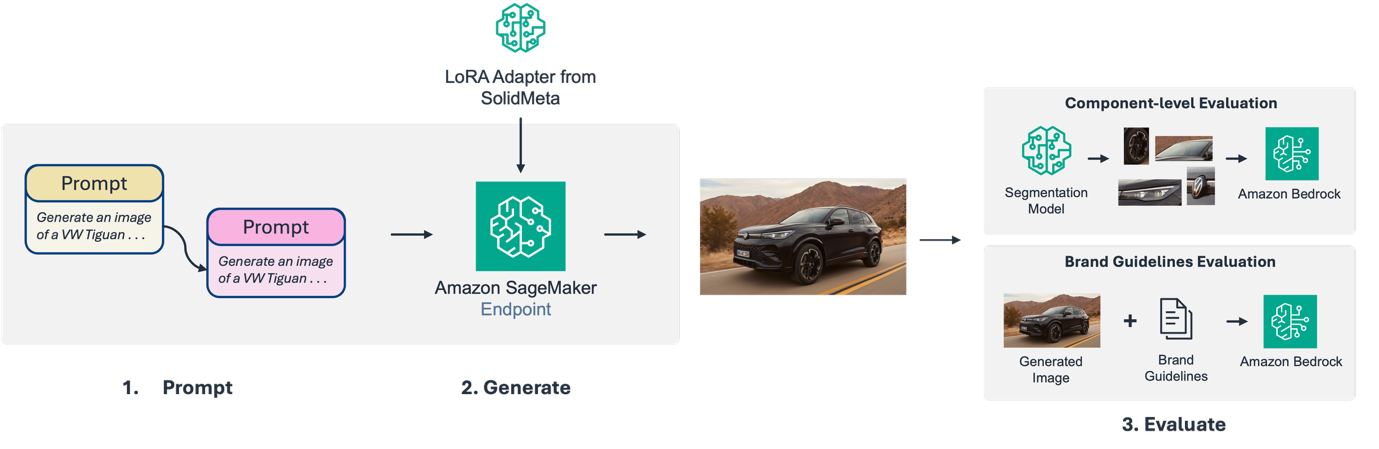
This post is cowritten with David Kim, and Premjit Singh from Ring.
Scaling self-service support globally presents challenges beyond translation. In this post, we show you how Ring, Amazon’s home security subsidiary, built a production-ready, multi-locale Retrieval-Augmented Generation (RAG)-based support chatbot using Amazon Bedrock Knowledge Bases. By eliminating per-Region infrastructure deployments, Ring reduced the cost of scaling to each additional locale by 21%. At the same time, Ring maintained consistent customer experiences across 10 international Regions.
In this post, you’ll learn how Ring implemented metadata-driven filtering for Region-specific content, separated content management into ingestion, evaluation and promotion workflows, and achieved cost savings while scaling up. The architecture described in this post uses Amazon Bedrock Knowledge Bases, Amazon Bedrock, AWS Lambda, AWS Step Functions, and Amazon Simple Storage Service (Amazon S3). Whether you’re expanding support operations internationally or looking to optimize your existing RAG architecture, this implementation provides practical patterns you can apply to your own multi-locale support systems.
The support evolution journey for Ring
Customer support at Ring initially relied on a rule-based chatbot built with Amazon Lex. While functional, the system had limitations with predefined conversation patterns that couldn’t handle the diverse range of customer inquiries. During peak periods, 16% of interactions escalated to human agents, and support engineers spent 10% of their time maintaining the rule-based system. As Ring expanded across international locales, this approach became unsustainable.
Requirements for a RAG-based support system
Ring faced a challenge: how to provide accurate, contextually relevant support across multiple international locales without creating separate infrastructure for each Region. The team identified four requirements that would inform their architectural approach.
- Global content localization
The international presence of Ring required more than translation. Each territory needed Region-specific product information, from voltage specifications to regulatory compliance details, provided through a unified system. Across the UK, Germany, and eight other locales, Ring needed to handle distinct product configurations and support scenarios for each Region.
- Serverless, managed architecture
Ring wanted their engineering team focused on improving customer experience, not managing infrastructure. The team needed a fully managed, serverless solution.
