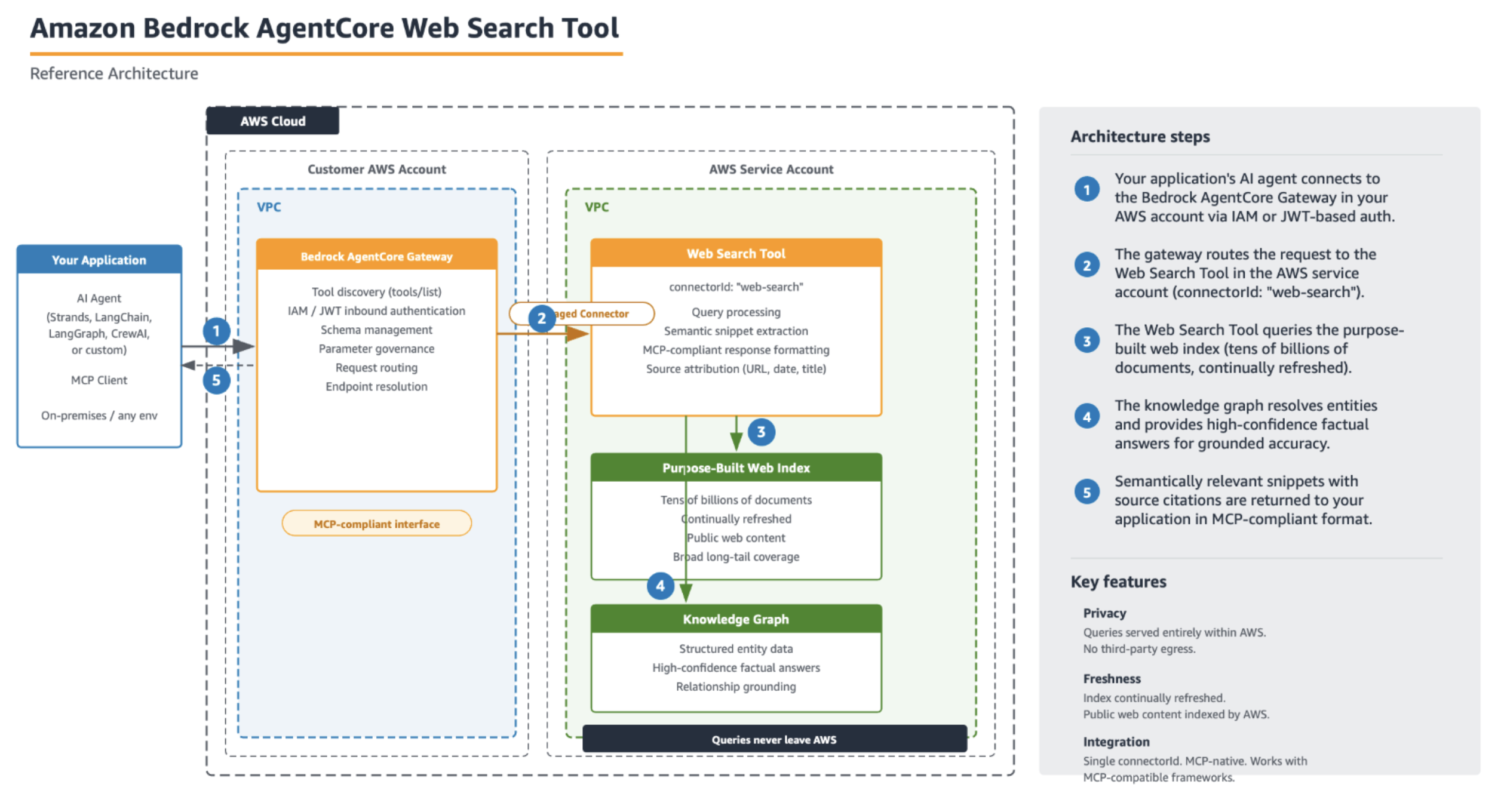
Today, we are excited to announce that the state-of-the-art Llama 3.1 collection of multilingual large language models (LLMs), which includes pre-trained and instruction tuned generative AI models in 8B, 70B, and 405B sizes, is available through Amazon SageMaker JumpStart to deploy for inference. Llama is a publicly accessible LLM designed for developers, researchers, and businesses to build, experiment, and responsibly scale their generative artificial intelligence (AI) ideas. In this post, we walk through how to discover and deploy Llama 3.1 models using SageMaker JumpStart.
