTFT). Intelligent routing in LLMs is a technique that sends requests with shared prompts to the same inference instance to maximize the efficiency of the KV cache. It routes a new request to an instance that has already processed the same prefix, allowing it to reuse the cached KV data to accelerate processing and reduce latency. However, customers have told us that setting up and configuring the right framework for KV caching and intelligent routing at production scale is challenging and takes long experimental cycles.
Today we’re excited to announce that Amazon SageMaker HyperPod now supports Managed Tiered KV Cache and Intelligent Routing capabilities through the HyperPod Inference Operator. These new capabilities can deliver significant performance improvements for LLM inference workloads by reducing time to first token (TTFT) by up to 40%, increasing throughput, and lowering compute costs by up to 25% when used for long context prompts and multi-turn chat conversations using our internal tools. These capabilities are available for use with the HyperPod Inference Operator, which automatically manages the routing and distributed KV caching infrastructure, significantly reducing operational overhead while delivering enterprise-grade performance for production LLM deployments. By using the new Managed Tiered KV Cache feature you can efficiently offload attention caches to CPU memory (L1 cache) and distribute L2 cache for cross-instance sharing through a tiered storage architecture in HyperPod for optimal resource utilization and cost efficiency at scale.
Efficient KV caching combined with intelligent routing maximizes cache hits across workers so you can achieve higher throughput and lower costs for your model deployments. These features are particularly beneficial in applications that are processing long documents where the same context or prefix is referenced, or in multi-turn conversations where context from previous exchanges needs to be maintained efficiently across multiple interactions.
For example, legal teams analyzing 200 page contracts can now receive instant answers to follow-up questions instead of waiting 5+ seconds per query, healthcare chatbots maintain natural conversation flow across 20+ turn patient dialogues, and customer service systems process millions of daily requests with both better performance and lower infrastructure costs. These optimizations make document analysis, multi-turn conversations, and high-throughput inference applications economically viable at enterprise scale.
Optimizing LLM inference with Managed Tiered KV Cache and Intelligent Routing
Let’s break down the new features:
- Managed Tiered KV Cache: Automatic management of attention states across CPU memory (L1) and distributed tiered storage (L2) with configurable cache sizes and eviction policies. SageMaker HyperPod handles the distributed cache infrastructure through the newly launched tiered storage, alleviating operational overhead for cross node cache sharing across clusters. KV cache entries are accessible cluster-wide (L2) so that a node can benefit from computations performed by other nodes.
- Intelligent Routing: Configurable request routing to maximize cache hits using strategies like prefix-aware, KV-aware, and round-robin routing.
- Observability: Built-in HyperPod Observability integration for observability of metrics and logs for Managed Tiered KV Cache and Intelligent Routing in Amazon Managed Grafana.
Sample flow for inference requests with KV caching and Intelligent Routing
As a user sends an inference request to HyperPod Load Balancer, it forwards the request to the Intelligent Router within the HyperPod cluster. The Intelligent Router dynamically distributes requests to the most appropriate mode pod (Instance A or Instance B) based on the routing strategy to maximize KV cache hit and minimize inference latency. As the request reaches the model pod, the pod first checks L1 cache (CPU) for frequently used key-value pairs, then queries the shared L2 cache (Managed Tiered KV Cache) if needed, before performing full computation of the token. Newly generated KV pairs are stored in both cache tiers for future reuse. After computation completes, the inference result flows back through the Intelligent Router and Load Balancer to the user.
