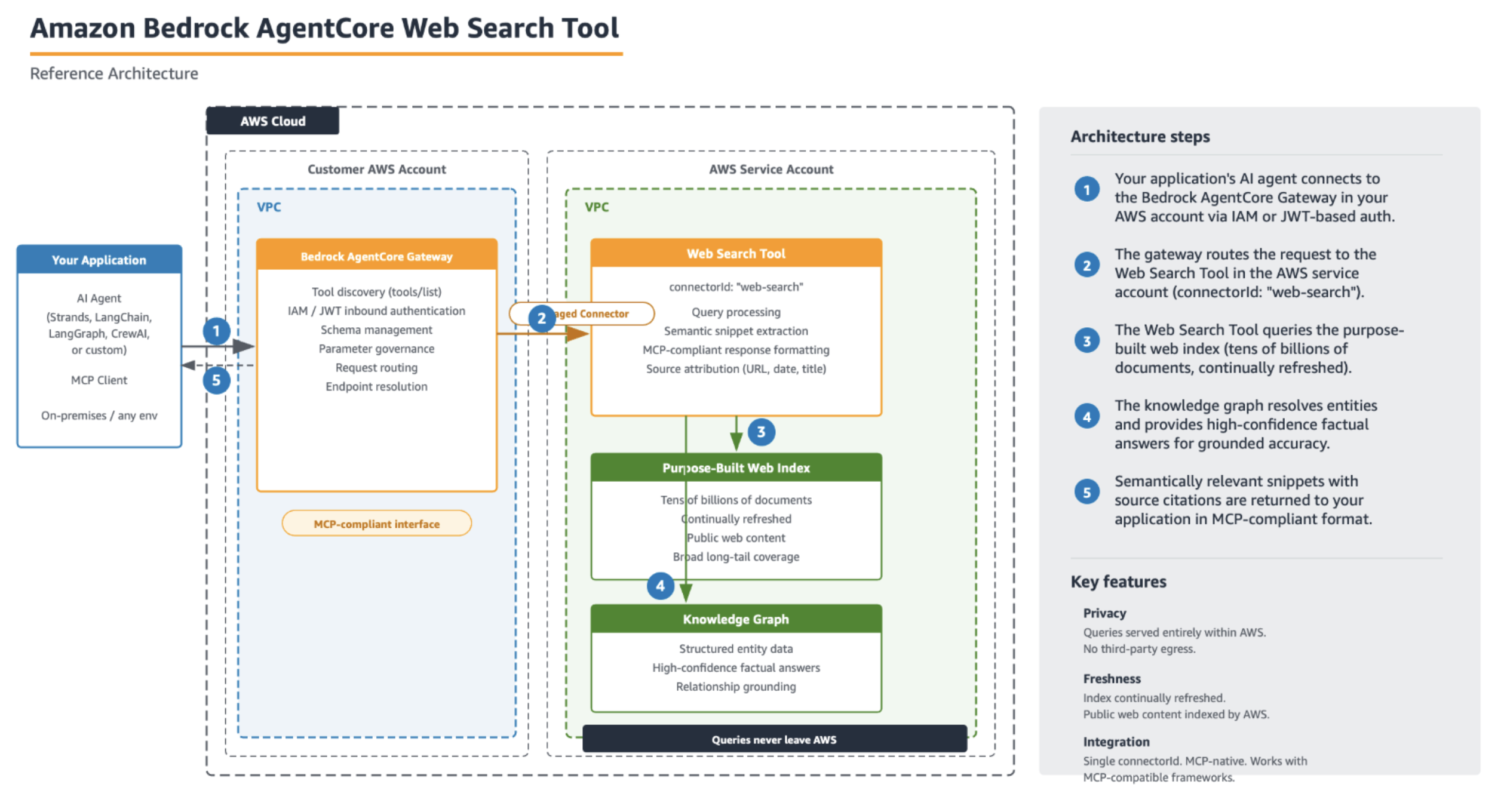
AWS announced the availability of the Cohere Command R fine-tuning model on Amazon SageMaker. This latest addition to the SageMaker suite of machine learning (ML) capabilities empowers enterprises to harness the power of large language models (LLMs) and unlock their full potential for a wide range of applications.
Cohere Command R is a scalable, frontier LLM designed to handle enterprise-grade workloads with ease. Cohere Command R is optimized for conversational interaction and long context tasks. It targets the scalable category of models that balance high performance with strong accuracy, enabling companies to move beyond proof of concept and into production. The model boasts high precision on Retrieval Augmented Generation (RAG) and tool use tasks, low latency and high throughput, a long 128,000-token context length, and strong capabilities across 10 key languages.
In this post, we explore the reasons for fine-tuning a model and the process of how to accomplish it with Cohere Command R.
Fine-tuning: Tailoring LLMs for specific use cases
Fine-tuning is an effective technique to adapt LLMs like Cohere Command R to specific domains and tasks, leading to significant performance improvements over the base model. Evaluations of fine-tuned Cohere Command R model have demonstrated improved performance by over 20% across various enterprise use cases in industries such as financial services, technology, retail, healthcare, legal, and healthcare. Because of its smaller size, a fine-tuned Cohere Command R model can be served more efficiently compared to models much larger than its class.
The recommendation is to use a dataset that contains at least 100 examples.