Overview of Llama 3.1
The Llama 3.1 multilingual LLMs are a collection of pre-trained and instruction tuned generative models in 8B, 70B, and 405B sizes (text in/text and code out). All models support long context length (128,000) and are optimized for inference with support for grouped query attention (GQA). The Llama 3.1 instruction tuned text-only models (8B, 70B, 405B) are optimized for multilingual dialogue use cases and outperform many of the publicly available chat models on common industry benchmarks.
At its core, Llama 3.1 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety. Architecturally, the core LLM for Llama 3 and Llama 3.1 is the same dense architecture.
Llama 3.1 also offers instruct variants, and the instruct model is fine-tuned for tool use. The model has been trained to generate calls for a few specific tools for capabilities like search, image generation, code execution, and mathematical reasoning. In addition, the model supports zero-shot tool use.
The responsible use guide from Meta can assist you in performing additional fine-tuning that may be necessary to customize and optimize the models with appropriate safety mitigations.
Overview of SageMaker JumpStart
SageMaker JumpStart offers access to a broad selection of publicly available foundation models (FMs). These pre-trained models serve as powerful starting points that can be deeply customized to address specific use cases. You can now use state-of-the-art model architectures, such as language models, computer vision models, and more, without having to build them from scratch.
With SageMaker JumpStart, you can deploy models in a secure environment. The models are provisioned on dedicated SageMaker Inference instances, including AWS Trainium and AWS Inferentia powered instances, and are isolated within your virtual private cloud (VPC). This enforces data security and compliance, because the models operate under your own VPC controls, rather than in a shared public environment. After deploying an FM, you can further customize and fine-tune it using the extensive capabilities of Amazon SageMaker, including SageMaker Inference for deploying models and container logs for improved observability. With SageMaker, you can streamline the entire model deployment process.
Discover Llama 3.1 models in SageMaker JumpStart
SageMaker JumpStart provides FMs through two primary interfaces: Amazon SageMaker Studio and the SageMaker Python SDK. This provides multiple options to discover and use hundreds of models for your specific use case.
SageMaker Studio is a comprehensive integrated development environment (IDE) that offers a unified, web-based interface for performing all aspects of the machine learning (ML) development lifecycle. From preparing data to building, training, and deploying models, SageMaker Studio provides purpose-built tools to streamline the entire process. In SageMaker Studio, you can access SageMaker JumpStart to discover and explore the extensive catalog of FMs available for deployment to inference capabilities on SageMaker Inference.
Alternatively, you can use the SageMaker Python SDK to programmatically access and utilize SageMaker JumpStart models. This approach allows for greater flexibility and integration with existing AI and ML workflows and pipelines. By providing multiple access points, SageMaker JumpStart helps you seamlessly incorporate pre-trained models into your AI and ML development efforts, regardless of your preferred interface or workflow.
Deploy Llama 3.1 models for inference using SageMaker JumpStart
On the SageMaker JumpStart landing page, you can browse for solutions, models, notebooks, and other resources. You can find the Llama 3.1 models in the Foundation Models: Text Generation carousel.
If you don’t see the Llama 3.1 models, update your SageMaker Studio version by shutting down and restarting. For more information about version updates, refer to Shut down and Update Studio Classic Apps.
The following table lists the Llama 3.1 models you can access in SageMaker JumpStart.
Model Name
Description
Key Capabilities
Meta-Llama-3.1-8B
Llama-3.1-8B is a state-of-the-art publicly accessible model that excels at language nuances, contextual understanding, and complex tasks like translation and dialogue generation in 8 languages.
