This post is co-written with Zhanghao Wu, co-creator of SkyPilot.
The rapid advancement of generative AI and foundation models (FMs) has significantly increased computational resource requirements for machine learning (ML) workloads. Modern ML pipelines require efficient systems for distributing workloads across accelerated compute resources, while making sure developer productivity remains high. Organizations need infrastructure solutions that are not only powerful but also flexible, resilient, and straightforward to manage.
SkyPilot is an open source framework that simplifies running ML workloads by providing a unified abstraction layer that helps ML engineers run their workloads on different compute resources without managing underlying infrastructure complexities. It offers a simple, high-level interface for provisioning resources, scheduling jobs, and managing distributed training across multiple nodes.
Amazon SageMaker HyperPod is a purpose-built infrastructure to develop and deploy large-scale FMs. SageMaker HyperPod not only provides the flexibility to create and use your own software stack, but also provides optimal performance through same spine placement of instances, as well as built-in resiliency. Combining the resiliency of SageMaker HyperPod and the efficiency of SkyPilot provides a powerful framework to scale up your generative AI workloads.
In this post, we share how SageMaker HyperPod, in collaboration with SkyPilot, is streamlining AI development workflows. This integration makes our advanced GPU infrastructure more accessible to ML engineers, enhancing productivity and resource utilization.
Challenges of orchestrating machine learning workloads
Kubernetes has become popular for ML workloads due to its scalability and rich open source tooling. SageMaker HyperPod orchestrated on Amazon Elastic Kubernetes Service (Amazon EKS) combines the power of Kubernetes with the resilient environment of SageMaker HyperPod designed for training large models. Amazon EKS support in SageMaker HyperPod strengthens resilience through deep health checks, automated node recovery, and job auto-resume capabilities, providing uninterrupted training for large-scale and long-running jobs.
ML engineers transitioning from traditional VM or on-premises environments often face a steep learning curve. The complexity of Kubernetes manifests and cluster management can pose significant challenges, potentially slowing down development cycles and resource utilization.
Furthermore, AI infrastructure teams faced the challenge of balancing the need for advanced management tools with the desire to provide a user-friendly experience for their ML engineers. They required a solution that could offer both high-level control and ease of use for day-to-day operations.
SageMaker HyperPod with SkyPilot
To address these challenges, we partnered with SkyPilot to showcase a solution that uses the strengths of both platforms. SageMaker HyperPod excels at managing the underlying compute resources and instances, providing the robust infrastructure necessary for demanding AI workloads. SkyPilot complements this by offering an intuitive layer for job management, interactive development, and team coordination.
Through this partnership, we can offer our customers the best of both worlds: the powerful, scalable infrastructure of SageMaker HyperPod, combined with a user-friendly interface that significantly reduces the learning curve for ML engineers. For AI infrastructure teams, this integration provides advanced management capabilities while simplifying the experience for their ML engineers, creating a win-win situation for all stakeholders.
SkyPilot helps AI teams run their workloads on different infrastructures with a unified high-level interface and powerful management of resources and jobs. An AI engineer can bring in their AI framework and specify the resource requirements for the job; SkyPilot will intelligently schedule the workloads on the best infrastructure: find the available GPUs, provision the GPU, run the job, and manage its lifecycle.

Solution overview
Implementing this solution is straightforward, whether you’re working with existing SageMaker HyperPod clusters or setting up a new deployment. For existing clusters, you can connect using AWS Command Line Interface (AWS CLI) commands to update your kubeconfig and verify the setup. For new deployments, we guide you through setting up the API server, creating clusters, and configuring high-performance networking options like Elastic Fabric Adapter (EFA).