- Scalable knowledge management
With hundreds of product guides, troubleshooting documents, and support articles constantly being updated, Ring needed vector search technology that could retrieve precise information from a unified repository. The system had to support automated content ingestion pipelines so that the Ring content team could publish updates that would become available across multiple locales without manual intervention.
- Performance and cost optimization
The average end-to-end latency requirement for Ring was 7–8 seconds and performance analysis revealed that cross-Region latency accounted for less than 10% of total response time. This finding allowed Ring to adopt a centralized architecture rather than deploying separate infrastructure in each Region, which reduced operational complexity and costs.
To address these requirements, Ring implemented metadata-driven filtering with content locale tags. This approach serves Region-specific content from a single centralized system. For their serverless requirements, Ring chose Amazon Bedrock Knowledge Bases and Lambda, which removed the need for infrastructure management while providing automatic scaling.
Overview of solution
Ring designed their RAG-based chatbot architecture to separate content management into two core processes: Ingestion & Evaluation and Promotion. This two-phase approach allows Ring to maintain continuous content improvement while keeping production systems stable.
Ingestion and evaluation workflow
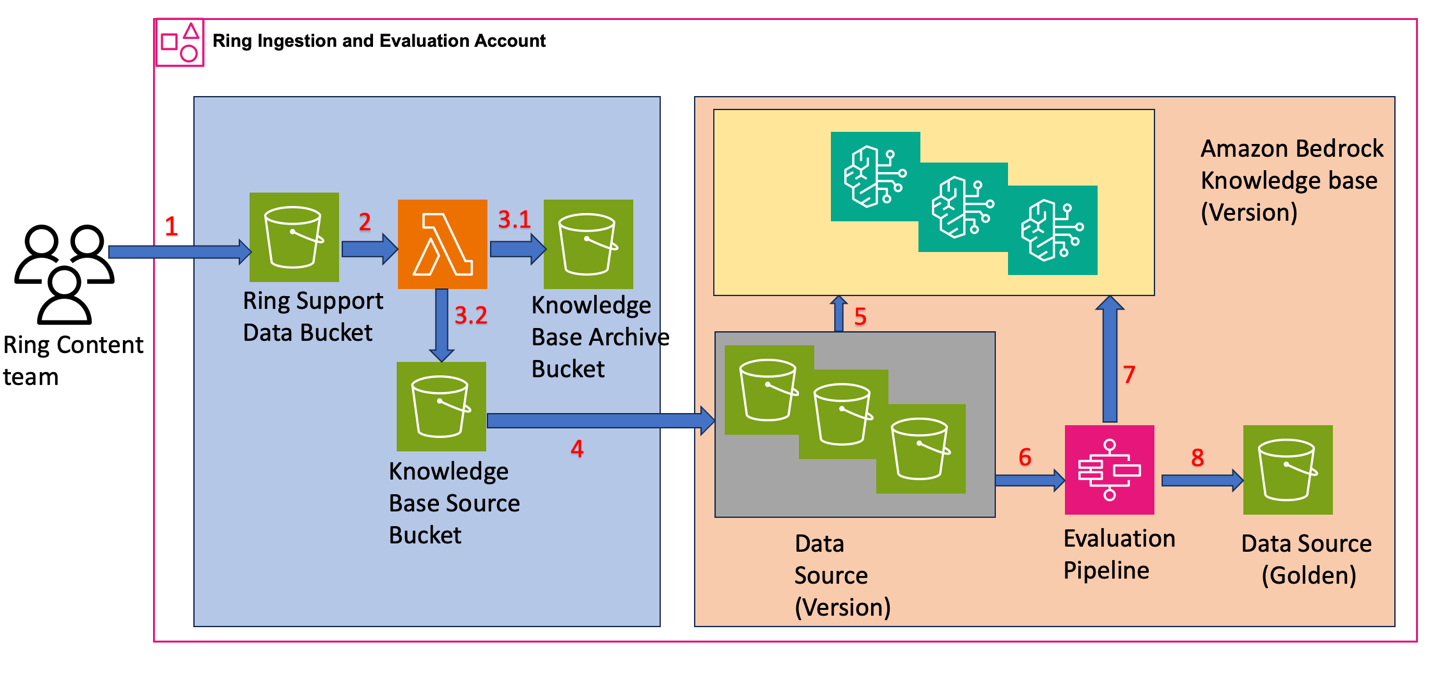
Figure 1: Architecture diagram showing the Ring ingestion and evaluation workflow with Step Functions orchestrating daily knowledge base creation, evaluation, and quality validation using Knowledge Bases and S3 storage.