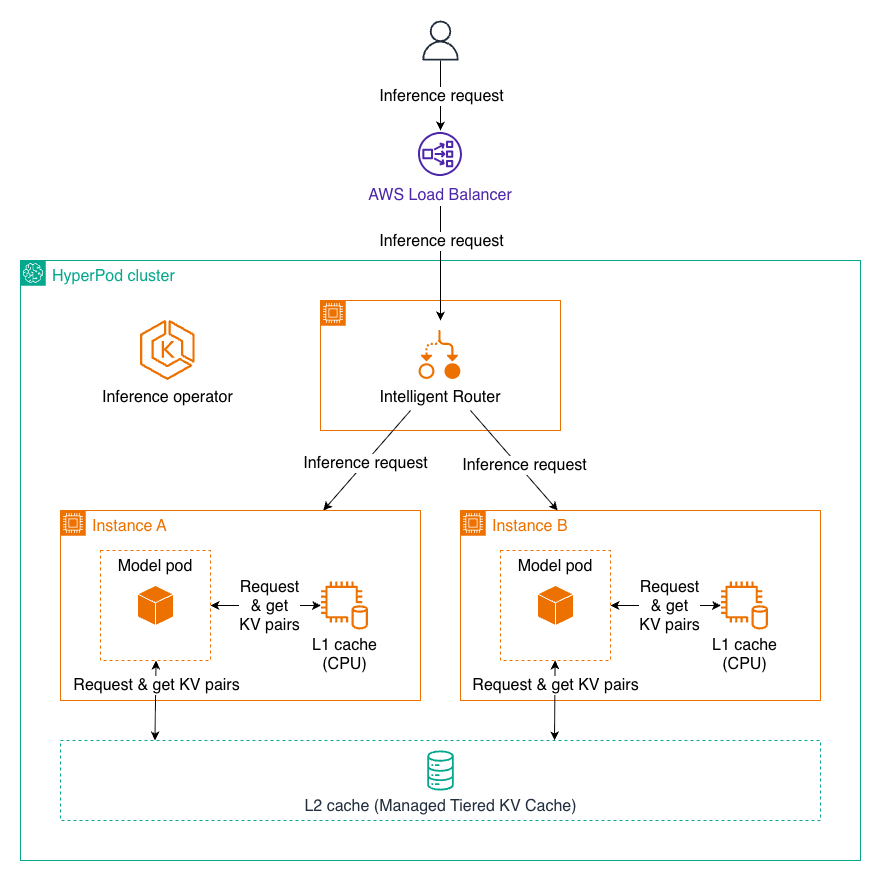
Managed Tiered KV Cache
Managed Tiered KV Cache and Intelligent Routing are configurable opt-in features. When enabling Managed KV Cache, L1 cache is enabled by default, while both L1 and L2 cache can be configured to be enabled or disabled. The L1 cache resides locally on each inference node utilizing CPU memory. This local cache provides significantly fast access, making it ideal for frequently accessed data within a single model instance. The cache automatically manages memory allocation and eviction policies to optimize for the most valuable cached content. The L2 cache operates as a distributed cache layer spanning the entire cluster, enabling cache sharing across multiple model instances. We support two backend options for L2 cache, each with the following benefits:
- Managed Tiered KV Cache (Recommended): A HyperPod disaggregated memory solution that offers excellent scalability to Terabyte pools, low latency, AWS network optimized, GPU-aware design with zero-copy support, and cost efficiency at scale.
- Redis: Simple to set up, works well for small to medium workloads, and offers a rich environment of tools and integrations.
The two-tier architecture works together seamlessly. When a request arrives, the system first checks the L1 cache for the required KV pairs. If found, they are used immediately with minimal latency. If not found in L1, the system queries the L2 cache. If found there, the data is retrieved and optionally promoted to L1 for faster future access. Only if the data is not present in either cache does the system perform the full computation, storing the results in both L1 and L2 for future reuse.
Intelligent Routing
Our Intelligent Routing system offers four configurable strategies to optimize request distribution based on your workload characteristics, with the routing strategy being user-configurable at deployment time to match your application’s specific requirements.
- Prefix-aware routing serves as the default strategy, maintaining a tree structure to track which prefixes are cached on which endpoints, delivering strong general-purpose performance for applications with common prompt templates such as multi-turn conversations, customer service bots with standard greetings, and code generation with common imports.
- KV-aware routing provides the most sophisticated cache management through a centralized controller that tracks cache locations and handles eviction events in real-time, excelling at long conversation threads, document processing workflows, and extended coding sessions where maximum cache efficiency is critical.
- Round-robin routing offers the most straightforward approach, distributing requests evenly across the available workers, best suited for scenarios where requests are independent, such as batch inference jobs, stateless API calls, and load testing scenarios.
| Strategy | Best for |
| Prefix-aware routing (default) | Multi-turn conversations, customer service bots, code generation with common headers |
| KV-aware routing | Long conversations, document processing, extended coding sessions |
| Round-robin routing | Batch inference, stateless API calls, load testing |
Deploying the Managed Tiered KV Cache and Intelligent Routing solution
Prerequisites
Create a HyperPod cluster with Amazon EKS as an orchestrator.
- In Amazon SageMaker AI console, navigate to HyperPod Clusters, then Cluster Management.
- On the Cluster Management page, select Create HyperPod cluster, then Orchestrated by Amazon EKS.

- You can use one-click deployment from the SageMaker AI console. For cluster set up details see Creating a SageMaker HyperPod cluster with Amazon EKS orchestration.
- Verify that the HyperPod cluster status is InService.

- Verify that the inference operator is up and running. The Inference add-on is installed as a default option when you create the HyperPod cluster from the console. If you want to use an existing EKS cluster, see Setting up your HyperPod clusters for model deployment to manually install the inference operator.
From the command line, run the following command:
Output:

Or, verify that the operator is running from console. Navigate to EKS cluster, Resources, Pods, Pick namespace, hyperpod-inference-system.