Top capabilities include multilingual support and stronger reasoning capabilities, enabling advanced use cases like long-form text summarization and multilingual conversational agents.
Meta-Llama-3.1-8B-Instruct
Llama-3.1-8B-Instruct is an update to Meta-Llama-3-8B-Instruct, an assistant-like chat model, that includes an expanded 128K context length, multilinguality, and improved reasoning capabilities.
Top capabilities include the ability to follow instructions and tasks, improved reasoning and understanding of nuances and context, and multilingual translation.
Meta-Llama-3.1-70B
Llama-3.1-70B is a state-of-the-art publicly accessible model that excels at language nuances, contextual understanding, and complex tasks like translation and dialogue generation in 8 languages.
Top capabilities include multilingual support and stronger reasoning capabilities, enabling advanced use cases like long-form text summarization, and multilingual conversational agents.
Meta-Llama-3.1-70B-Instruct
Llama-3.1-70B-Instruct is an update to Llama-3-70B-Instruct, an assistant-like chat model, that includes an expanded 128K context length, multilinguality, and improved reasoning capabilities.
Top capabilities include the ability to follow instructions and tasks, improved reasoning and understanding of nuances and context, and multilingual translation.
Meta-Llama-3.1-405B
Llama-3.1-405B is the largest, most capable publicly available FM, unlocking new applications and innovations, and paving the way for groundbreaking technologies like synthetic data generation and model distillation.
Llama-3.1-405B unlocks innovation with capabilities like general knowledge, steerability, math, tool use, and multilingual translation, enabling new possibilities for innovation and development.
Meta-Llama-3.1-405B-Instruct
Llama-3.1-405B-Instruct is the largest and most powerful of the Llama 3.1 Instruct models. It’s a highly advanced model for conversational inference and reasoning, synthetic data generation, and a base to do specialized continual pre-training or fine-tuning on a specific domain.
Llama-3.1-405B unlocks innovation with capabilities like general knowledge, steerability, math, tool use, and multilingual translation, enabling new possibilities for innovation and development.
Meta-Llama-3.1-405B-FP8
This is FP8 Quantized Version of Llama-3.1-405B.
Llama-3.1-405B unlocks innovation with capabilities like general knowledge, steerability, math, tool use, and multilingual translation, enabling new possibilities for innovation and development.
Meta-Llama-3.1-405B-Instruct-FP8
This is FP8 Quantized Version of Llama-3.1-405B-Instruct.
Llama-3.1-405B unlocks innovation with capabilities like general knowledge, steerability, math, tool use, and multilingual translation, enabling new possibilities for innovation and development.
You can choose the model card to view details about the model such as license, data used to train, and how to use. You can also find two buttons, Deploy and Open Notebook, which help you use the model.
When you choose either button, a pop-up window will show the End-User License Agreement (EULA) and acceptable use policy for you to accept.
Upon acceptance, you will proceed to the next step to use the model.
Deploy Llama 3.1 models for inference using the Python SDK
When you choose Deploy and accept the terms, model deployment will start. Alternatively, you can deploy through the example notebook by choosing Open Notebook. The notebook provides end-to-end guidance on how to deploy the model for inference and clean up resources.
To deploy using a notebook, you start by selecting an appropriate model, specified by the model_id. You can deploy any of the selected models on SageMaker.
You can deploy a Llama 3.1 405B model in FP8 using SageMaker JumpStart with the following SageMaker Python SDK code:
This deploys the model on SageMaker with default configurations, including default instance type and default VPC configurations. You can change these configurations by specifying non-default values in JumpStartModel. To successfully deploy the model, you must manually set accept_eula=True as a deploy method argument. After it’s deployed, you can run inference against the deployed endpoint through the SageMaker predictor:
The following table lists all the Llama models available in SageMaker JumpStart along with the model_ids, default instance types, and the maximum number of total tokens (sum of number of input tokens and number of generated tokens) supported for each of these models. For increased context length, customers can modify the default instance type in the SageMaker JumpStart UI.
