This is a guest post co-written with Rahul Ghosh, Sandeep Kumar Veerlapati, Rahmat Khan, and Mudit Chopra from PayU.
PayU offers a full-stack digital financial services system that serves the financial needs of merchants, banks, and consumers through technology.
As a Central Bank-regulated financial institution in India, we recently observed a surge in our employees’ interest in using public generative AI assistants. Our teams found these AI assistants helpful for a variety of tasks, including troubleshooting technical issues by sharing error or exception details, generating email responses, and rephrasing English content for internal and external communications. However, this growing reliance on public generative AI tools quickly raised red flags for our Information Security (Infosec) team. We became increasingly concerned about the risks of sensitive data—such as proprietary system information, confidential customer details, and regulated documentation—being transmitted to and processed by external, third-party AI providers. Given our strict compliance requirements and the critical importance of data privacy in the financial sector, we made the decision to restrict access to these public generative AI systems. This move was necessary to safeguard our organization against potential data leaks and regulatory breaches, but it also highlighted the need for a secure, compliance-aligned alternative that would allow us to harness the benefits of generative AI without compromising on security policies.
In this post, we explain how we equipped the PayU team with an enterprise AI solution and democratized AI access using Amazon Bedrock, without compromising on data residency requirements.
Solution overview
As a regulated entity, we were required to keep all our data within India and securely contained within our PayU virtual private cloud (VPC). Therefore, we sought a solution that could use the power of generative AI to foster innovation and enhance operational efficiency, while simultaneously enabling robust data security measures and geo-fencing of the utilized data. Beyond foundational use cases like technical troubleshooting, email drafting, and content refinement, we aimed to equip teams with a natural language interface to query enterprise data across domains. This included enabling self-service access to business-critical insights—such as loan disbursement trends, repayment patterns, customer demographics, and transaction analytics—as well as HR policy clarifications, through intuitive, conversational interactions. Our vision was to empower employees with instant, AI-driven answers derived from internal systems without exposing sensitive data to external systems, thereby aligning with India’s financial regulations and our internal governance frameworks.
We chose Amazon Bedrock because it is a fully managed service that provides access to a wide selection of high-performing foundation models (FMs) from industry leaders such as AI21 Labs, Anthropic, Cohere, DeepSeek, Luma, Meta, Mistral AI, poolside (coming soon), Stability AI, TwelveLabs (coming soon), Writer, and Amazon. The models are accessible through a single, unified API. Amazon Bedrock also offers a comprehensive suite of features that align with our requirements, including Amazon Bedrock Agents for workflow automation and Amazon Bedrock Knowledge Bases for enterprise data integration. In addition, Amazon Bedrock Guardrails provides essential safeguards across model, prompt, and application levels for blocking undesirable and harmful multimodal content and helped filter hallucinated responses in our Retrieval Augmented Generation (RAG) and agentic workflows.
For the frontend, we selected Open WebUI, an open-source solution known for its extensibility, rich feature set, and intuitive, user-friendly interface, so our teams can interact seamlessly with the AI capabilities we’ve integrated.
The following diagram illustrates the solution architecture.

In the following sections, we discuss the key components to the solution in more detail.
Open WebUI
We use Open WebUI as our browser-based frontend application. Open WebUI is an open source, self-hosted application designed to provide a user-friendly and feature-rich interface for interacting with large language models (LLMs). It supports integration with a wide range of models and can be deployed in private environments to help protect data privacy and security. Open WebUI supports enterprise features like single sign-on (SSO), so users can authenticate seamlessly using their organization’s identity provider, streamlining access and reducing password-related risks. The service also offers role-based access control (RBAC), so administrators can define granular user roles—such as admin and user—so that permissions, model access, and data visibility can be tailored to organizational needs. This supports the protection of sensitive information.
We connected Open WebUI with our identity provider for enabling SSO. RBAC was implemented by defining functional roles—such as loan operations or HR support—directly tied to user job functions. These roles govern permissions to specific agents, knowledge bases, and FMs so that teams only access tools relevant to their responsibilities. Configurations, user conversation histories, and usage metrics are securely stored in a persistent Amazon Relational Database Service (Amazon RDS) for PostgreSQL database, enabling audit readiness and supporting compliance. For deployment, we containerized Open WebUI and orchestrated it on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster, using automatic scaling to dynamically adjust resources based on demand while maintaining high availability.