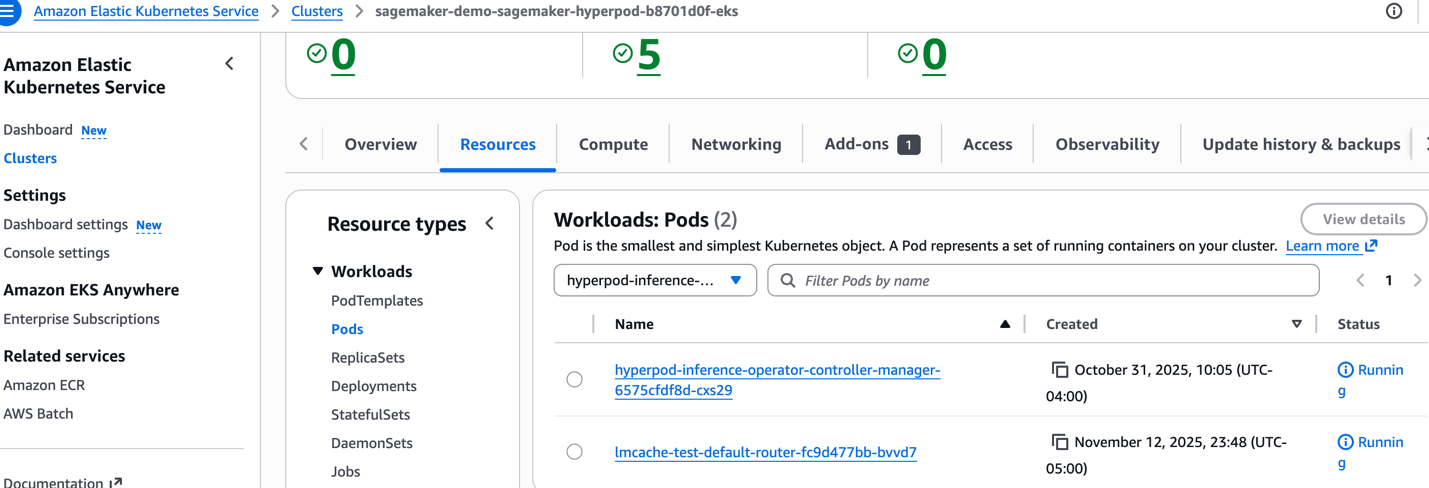
Preparing your model deployment manifest files
You can enable these features by adding configurations to your InferenceEndpointConfig custom CRD file.
For the complete example, visit the AWS samples GitHub repository.
Observability
You can monitor Managed KV Cache and Intelligent Routing metrics through the SageMaker HyperPod Observability features. For more information, see Accelerate foundation model development with one-click observability in Amazon SageMaker HyperPod.
KV Cache Metrics are available in the Inference dashboard.
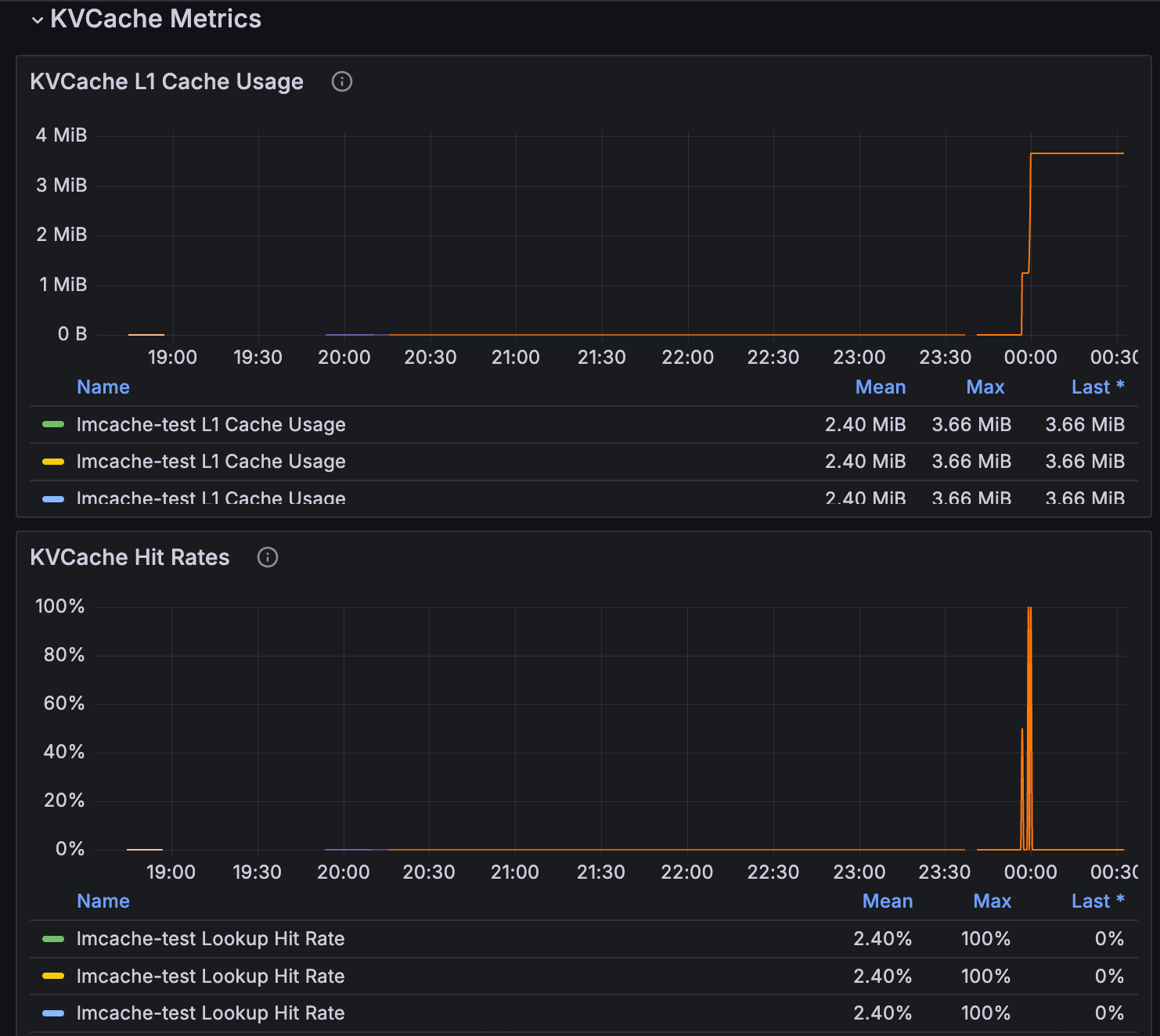
Benchmarking