Model Name
Model ID
Default instance type
Supported instance types
Meta-Llama-3.1-8B
meta-llama-3-1-8b
ml.g5.4xlarge (2,000 context length )
ml.g5.4xlarge, ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, ml.g5.4xlarge, ml.g5.8xlarge, ml.g6.12xlarge, ml.p4d.24xlarge, ml.p5.48xlarge
Meta-Llama-3.1-8B-Instruct
meta-llama-3-1-8b-instruct
ml.g5.4xlarge (2,000 context length )
Same as Llama-3.1-8B
Meta-Llama-3.1-70B
meta-llama-3-1-70b
ml.p4d.24xlarge (12,000 context length on 8 A100s)
ml.g5.48xlarge, ml.g6.48xlarge, ml.p4d.24xlarge, ml.p5.48xlarge
Meta-Llama-3.1-70B-Instruct
meta-llama-3-1-70b-instruct
ml.p4d.24xlarge (12,000 context length on 8 A100s)
Same as Llama-3.1-70B
Meta-Llama-3.1-405B
meta-llama-3-1-405b
ml.p5.48xlarge
2x ml.p5.48xlarge
Meta-Llama-3.1-405B-Instruct
meta-llama-3-1-405b-instruct
ml.p5.48xlarge
2x ml.p5.48xlarge
Meta-Llama-3.1-405B-FP8
meta-llama-3-1-405b-fp8
ml.p5.48xlarge (8,000 context length on 8 H100s)
ml.p5.48xlarge
Meta-Llama-3.1-405B-Instruct-FP8
meta-llama-3-1-405-instruct-fp8
ml.p5.48xlarge (8,000 context length on 8 H100s)
ml.p5.48xlarge
Inference and example prompts for Llama-3.1-405B-Instruct
You can use Llama models for text completion for any piece of text. Through text generation, you can perform a variety of tasks, such as question answering, language translation, sentiment analysis, and more. Input payload to the endpoint looks like the following code:
The roles should alternate between user and assistant while optionally starting with a system role.
In the next example, we show how to use Llama Instruct models within a conversational context, where a multi-turn chat is occurring between a user and an assistant. The first few rounds of the conversation are provided as input to the model:
This produces the following response:
Llama Guard
You can also use the Llama Guard model to help add guardrails for these models. Llama Guard provides input and output guardrails for LLM deployments. Llama Guard is a publicly available model that performs competitively on common open benchmarks and provides developers with a pre-trained model to help defend against generating potentially risky outputs. This model has been trained on a mix of publicly available datasets to enable detection of common types of potentially risky or violating content that may be relevant to a number of developer use cases.
You can use Llama Guard as a supplemental tool for developers to integrate into their own mitigation strategies, such as for chatbots, content moderation, customer service, social media monitoring, and education. By passing user-generated content through Llama Guard before publishing or responding to it, developers can flag unsafe or inappropriate language and take action to maintain a safe and respectful environment. Llama Guard is available on SageMaker JumpStart.
Conclusion
In this post, we explored how SageMaker JumpStart empowers data scientists and ML engineers to discover, access, and run a wide range of pre-trained FMs for inference, including Meta’s most advanced and capable models to date. Llama 3.1 models are available today in SageMaker JumpStart initially in the US East (N. Virginia), US East (Ohio), and US West (Oregon) AWS Regions. Get started with SageMaker JumpStart and Llama 3.1 models today.
Resources
For additional resources, refer to the following:
SageMaker JumpStart model catalog
Reduce model deployment costs by 50% on average using the latest features of Amazon SageMaker
Train, deploy, and evaluate pretrained models with SageMaker JumpStart
About the Authors
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on LinkedIn.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Jonathan Guinegagne is a Senior Software Engineer with Amazon SageMaker JumpStart at AWS. He got his master’s degree from Columbia University. His interests span machine learning, distributed systems, and cloud computing, as well as democratizing the use of AI. Jonathan is originally from France and now lives in Brooklyn, NY.
Christopher Whitten is a software developer on the JumpStart team. He helps scale model selection and integrate models with other SageMaker services. Chris is passionate about accelerating the ubiquity of AI across a variety of business domains.