This post is co-written with Isaac Smothers and James Healy-Mirkovich from Crexi.
With the current demand for AI and machine learning (AI/ML) solutions, the processes to train and deploy models and scale inference are crucial to business success. Even though AI/ML and especially generative AI progress is rapid, machine learning operations (MLOps) tooling is continuously evolving to keep pace. Customers are looking for success stories about how best to adopt the culture and new operational solutions to support their data scientists. Solutions should be flexible to adopt, allow seamless integration with other systems, and provide a path to automate MLOps using AWS services and third-party tools, as we’ll explore in this post with Pulumi and Datadog. This framework helps to achieve operational excellence not only in the DevOps space but allows stakeholders to optimize tools such as infrastructure as code (IaC) automation and DevOps research and assessment (DORA) observability of pipelines for MLOps.
Commercial Real Estate Exchange, Inc. (Crexi), is a digital marketplace and platform designed to streamline commercial real estate transactions. It allows brokers to manage the entire process from listing to closing on one platform, including digital letters of intent, best and final offer negotiations, and transaction management tools. Its data and research features allow investors and other commercial real estate stakeholders to conduct due diligence and proactively connect with other professionals ahead of the transaction process.
In this post, we will review how Crexi achieved its business needs and developed a versatile and powerful framework for AI/ML pipeline creation and deployment. This customizable and scalable solution allows its ML models to be efficiently deployed and managed to meet diverse project requirements.
Datadog is a monitoring service for cloud-scale applications, bringing together data from servers, databases, tools and services to present a unified view of your entire stack. Datadog is a SaaS-based data analytics platform that enables Dev and Ops teams to work collaboratively to avoid downtime, resolve performance problems, and helps track that development and deployment cycles finish on time.
Pulumi’s modern infrastructure as code (IaC) platform empowers teams to manage cloud resources using their favorite languages including Python, JavaScript, TypeScript, Go, and C#. Pulumi’s open source SDK integrates with its free and commercial software as a service (SaaS) to simplify infrastructure provisioning, delivery, architecture, policy, and testing on a cloud.
Solution overview
Central to Crexi’s infrastructure are boilerplate AWS Lambda triggers that call Amazon SageMaker endpoints, executing any given model’s inference logic asynchronously. This modular approach supports complex pipeline pathways, with final results directed to Amazon Simple Storage Service (Amazon S3) and Amazon Data Firehose for seamless integration into other systems. One of the SageMaker endpoints also uses Amazon Textract, but any model can be used.
ML pipeline engineering requirements
The engineering requirements for the ML pipeline goal to build a robust infrastructure for model deployments are:
Rapid deployment of ML models: Model pipeline deployments should be managed through a continuous integration and continuous deployment (CI/CD) infrastructure, facilitating model pipeline rollbacks, regression testing, and click deploys. This automated CI/CD deployment process is used to automatically test and deploy pipeline changes, minimizing the risk of errors and downtime.
Distinct separation of concerns for production and development ML pipelines: This requirement prevents ongoing model experiments in the development environment from affecting the production environment, thereby maintaining the stability and reliability of the production models.
Model pipeline health monitoring: Health monitoring allows for proactive identification and resolution of potential issues in model pipelines before they impact downstream engineering teams and users.
Readily accessible models: Model pipelines should be accessible across engineering teams and straightforward to integrate into new and existing products.
The goal is to build reliable, efficient ML pipelines that can be used by other engineering teams with confidence.
Technical overview
The ML pipeline infrastructure is an amalgamation of various AWS products, designed to seamlessly invoke and retrieve output from ML models. This infrastructure is deployed using Pulumi, a modern IaC tool that allows Crexi to handle the orchestration of AWS products in a streamlined and efficient manner.
The AWS products managed by Pulumi in the infrastructure include:
Amazon Identity and Access Management (IAM) for secure access management
Amazon S3 for storing model tar.gz files and model prediction outputs, and Amazon SageMaker for model inference
AWS Lambda to send outputs from SageMaker models to one another
Amazon Simple Notification Service (Amazon SNS) is used to notify downstream teams when ML models produce predictions, helping to ensure timely communication and collaboration
Data Firehose to ship model predictions as needed, further enhancing the flexibility of the pipeline
To protect the robustness and reliability of the infrastructure, Crexi uses Datadog for pipeline log monitoring, which allows the team to keep a close eye on the pipeline’s performance and quickly identify and address issues that might arise.