We conducted comprehensive benchmarking to validate real-world performance improvements for production LLM deployments. Our benchmarks were run with Managed Tiered KV Cache and Intelligent Routing feature using the Llama-3.1-70B-Instruct model deployed across 7 replicas on p5.48xlarge instances (each equipped with eight NVIDIA GPUs), under a steady-load traffic pattern. The benchmark environment used a dedicated client node group—with one c5.12xlarge instance per 100 concurrent requests to generate a controlled load, and a dedicated server node group, making sure model servers operated in isolation to help prevent resource contention under high concurrency.
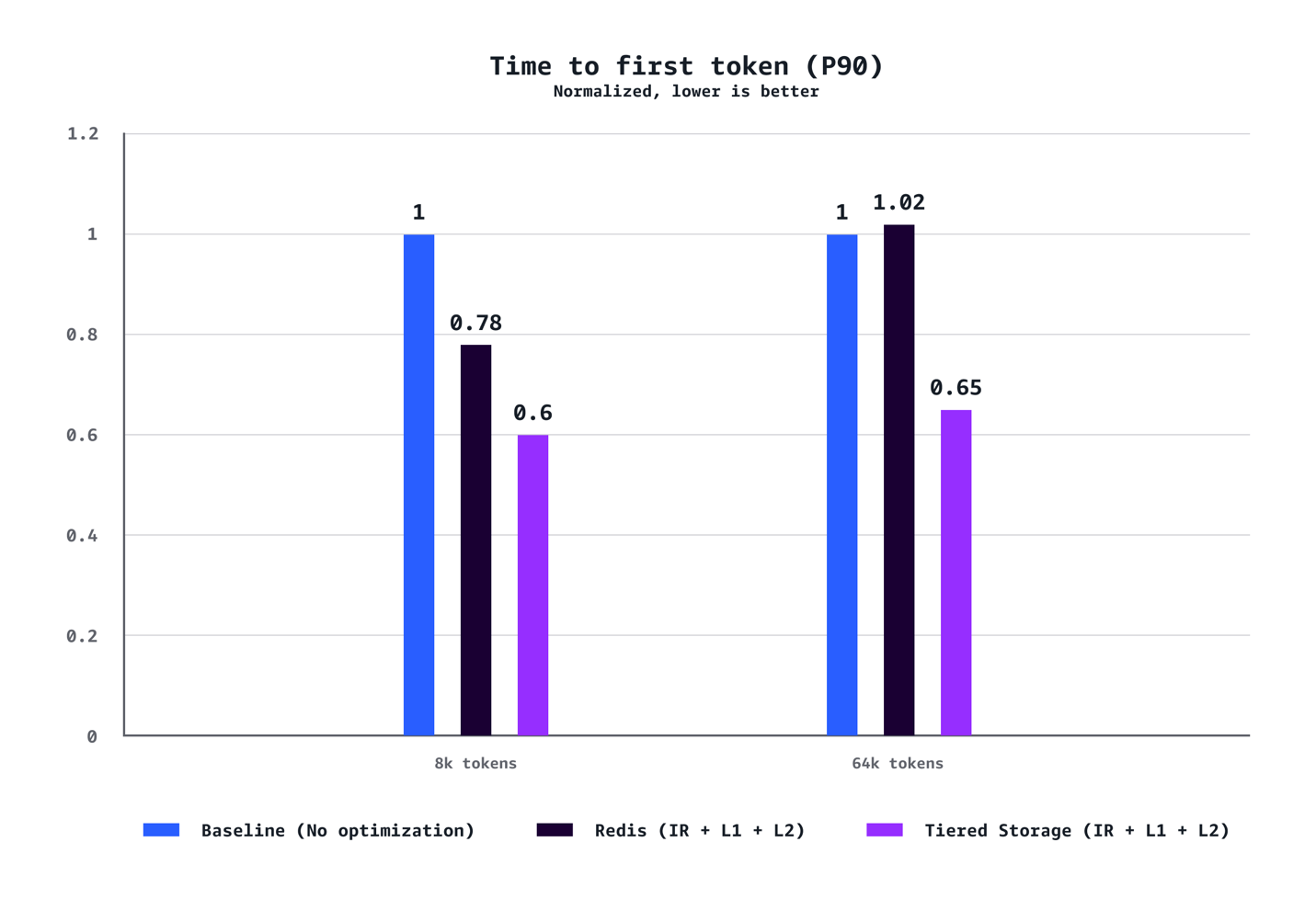
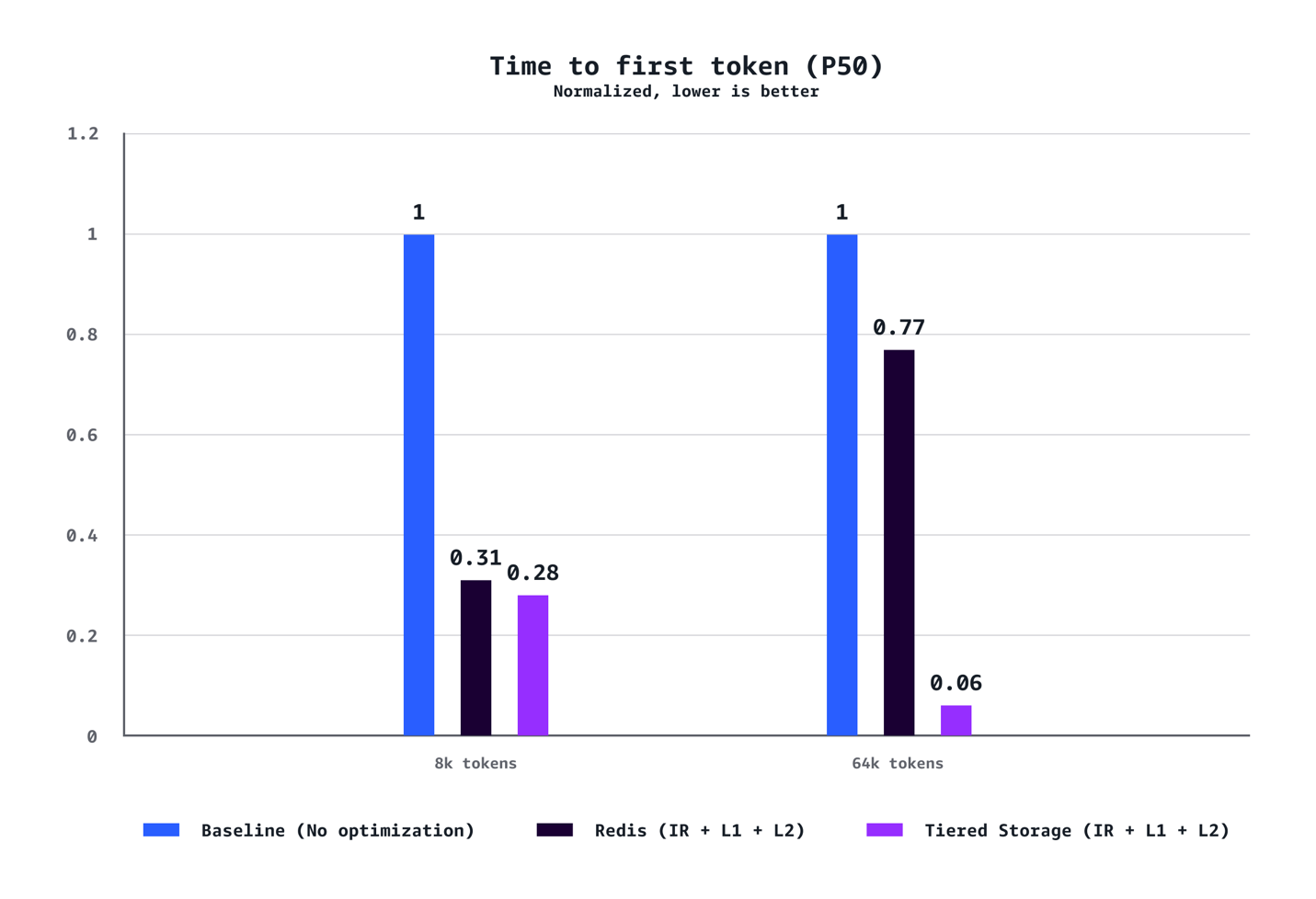