Access Gateway
Access Gateway serves as an intermediary between Open WebUI and Amazon Bedrock, translating Amazon Bedrock APIs to a compatible schema for Open WebUI. This component enables the frontend to access FMs, Amazon Bedrock Agents, and Amazon Bedrock Knowledge Bases.
Amazon Bedrock
Amazon Bedrock offers a diverse selection of FMs, which we have integrated into the web UI to enable the PayU workforce to efficiently perform tasks such as text summarization, email drafting, and technical troubleshooting. In addition, we developed custom AI agents using Amazon Bedrock Agents and Amazon Bedrock Knowledge Bases, using our organizational data. These tailored agents are also accessible through the frontend application.
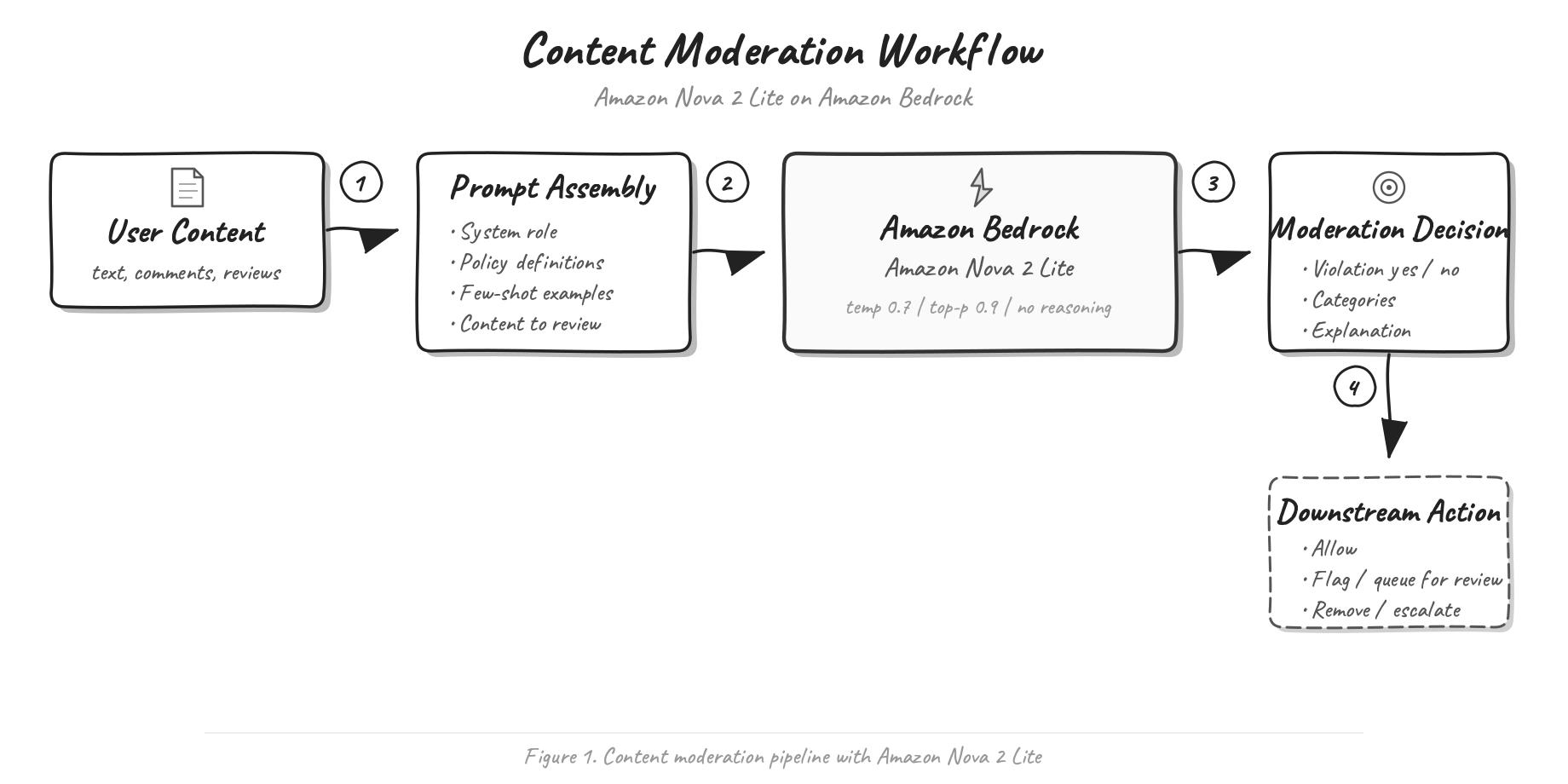
To enable secure, role-based access to organizational insights, we deployed specialized agents tailored to specific business functions—including hr-policy-agent, credit-disbursal-agent, collections-agent, and payments-demographics-agent. Access to these agents is governed by user roles and job functions. These agents follow a combination of RAG and text-to-SQL approaches. For example, hr-policy-agent uses RAG, querying a vectorized knowledge base in Amazon OpenSearch Service, whereas credit-disbursal-agent uses a text-to-SQL pipeline, translating natural language queries into structured SQL commands to extract insights from an Amazon Simple Storage Service (Amazon S3) based data lake. These approaches provide precise, context-aware responses while maintaining data governance. Implementation details of the text-to-SQL workflow is described in the following diagram.