- Content upload – The Ring content team uploads support documentation, troubleshooting guides, and product information to Amazon S3. The team structured the S3 objects with content in encoded format and metadata attributes. For example, a file for the content “Steps to Replace the doorbell battery” has the following structure:
- Content processing – Ring configured Amazon S3 bucket event notifications with Lambda as the target to automatically process uploaded content.
- Raw and processed content storage
The Lambda function performs two key operations:- Copies the raw data to the Knowledge Base Archive Bucket
- Extracts metadata and content from raw data, storing them as separate files in the Knowledge Base Source Bucket with
contentLocaleclassification (for example, {locale}/Service.Ring.{Upsert/Delete}.{unique_identifier}.json)
For the doorbell battery example, the Ring metadata and content files have the following structure:
{locale}/Service.Ring.{Upsert/Delete}.{unique_identifier}.metadata.json
{locale}/Service.Ring.{Upsert/Delete}.{unique_identifier}.json
- Daily Data Copy and Knowledge Base Creation
Ring uses AWS Step Functions to orchestrate their daily workflow that:
- Copies content and metadata from the Knowledge Base Source Bucket to Data Source (Version)
- Creates a new Knowledge Base (Version) by indexing the daily bucket as data source for vector embedding
Each version maintains a separate Knowledge Base, giving Ring independent evaluation capabilities and straightforward rollback options.
- Daily Evaluation Process
The AWS Step Functions workflow continues using evaluation datasets to:
- Run queries across Knowledge Base versions
- Test retrieval accuracy and response quality to compare performance between versions
- Publish performance metrics to Tableau dashboards with results organized by
contentLocale
- Quality Validation and Golden Dataset Creation
Ring uses the Anthropic Claude Sonnet 4 large language model (LLM)-as-a-judge to:
- Evaluate metrics across Knowledge Base versions to identify the best-performing version
- Compare retrieval accuracy, response quality, and performance metrics organized by
contentLocale - Promote the highest-performing version to Data Source (Golden) for production use
This architecture supports rollbacks to previous versions for up to 30 days. Because content is updated approximately 200 times per week, Ring decided not to maintain versions beyond 30 days.
Promotion workflow: customer-facing
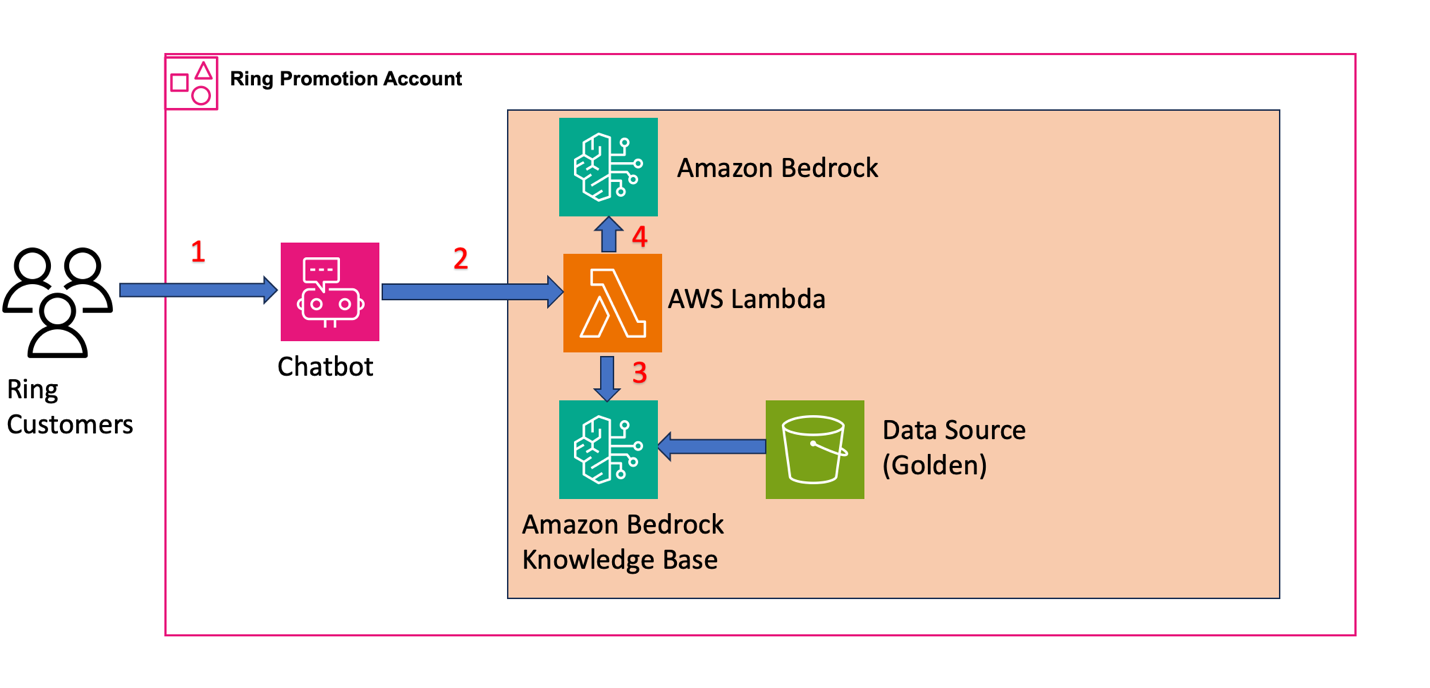
Figure 2: Architecture diagram showing the Ring production chatbot system where customer queries flow through AWS Lambda to retrieve context from Knowledge Bases and generate responses using foundation models