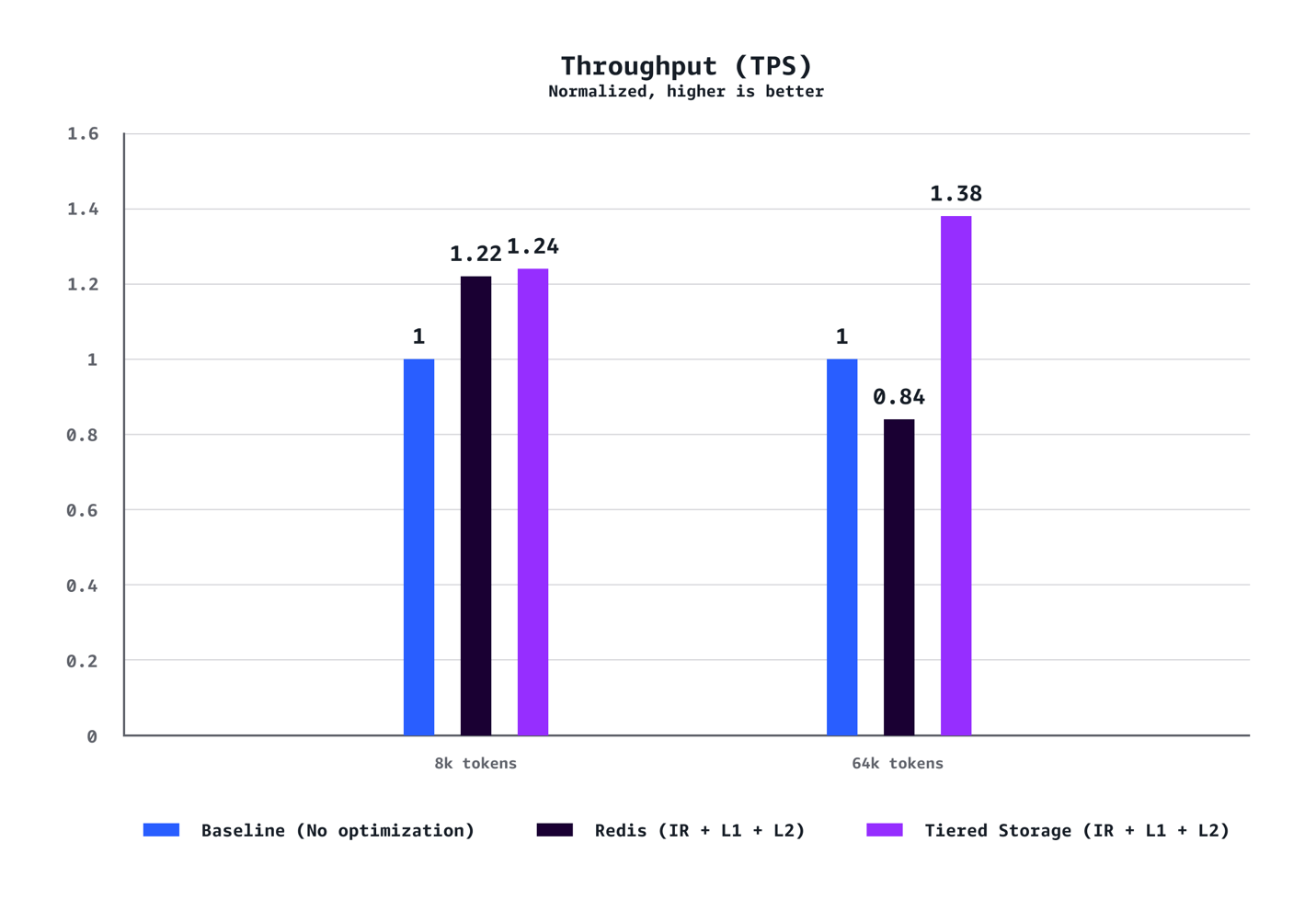
Our benchmarks demonstrate that a combination of L1 and L2 Managed Tiered KV Cache and Intelligent Routing delivers substantial performance improvements across multiple dimensions. For medium context scenarios (8k tokens), we observed a 40% reduction in time to first token (TTFT) at P90, 72% reduction at P50, 24% increase in throughput, and 21% cost reduction compared to baseline configurations without optimization. The benefits are even more pronounced for long context workloads (64K tokens), achieving a 35% reduction in TTFT at P90, 94% reduction at P50, 38% throughput increase, and 28% cost savings. The optimization benefits scale dramatically with context length. While 8K token scenarios demonstrate solid improvements across the metrics, 64K token workloads experience transformative gains that fundamentally change the user experience. Our testing also confirmed that AWS-managed tiered storage consistently outperformed Redis-based L2 caching across the scenarios. The tiered storage backend delivered better latency and throughput without requiring the operational overhead of managing separate Redis infrastructure, making it the recommended choice for most deployments. Finally, unlike traditional performance optimizations that require tradeoffs between cost and speed, this solution delivers both simultaneously.