The workflow consists of the following steps:
- We maintain our business-specific datamarts in the data lakehouse in Amazon S3, enriched with rich metadata and presented in a highly denormalized form. This data lakehouse, internally referred to as Luna, is built using Apache Spark and Apache Hudi. The datamarts are crucial for achieving higher accuracy and improved performance in our systems. The data is exposed as AWS Glue tables, which function as the Hive Metastore, and can be queried using Amazon Athena, enabling efficient access and analytical capabilities for our business needs.
- HR policy documents are stored in another S3 bucket. Using Amazon Bedrock Knowledge Bases, these are vectorized and stored in OpenSearch Service.
- Depending on their role, employees can access FMs and agents through the Open WebUI interface. They have the option to choose either an FM or an agent from a dropdown menu. When a user selects an FM, their question is answered directly using the model’s pre-trained knowledge, without involving an agent. If an agent is selected, the corresponding agent is invoked to handle the request.
- To facilitate orchestration, an instruction prompt is given to the Amazon Bedrock agent. The agent interprets this prompt and manages the workflow by delegating specific actions to the underlying LLM. Through this process, the Amazon Bedrock agent coordinates task execution, so that each step is handled appropriately based on the input received and the orchestration logic defined for the workflow. The orchestration step can extract context from the knowledge base or invoke an action group. An instruction prompt is supplied to the Amazon Bedrock agent to guide the orchestration process. The agent interprets this prompt and coordinates the workflow by assigning specific tasks to the LLM. For example, while invoking actions for the text-to-SQL agent, it has been instructed to check syntaxes first and fix the query by reading the error then only execute the final query.
- An instruction prompt is supplied to the Amazon Bedrock agent to guide the orchestration process. The agent interprets this prompt and coordinates the workflow by assigning specific tasks to the LLM.
- The primary function of an action group in an Amazon Bedrock agent is to organize and execute multiple actions in response to a user’s input or request. This enables the agent to carry out a sequence of coordinated steps to effectively meet the user’s needs, rather than being limited to a single action. Each action group includes a schema, which defines the required format and parameters. This schema allows the agent to interact accurately with the compute layer, such as an AWS Lambda function, by supplying the required structure for communication.
- The Lambda function serves as the execution engine, running SQL queries and connecting with Athena to process data. To enable secure and efficient operation, it is essential to configure resource policies and permissions correctly, which helps maintain the integrity of the serverless compute environment.
- Athena is a serverless query service that analyzes Amazon S3 data using standard SQL, with AWS Glue managing the data catalog. AWS Glue reads data from Amazon S3, creates queryable tables for Athena, and stores query results back in Amazon S3. This integration, supported by crawlers and the AWS Glue Data Catalog, streamlines data management and analysis.
- For questions related to HR policies and other enterprise documents, the system uses Amazon Bedrock Knowledge Bases. These knowledge bases are built from the HR policy documents stored in Amazon S3, with semantic search capabilities powered by vector embeddings in OpenSearch Service.