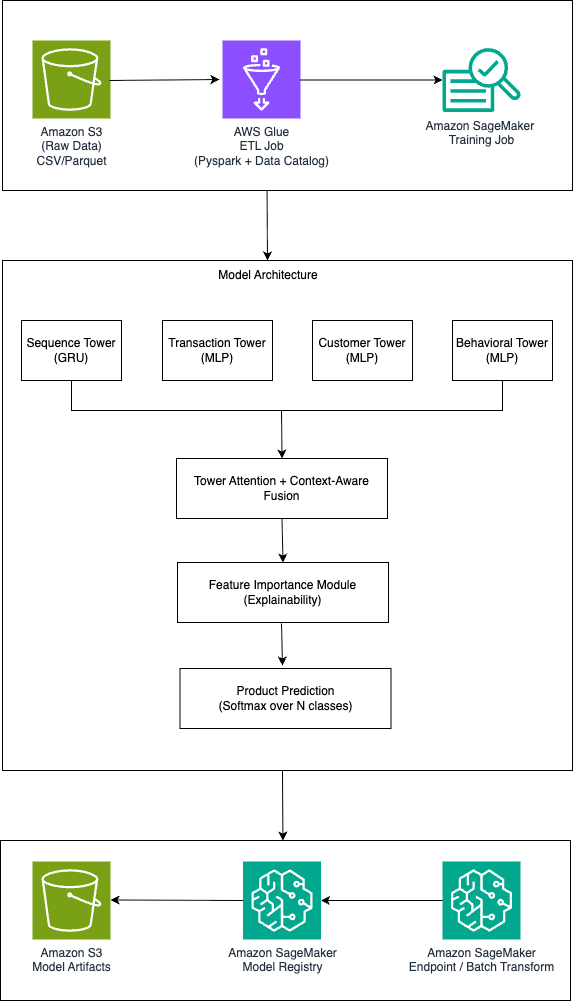
The following diagram illustrates the solution architecture.

In the following sections, we show how to run SkyPilot jobs for multi-node distributed training on SageMaker HyperPod. We go over the process of creating a SageMaker HyperPod cluster, installing SkyPilot, creating a SkyPilot cluster, and deploying a SkyPilot training job.
Prerequisites
You must have the following prerequisites:
- An existing SageMaker HyperPod cluster with Amazon EKS (to create one, refer to Deploy Your HyperPod Cluster). You must provision a single ml.p5.48xlarge instance for the code samples in the following sections.
- Access to the AWS CLI and
kubectlcommand line tools. - A Python environment for installing SkyPilot.
Create a SageMaker HyperPod cluster
You can create an EKS cluster with a single AWS CloudFormation stack following the instructions in Using CloudFormation, configured with a virtual private cloud (VPC) and storage resources.
To create and manage SageMaker HyperPod clusters, you can use either the AWS Management Console or AWS CLI. If you use the AWS CLI, specify the cluster configuration in a JSON file and choose the EKS cluster created from the CloudFormation stack as the orchestrator of the SageMaker HyperPod cluster. You then create the cluster worker nodes with NodeRecovery set to Automatic to enable automatic node recovery, and for OnStartDeepHealthChecks, add InstanceStress and InstanceConnectivity to enable deep health checks. See the following code:
You can add InstanceStorageConfigs to provision and mount additional Amazon Elastic Block Store (Amazon EBS) volumes on SageMaker HyperPod nodes.
To create the cluster using the SageMaker HyperPod APIs, run the following AWS CLI command:
You are now ready to set up SkyPilot on your SageMaker HyperPod cluster.
Connect to your SageMaker HyperPod EKS cluster
From your AWS CLI environment, run the aws eks update-kubeconfig command to update your local kube config file (located at ~/.kube/config) with the credentials and configuration needed to connect to your EKS cluster using the kubectl command (provide your specific EKS cluster name):
aws eks update-kubeconfig --name $EKS_CLUSTER_NAME
You can verify that you are connected to the EKS cluster by running the following command:
kubectl config current-context
Install SkyPilot with Kubernetes support
Use the following code to install SkyPilot with Kubernetes support using pip:
pip install skypilot[kubernetes]
This installs the latest build of SkyPilot, which includes the necessary Kubernetes integrations.
Verify SkyPilot’s connection to the EKS cluster
Check if SkyPilot can connect to your Kubernetes cluster:
sky check k8s
The output should look similar to the following code:
If this is your first time using SkyPilot with this Kubernetes cluster, you might see a prompt to create GPU labels for your nodes. Follow the instructions by running the following code:
python -m sky.utils.kubernetes.gpu_labeler --context <your-eks-context>
This script helps SkyPilot identify what GPU resources are available on each node in your cluster. The GPU labeling job might take a few minutes depending on the number of GPU resources in your cluster.