TTFT (P90)
TTFT (P50)
Throughput (TPS)
Cost/1000 token ($)

Conclusion
Managed Tiered KV Cache and Intelligent Routing in Amazon SageMaker HyperPod Model Deployment help you optimize LLM inference performance and costs through efficient memory management and smart request routing. You can get started today by adding these configurations to your HyperPod model deployments in the AWS Regions where SageMaker HyperPod is available.
To learn more, visit the Amazon SageMaker HyperPod documentation or follow the model deployment getting started guide.
About the authors
 Chaitanya Hazarey is the Software Development Manager for SageMaker HyperPod Inference at Amazon, bringing extensive expertise in full-stack engineering, ML/AI, and data science. As a passionate advocate for responsible AI development, he combines technical leadership with a deep commitment to advancing AI capabilities while maintaining ethical considerations. His comprehensive understanding of modern product development drives innovation in machine learning infrastructure.
Chaitanya Hazarey is the Software Development Manager for SageMaker HyperPod Inference at Amazon, bringing extensive expertise in full-stack engineering, ML/AI, and data science. As a passionate advocate for responsible AI development, he combines technical leadership with a deep commitment to advancing AI capabilities while maintaining ethical considerations. His comprehensive understanding of modern product development drives innovation in machine learning infrastructure.
 Pradeep Cruz is a Senior SDM at Amazon Web Services (AWS), driving AI infrastructure and applications at enterprise scale. Leading cross-functional organizations at Amazon SageMaker AI, he has built and scaled multiple high-impact services for enterprise customers including SageMaker HyperPod-EKS Inference, Task Governance, Feature Store, AIOps, and JumpStart Model Hub at AWS, alongside enterprise AI platforms at T-Mobile and Ericsson. His technical depth spans distributed systems, GenAI/ML, Kubernetes, cloud computing, and full-stack software development.
Pradeep Cruz is a Senior SDM at Amazon Web Services (AWS), driving AI infrastructure and applications at enterprise scale. Leading cross-functional organizations at Amazon SageMaker AI, he has built and scaled multiple high-impact services for enterprise customers including SageMaker HyperPod-EKS Inference, Task Governance, Feature Store, AIOps, and JumpStart Model Hub at AWS, alongside enterprise AI platforms at T-Mobile and Ericsson. His technical depth spans distributed systems, GenAI/ML, Kubernetes, cloud computing, and full-stack software development.
 Vinay Arora is a Specialist Solution Architect for Generative AI at AWS, where he collaborates with customers in designing cutting-edge AI solutions leveraging AWS technologies. Prior to AWS, Vinay has over two decades of experience in finance—including roles at banks and hedge funds—he has built risk models, trading systems, and market data platforms. Vinay holds a master’s degree in computer science and business management.
Vinay Arora is a Specialist Solution Architect for Generative AI at AWS, where he collaborates with customers in designing cutting-edge AI solutions leveraging AWS technologies. Prior to AWS, Vinay has over two decades of experience in finance—including roles at banks and hedge funds—he has built risk models, trading systems, and market data platforms. Vinay holds a master’s degree in computer science and business management.
 Piyush Daftary is a Senior Software Engineer at AWS, working on Amazon SageMaker with a focus on building performant, scalable inference systems for large language models. His technical interests span AI/ML, databases, and search technologies, where he specializes in developing production-ready solutions that enable efficient model deployment and inference at scale. His work involves optimizing system performance, implementing intelligent routing mechanisms, and designing architectures that support both research and production workloads, with a passion for solving complex distributed systems challenges and making advanced AI capabilities more accessible to developers and organizations. Outside of work, he enjoys traveling, hiking, and spending time with family.
Piyush Daftary is a Senior Software Engineer at AWS, working on Amazon SageMaker with a focus on building performant, scalable inference systems for large language models. His technical interests span AI/ML, databases, and search technologies, where he specializes in developing production-ready solutions that enable efficient model deployment and inference at scale. His work involves optimizing system performance, implementing intelligent routing mechanisms, and designing architectures that support both research and production workloads, with a passion for solving complex distributed systems challenges and making advanced AI capabilities more accessible to developers and organizations. Outside of work, he enjoys traveling, hiking, and spending time with family.