Cohere Command R uses a RAG approach, retrieving relevant context from an external knowledge base to improve outputs. However, fine-tuning allows you to specialize the model even further. Fine-tuning text generation models like Cohere Command R is crucial for achieving ultimate performance in several scenarios:
Domain-specific adaptation – RAG models may not perform optimally in highly specialized domains like finance, law, or medicine. Fine-tuning allows you to adapt the model to these domains’ nuances for improved accuracy.
Data augmentation – Fine-tuning enables incorporating additional data sources or techniques, augmenting the model’s knowledge base for increased robustness, especially with sparse data.
Fine-grained control – Although RAG offers impressive general capabilities, fine-tuning permits fine-grained control over model behavior, tailoring it precisely to your desired task for ultimate precision.
The combined power of RAG and fine-tuned LLMs empowers you to tackle diverse challenges with unparalleled versatility and effectiveness. With the introduction of Cohere Command R fine-tuning on SageMaker, enterprises can now customize and optimize the model’s performance for their unique requirements. By fine-tuning on domain-specific data, businesses can enhance Cohere Command R’s accuracy, relevance, and effectiveness for their use cases, such as natural language processing, text generation, and question answering.
By combining the scalability and robustness of Cohere Command R with the ability to fine-tune its performance on SageMaker, AWS empowers enterprises to navigate the complexities of AI adoption and use its transformative power to drive innovation and growth across various industries and domains.
Customer data, including prompts, completions, custom models, and data used for fine-tuning or continued pre-training, remains private to customer AWS accounts and is never shared with third-party model providers.
Solution overview
In the following sections, we walk through the steps to fine-tune the Cohere Command R model on SageMaker. This includes preparing the data, deploying a model, preparing for fine-tuning, creating an endpoint for inference, and performing inference.
Prepare the fine-tuning data
Before you can start a fine-tuning job, you need to upload a dataset with training and (optionally) evaluation data.
First, make sure your data is in jsonl format. It should have the following structure:
messages – This contains a list of messages of the conversation. A message consists of the following parts:
role – This specifies the current speaker. You can pick from System, User, or Chatbot.
content – This contains the content of the message.
The following is an example that trains a chatbot to answer questions. For the sake of readability, the document spans over multiple lines. For your dataset, make sure that each line contains one whole example.
Deploy a model
Complete the following steps to deploy the model:
On AWS Marketplace, subscribe to the Cohere Command R model
After you subscribe to the model, you can configure it and create a training job.
Choose View in Amazon SageMaker.
Follow the instructions in the UI to create a training job.
Alternatively, you can use the following example notebook to create the training job.
Prepare for fine-tuning
To fine-tune the model, you need the following:
Product ARN – This will be provided to you after you subscribe to the product.
Training dataset and evaluation dataset – Prepare your datasets for fine-tuning.
Amazon S3 location – Specify the Amazon Simple Storage Service (Amazon S3) location that stores the training and evaluation datasets.
Hyperparameters – Fine-tuning typically involves adjusting various hyperparameters like learning rate, batch size, number of epochs, and so on. You need to specify the appropriate hyperparameter ranges or values for your fine-tuning task.
Create an endpoint for inference
When the fine-tuning is complete, you can create an endpoint for inference with the fine-tuned model. To create the endpoint, use the create_endpoint method. If the endpoint already exists, you can connect to it using the connect_to_endpoint method.
Perform inference
You can now perform real-time inference using the endpoint. The following is the sample message that you use for input:
The following screenshot shows the output of the fine-tuned model.
Optionally, you can also test the accuracy of the model using the evaluation data (sample_finetune_scienceQA_eval.jsonl).
Clean up
After you have completed running the notebook and experimenting with the Cohere Command R fine-tuned model, it is crucial to clean up the resources you have provisioned. Failing to do so may result in unnecessary charges accruing on your account. To prevent this, use the following code to delete the resources and stop the billing process:
Summary
Cohere Command R with fine-tuning allows you to customize your models to be performant for your business, domain, and industry. Alongside the fine-tuned model, users additionally benefit from Cohere Command R’s proficiency in the most commonly used business languages (10 languages) and RAG with citations for accurate and verified information. Cohere Command R with fine-tuning achieves high levels of performance with less resource usage on targeted use cases. Enterprises can see lower operational costs, improved latency, and increased throughput without extensive computational demands.
Start building with Cohere’s fine-tuning model in SageMaker today.
About the Authors
Shashi Raina is a Senior Partner Solutions Architect at Amazon Web Services (AWS), where he specializes in supporting generative AI (GenAI) startups. With close to 6 years of experience at AWS, Shashi has developed deep expertise across a range of domains, including DevOps, analytics, and generative AI.
James Yi is a Senior AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys playing soccer, traveling and spending time with his family.
Pradeep Prabhakaran is a Customer Solutions Architect at Cohere. In his current role at Cohere, Pradeep acts as a trusted technical advisor to customers and partners, providing guidance and strategies to help them realize the full potential of Cohere’s cutting-edge Generative AI platform. Prior to joining Cohere, Pradeep was a Principal Customer Solutions Manager at Amazon Web Services, where he led Enterprise Cloud transformation programs for large enterprises. Prior to AWS, Pradeep has held various leadership positions at consulting companies such as Slalom, Deloitte, and Wipro. Pradeep holds a Bachelor’s degree in Engineering and is based in Dallas, TX.