Lastly, Crexi uses GitHub actions to run Pulumi scripts in a CI/CD fashion for ML pipeline deploys, updates, and destroys. These GitHub actions keep the infrastructure reproducible and sufficiently hardened against code regression.
Pipeline as code
Pulumi-managed ML pipelines are coded as YAML files that data scientists can quickly create and deploy. Deploying IaC using YAML files that data scientists can write has three key advantages:
Increased efficiency and speed: A streamlined deployment process allows data scientists to write and deploy their own models. Enabling data scientists in this way reduces delivery time by not requiring additional data engineering or ops personnel (that is, it reduces cross-functional dependencies) for deployments.
Flexibility and customization: YAML files allow data scientists to specify the necessary configurations such as instance types, model images, and additional permissions. This level of customization helps the team to optimize the deployed models for specific use cases.
Simplicity and readability: YAML files are human-readable, facilitating the evaluation, review, and auditing of infrastructure and deployment configurations.
Implementation
Now, let’s look at the implementation details of the ML pipeline.
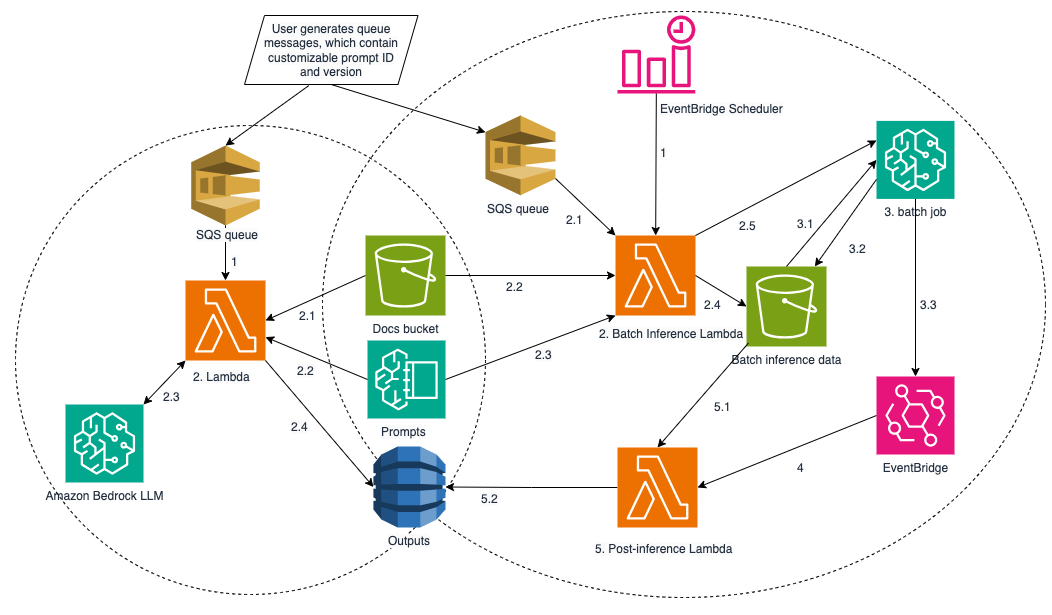
The pipeline contains three Sage Maker endpoints named model-a, model-b, and model-c. Each endpoint is asynchronous and has a specified number of running instances. They each have a specified docker image to run the model hosted on the endpoint, a specified location of the model.tar.gz file that the endpoint will host, and a specified type of machine instance to run the endpoint on. The model-b and model-c endpoints depend on the output from model-a.
The model-a endpoint has access to input Amazon S3 objects in the Crexi AWS account and depends on the crexi-model-input-dev bucket for input. Lastly, the model-c endpoint also has access to input S3 objects in the Crexi AWS account in addition to Amazon Textract.
After a new version of an input is uploaded to the crexi-model-input-dev S3 bucket, a Lambda function passes it to the model-a SageMaker endpoint. After results are ready and delivered to the model-a-model-output bucket, the relevant Lambda functions execute model-b and model-c SageMaker endpoints accordingly.
The visualization that follows depicts the pipeline flow.