 Ziwen Ning is a Senior Software Development Engineer at AWS, currently working on SageMaker Hyperpod Inference with a focus on building scalable infrastructure for large-scale AI model inference. His technical expertise spans container technologies, Kubernetes orchestration, and ML infrastructure, developed through extensive work across the AWS ecosystem. He has deep experience in container registries and distribution, container runtime development and open source contributions, and containerizing ML workloads with custom resource management and monitoring. Ziwen is passionate about designing production-grade systems that make advanced AI capabilities more accessible. In his free time, he enjoys kickboxing, badminton, and immersing himself in music.
Ziwen Ning is a Senior Software Development Engineer at AWS, currently working on SageMaker Hyperpod Inference with a focus on building scalable infrastructure for large-scale AI model inference. His technical expertise spans container technologies, Kubernetes orchestration, and ML infrastructure, developed through extensive work across the AWS ecosystem. He has deep experience in container registries and distribution, container runtime development and open source contributions, and containerizing ML workloads with custom resource management and monitoring. Ziwen is passionate about designing production-grade systems that make advanced AI capabilities more accessible. In his free time, he enjoys kickboxing, badminton, and immersing himself in music.
 Roman Blagovirnyy is a Sr. User Experience Designer on the SageMaker AI team with 19 years of diverse experience in interactive, workflow, and UI design, working on enterprise and B2B applications and features for the finance, healthcare, security, and HR industries prior to joining Amazon. At AWS Roman was a key contributor to the design of SageMaker AI Studio, SageMaker Studio Lab, data and model governance capabilities, and HyperPod. Roman’s currently works on new features and improvements to the administrator experience for HyperPod. In addition to this, Roman has a keen interest in design operations and process.
Roman Blagovirnyy is a Sr. User Experience Designer on the SageMaker AI team with 19 years of diverse experience in interactive, workflow, and UI design, working on enterprise and B2B applications and features for the finance, healthcare, security, and HR industries prior to joining Amazon. At AWS Roman was a key contributor to the design of SageMaker AI Studio, SageMaker Studio Lab, data and model governance capabilities, and HyperPod. Roman’s currently works on new features and improvements to the administrator experience for HyperPod. In addition to this, Roman has a keen interest in design operations and process.
 Caesar Chen is the Software Development Manager for SageMaker HyperPod at AWS, where he leads the development of cutting-edge machine learning infrastructure. With extensive experience in building production-grade ML systems, he drives technical innovation while fostering team excellence. His work in scalable model hosting infrastructure empowers data scientists and ML engineers to deploy and manage models with greater efficiency and reliability.
Caesar Chen is the Software Development Manager for SageMaker HyperPod at AWS, where he leads the development of cutting-edge machine learning infrastructure. With extensive experience in building production-grade ML systems, he drives technical innovation while fostering team excellence. His work in scalable model hosting infrastructure empowers data scientists and ML engineers to deploy and manage models with greater efficiency and reliability.
 Chandra Lohit Reddy Tekulapally is a Software Development Engineer with the Amazon SageMaker HyperPod team. He is passionate about designing and building reliable, high-performance distributed systems that power large-scale AI workloads. Outside of work, he enjoys traveling and exploring new coffee spots.
Chandra Lohit Reddy Tekulapally is a Software Development Engineer with the Amazon SageMaker HyperPod team. He is passionate about designing and building reliable, high-performance distributed systems that power large-scale AI workloads. Outside of work, he enjoys traveling and exploring new coffee spots.
 Kunal Jha is a Principal Product Manager at AWS. He is focused on building Amazon SageMaker Hyperpod as the best-in-class choice for Generative AI model’s training and inference. In his spare time, Kunal enjoys skiing and exploring the Pacific Northwest.
Kunal Jha is a Principal Product Manager at AWS. He is focused on building Amazon SageMaker Hyperpod as the best-in-class choice for Generative AI model’s training and inference. In his spare time, Kunal enjoys skiing and exploring the Pacific Northwest.
 Vivek Gangasani is a Worldwide Lead GenAI Specialist Solutions Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product strategy for SageMaker Inference. He also helps enterprises and startups deploy, manage, and scale their GenAI models with SageMaker and GPUs. Currently, he is focused on developing strategies and content for optimizing inference performance and GPU efficiency for hosting Large Language Models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
Vivek Gangasani is a Worldwide Lead GenAI Specialist Solutions Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product strategy for SageMaker Inference. He also helps enterprises and startups deploy, manage, and scale their GenAI models with SageMaker and GPUs. Currently, he is focused on developing strategies and content for optimizing inference performance and GPU efficiency for hosting Large Language Models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.