Discover available GPUs in the cluster
To see what GPU resources are available in your SageMaker HyperPod cluster, use the following code:
sky show-gpus --cloud k8s
This will list the available GPU types and their counts. We have two p5.48xlarge instances, each equipped with 8 NVIDIA H100 GPUs:
Launch an interactive development environment
With SkyPilot, you can launch a SkyPilot cluster for interactive development:
sky launch -c dev --gpus H100
This command creates an interactive development environment (IDE) with a single H100 GPU and will sync the local working directory to the cluster. SkyPilot handles the pod creation, resource allocation, and setup of the IDE.
After it’s launched, you can connect to your IDE:
ssh dev
This gives you an interactive shell in your IDE, where you can run your code, install packages, and perform ML experiments.
Run training jobs
With SkyPilot, you can run distributed training jobs on your SageMaker HyperPod cluster. The following is an example of launching a distributed training job using a YAML configuration file.
First, create a file named train.yaml with your training job configuration:
Then launch your training job:
sky launch -c train train.yaml
This creates a training job on a single p5.48xlarge nodes, equipped with 8 H100 NVIDIA GPUs. You can monitor the output with the following command:
sky logs train
Running multi-node training jobs with EFA
Elastic Fabric Adapter (EFA) is a network interface for Amazon Elastic Compute Cloud (Amazon EC2) instances that enables you to run applications requiring high levels of inter-node communications at scale on AWS through its custom-built operating system bypass hardware interface. This enables applications to communicate directly with the network hardware while bypassing the operating system kernel, significantly reducing latency and CPU overhead. This direct hardware access is particularly beneficial for distributed ML workloads where frequent inter-node communication during gradient synchronization can become a bottleneck. By using EFA-enabled instances such as p5.48xlarge or p6-b200.48xlarge, data scientists can scale their training jobs across multiple nodes while maintaining the low-latency, high-bandwidth communication essential for efficient distributed training, ultimately reducing training time and improving resource utilization for large-scale AI workloads.
The following code snippet shows how to incorporate this into your SkyPilot job:
Clean up
To delete your SkyPilot cluster, run the following command:
sky down <cluster_name>
To delete the SageMaker HyperPod cluster created in this post, you can user either the SageMaker AI console or the following AWS CLI command:
aws sagemaker delete-cluster --cluster-name <cluster_name>
Cluster deletion will take a few minutes. You can confirm successful deletion after you see no clusters on the SageMaker AI console.
If you used the CloudFormation stack to create resources, you can delete it using the following command:
aws cloudformation delete-stack --stack-name <stack_name>
Conclusion
By combining the robust infrastructure capabilities of SageMaker HyperPod with SkyPilot’s user-friendly interface, we’ve showcased a solution that helps teams focus on innovation rather than infrastructure complexity. This approach not only simplifies operations but also enhances productivity and resource utilization across organizations of all sizes. To get started, refer to SkyPilot in the Amazon EKS Support in Amazon SageMaker HyperPod workshop.
About the authors
 Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS. He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. He is passionate about computational optimization problems and improving the performance of AI workloads.
Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS. He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. He is passionate about computational optimization problems and improving the performance of AI workloads.
 Zhanghao Wu is a co-creator of the SkyPilot open source project and holds a PhD in computer science from UC Berkeley. He works on SkyPilot core, client-server architecture, managed jobs, and improving the AI experience on diverse cloud infrastructure in general.
Zhanghao Wu is a co-creator of the SkyPilot open source project and holds a PhD in computer science from UC Berkeley. He works on SkyPilot core, client-server architecture, managed jobs, and improving the AI experience on diverse cloud infrastructure in general.
 Ankit Anand is a Senior Foundation Models Go-To-Market (GTM) Specialist at AWS. He partners with top generative AI model builders, strategic customers, and AWS service teams to enable the next generation of AI/ML workloads on AWS. Ankit’s experience includes product management expertise within the financial services industry for high-frequency and low-latency trading and business development for Amazon Alexa.
Ankit Anand is a Senior Foundation Models Go-To-Market (GTM) Specialist at AWS. He partners with top generative AI model builders, strategic customers, and AWS service teams to enable the next generation of AI/ML workloads on AWS. Ankit’s experience includes product management expertise within the financial services industry for high-frequency and low-latency trading and business development for Amazon Alexa.