To automate changes in the resources and new models, the Crexi team manages infrastructure using Pulumi and defines resources using YAML. SageMakerPipelineExample.yaml creates a stack of AWS resources that deploy service models to production. The AWS stack contains the necessary Lambda functions, S3 buckets, SageMaker endpoints, IAM permissions, and so on. As an example, the following is part of the YAML files that define the SageMaker endpoints.
Pipeline deployment
ML pipelines can be quickly deployed, modified, and destroyed using a continuous delivery GitHub workflow named Deploy self-service infrastructure that has been set up in a Crexi repository. After new models are tested and everything is ready in Crexi’s repository, GitHub workflow triggers deployment using Pulumi and a YAML file with resources defined in the previous section of this post.
The Deploy self-service infrastructure workflow takes four arguments:
branch
Description: GitHub branch to source the pipeline YAML file from
Input (options)
GitHub branch (for example, main)
action
Description: Specifies the type of Pulumi action to run
Input (options):
up: Create or update resources
destroy: Tear down resources
preview: Preview changes without applying them
environment
Description: Defines the environment against which the action will be executed
Input (options):
data_dev: Development environment
data_prod: Production environment
YAML
Description: Path to the infrastructure YAML file that defines the resources to be managed
Input (string)
Filename of SageMaker model pipeline YAML file to deploy, modify, or destroy
The following screenshot shows GitHub workflow parameters and history.
Pipeline Monitoring
Pipeline monitoring for Pulumi-deployed ML pipelines uses a comprehensive Datadog dashboard (shown in the following figure) that offers extensive logging capabilities and visualizations. Key metrics and logs are collected and visualized to facilitate real-time monitoring and historical analysis. Pipeline monitoring has dramatically simplified the assessment of a given pipeline’s health status, allowing for the rapid detection of potential bottlenecks and bugs, thereby improving operation of the ML pipelines.
The dashboard offers several core features:
Error tracking: The dashboard tracks 4xx and 5xx errors in aggregate, correlating errors to specific logged events within the model pipelines, which aids in quick and effective diagnosis by providing insights into the frequency and distribution of these errors.
Invocation metrics for SageMaker models: The dashboard aggregates data on instance resource utilization, invocation latency, invocation failures, and endpoint backlog for the SageMaker models deployed through Pulumi, giving a detailed view of performance bottlenecks and latencies.
Lambda function monitoring: The dashboard monitors the success and failure rates of invocations for triggerable Lambda functions, thus delivering a holistic view of the system’s performance.
Conclusion
The ML pipeline deployment framework explored here offers a robust, scalable, and highly customizable solution for AI/ML needs and addresses Crexi’s requirements. With the power to rapidly build and deploy pipelines, experiments and new ML techniques can be tested at scale with minimal effort. It separates development workflow of models and production deployments, and allows to proactively monitor for different issues. Additionally, routing model outputs to S3 supports seamless integration with Snowflake, facilitating storage and accessibility of data. This interconnected ecosystem does more than just improve current operations; it lays the groundwork for continuous innovation. The data housed in Snowflake serves as a rich resource for training new models that can be deployed quickly with new ML pipelines, enabling a cycle of improvement and experimentation that propels Crexi’s projects forward.
If you have any thoughts or questions, leave them in the comments section.
Isaac Smothers is a Senior DevOps Engineer at Crexi. Isaac focuses on automating the creation and maintenance of robust, secure cloud infrastructure with built-in observability. Based in San Luis Obispo, he is passionate about providing self-service solutions that enable developers to build, configure, and manage their services independently, without requiring cloud or DevOps expertise. In his free time, he enjoys hiking, video editing, and gaming.
James Healy-Mirkovich is a principal data scientist at Crexi in Los Angeles. Passionate about making data actionable and impactful, he develops and deploys customer-facing AI/ML solutions and collaborates with product teams to explore the possibilities of AI/ML. Outside work, he unwinds by playing guitar, traveling, and enjoying music and movies.
Marina Novikova is a Senior Partner Solution Architect at AWS. Marina works on the technical co-enablement of AWS ISV Partners in the DevOps and Data and Analytics segments to enrich partner solutions and solve complex challenges for AWS customers. Outside of work, Marina spends time climbing high peaks around the world.