Private access to foundation models
Given that our organizational data was included as context in prompts sent to Amazon Bedrock and the generated responses could contain sensitive information, we needed a robust solution to help prevent exposure of this data to the public internet. Our goal was to establish a secure data perimeter that would help mitigate potential risks associated with internet-facing communication. To achieve this, we implemented AWS PrivateLink, creating a private and dedicated connection between our VPC and Amazon Bedrock. With this configuration, Amazon Bedrock is accessible as though it resides within our own VPC, removing the need for an internet gateway or NAT gateway. By setting up an interface endpoint with PrivateLink, we provisioned a network interface directly in our VPC subnet, so that data remains securely within the AWS network. This architecture not only strengthens our security posture by minimizing external exposure but also streamlines connectivity for our internal applications.
The following diagram illustrates this architecture.

Conclusion
The introduction of this application has generated significant interest in generative AI within PayU. Employees are now more aware of AI’s potential to address complex business challenges. This enthusiasm has led to the addition of multiple business workflows to the application. Collaboration between business units and the technical team has accelerated digital transformation efforts. After the rollout, internal estimates revealed a 30% improvement in the productivity of the business analyst team. This boost in efficiency has made it possible for analysts to focus on more strategic tasks and reduced turnaround times. Overall, the application has inspired a culture of innovation and continuous learning across the organization.
Ready to take your organization’s AI capabilities to the next level? Dive into the technical details of Amazon Bedrock, Amazon Bedrock Agents, and Amazon Bedrock Guardrails in the Amazon Bedrock User Guide, and explore hands-on examples in the Amazon Bedrock Agent GitHub repo to kickstart your implementation.
About the authors
 Deepesh Dhapola is a Senior Solutions Architect at AWS India, where he architects high-performance, resilient cloud solutions for financial services and fintech organizations. He specializes in using advanced AI technologies—including generative AI, intelligent agents, and the Model Context Protocol (MCP)—to design secure, scalable, and context-aware applications. With deep expertise in machine learning and a keen focus on emerging trends, Deepesh drives digital transformation by integrating cutting-edge AI capabilities to enhance operational efficiency and foster innovation for AWS customers. Beyond his technical pursuits, he enjoys quality time with his family and explores creative culinary techniques.
Deepesh Dhapola is a Senior Solutions Architect at AWS India, where he architects high-performance, resilient cloud solutions for financial services and fintech organizations. He specializes in using advanced AI technologies—including generative AI, intelligent agents, and the Model Context Protocol (MCP)—to design secure, scalable, and context-aware applications. With deep expertise in machine learning and a keen focus on emerging trends, Deepesh drives digital transformation by integrating cutting-edge AI capabilities to enhance operational efficiency and foster innovation for AWS customers. Beyond his technical pursuits, he enjoys quality time with his family and explores creative culinary techniques.
 Rahul Ghosh is a seasoned Data & AI Engineer with deep expertise in cloud-based data architectures, large-scale data processing, and modern AI technologies, including generative AI, LLMs, Retrieval Augmented Generation (RAG), and agent-based systems. His technical toolkit spans across Python, SQL, Spark, Hudi, Airflow, Kubeflow, and other modern orchestration frameworks, with hands-on experience in AWS, Azure, and open source systems. Rahul is passionate about building reliable, scalable, and ethically grounded solutions at the intersection of data and intelligence. Outside of work, he enjoys mentoring budding technologists and doing social work rooted in his native rural Bengal.
Rahul Ghosh is a seasoned Data & AI Engineer with deep expertise in cloud-based data architectures, large-scale data processing, and modern AI technologies, including generative AI, LLMs, Retrieval Augmented Generation (RAG), and agent-based systems. His technical toolkit spans across Python, SQL, Spark, Hudi, Airflow, Kubeflow, and other modern orchestration frameworks, with hands-on experience in AWS, Azure, and open source systems. Rahul is passionate about building reliable, scalable, and ethically grounded solutions at the intersection of data and intelligence. Outside of work, he enjoys mentoring budding technologists and doing social work rooted in his native rural Bengal.
 Sandeep Kumar Veerlapati is an Associate Director – Data Engineering at PayU Finance, where he focuses on building strong, high-performing teams and defining effective data strategies. With expertise in cloud data systems, data architecture, and generative AI, Sandeep brings a wealth of experience in creating scalable and impactful solutions. He has a deep technical background with tools like Spark, Airflow, Hudi, and the AWS Cloud. Passionate about delivering value through data, he thrives on leading teams to solve real-world challenges. Outside of work, Sandeep enjoys mentoring, collaborating, and finding new ways to innovate with technology.
Sandeep Kumar Veerlapati is an Associate Director – Data Engineering at PayU Finance, where he focuses on building strong, high-performing teams and defining effective data strategies. With expertise in cloud data systems, data architecture, and generative AI, Sandeep brings a wealth of experience in creating scalable and impactful solutions. He has a deep technical background with tools like Spark, Airflow, Hudi, and the AWS Cloud. Passionate about delivering value through data, he thrives on leading teams to solve real-world challenges. Outside of work, Sandeep enjoys mentoring, collaborating, and finding new ways to innovate with technology.
 Mudit Chopra is a skilled DevOps Engineer and generative AI enthusiast, with expertise in automating workflows, building robust CI/CD pipelines, and managing cloud-based infrastructures across systems. With a passion for streamlining delivery pipelines and enabling cross-team collaboration, they facilitate seamless product deployments. Dedicated to continuous learning and innovation, Mudit thrives on using AI-driven tools to enhance operational efficiency and create smarter, more agile systems. Always staying ahead of tech trends, he is dedicated to driving digital transformation and delivering impactful solutions.
Mudit Chopra is a skilled DevOps Engineer and generative AI enthusiast, with expertise in automating workflows, building robust CI/CD pipelines, and managing cloud-based infrastructures across systems. With a passion for streamlining delivery pipelines and enabling cross-team collaboration, they facilitate seamless product deployments. Dedicated to continuous learning and innovation, Mudit thrives on using AI-driven tools to enhance operational efficiency and create smarter, more agile systems. Always staying ahead of tech trends, he is dedicated to driving digital transformation and delivering impactful solutions.
 Rahmat Khan is a driven AI & Machine Learning Engineer and entrepreneur, with a deep focus on building intelligent, real-world systems. His work spans the full ML lifecycle—data engineering, model development, and deployment at scale—with a strong grounding in practical AI applications. Over the years, he has explored everything from generative models to multimodal systems, with an eye toward creating seamless user experiences. Driven by curiosity and a love for experimentation, he enjoys solving open-ended problems, shipping fast, and learning from the edge of what’s possible. Outside of tech, he’s equally passionate about nurturing ideas, mentoring peers, and staying grounded in the bigger picture of why we build.
Rahmat Khan is a driven AI & Machine Learning Engineer and entrepreneur, with a deep focus on building intelligent, real-world systems. His work spans the full ML lifecycle—data engineering, model development, and deployment at scale—with a strong grounding in practical AI applications. Over the years, he has explored everything from generative models to multimodal systems, with an eye toward creating seamless user experiences. Driven by curiosity and a love for experimentation, he enjoys solving open-ended problems, shipping fast, and learning from the edge of what’s possible. Outside of tech, he’s equally passionate about nurturing ideas, mentoring peers, and staying grounded in the bigger picture of why we build.
 Saikat Dey is a Technical Account Manager (TAM) at AWS India, supporting strategic fintech customers in harnessing the power of the cloud to drive innovation and business transformation. As a trusted advisor, he bridges technical and business teams, delivering architectural best practices, proactive guidance, and strategic insights that enable long-term success on AWS. With a strong passion for generative AI, Saikat partners with customers to identify high-impact use cases and accelerate their adoption of generative AI solutions using services like Amazon Bedrock and Amazon Q. Outside of work, he actively explores emerging technologies, follows innovation trends, and enjoys traveling to experience diverse cultures and perspectives.
Saikat Dey is a Technical Account Manager (TAM) at AWS India, supporting strategic fintech customers in harnessing the power of the cloud to drive innovation and business transformation. As a trusted advisor, he bridges technical and business teams, delivering architectural best practices, proactive guidance, and strategic insights that enable long-term success on AWS. With a strong passion for generative AI, Saikat partners with customers to identify high-impact use cases and accelerate their adoption of generative AI solutions using services like Amazon Bedrock and Amazon Q. Outside of work, he actively explores emerging technologies, follows innovation trends, and enjoys traveling to experience diverse cultures and perspectives.