- Customer interaction – Customers initiate support queries through the chatbot interface. For example, a customer query for the battery replacement scenario looks like this:
- Query orchestration and knowledge retrieval
Ring configured Lambda to process customer queries and retrieve relevant content from Amazon Bedrock Knowledge Bases. The function:
- Transforms incoming queries for the RAG system
- Applies metadata filtering with
contentLocaletags using equals operator for precise Regional content targeting - Queries the validated Golden Data Source to retrieve contextually relevant content
Here’s the sample code Ring uses in AWS Lambda:
- Response generation
In the Lambda function, the system:
- Sorts the retrieved content based on relevance score and selects the highest-scoring context
- Combines the top-ranked context with the original customer query to create an augmented prompt
- Sends the augmented prompt to LLM on Amazon Bedrock
- Configures locale-specific prompts for each
contentLocale - Generates contextually relevant responses returned through the chatbot interface
Other considerations for your implementation
When building your own RAG-based system at scale, consider these architectural approaches and operational requirements beyond the core implementation:
Vector store selection
The Ring implementation uses Amazon OpenSearch Serverless as the vector store for their knowledge bases. However, Amazon Bedrock Knowledge Bases also supports Amazon S3 Vectors as a vector store option. When choosing between these options, consider:
- Amazon OpenSearch Serverless: Provides advanced search capabilities, real-time indexing, and flexible querying options. Best suited for applications requiring complex search patterns or when you need additional OpenSearch features beyond vector search.
- Amazon S3 vectors: Offers a more cost-effective option for straightforward vector search use cases. S3 vector stores provide automatic scaling, built-in durability, and can be more economical for large-scale deployments with predictable access patterns.
In addition to these two options, AWS supports integrations with other data store options, including Amazon Kendra, Amazon Neptune Analytics, and Amazon Aurora PostgreSQL. Evaluate your specific requirements around query complexity, cost optimization, and operational needs when selecting your vector store. The prescriptive guidance provides a good starting point to evaluate vector stores for your RAG use case.
Versioning architecture considerations
While Ring implemented separate Knowledge Bases for each version, you might consider an alternative approach involving separate data sources for each version within a single knowledge base. This method leverages the x-amz-bedrock-kb-data-source-id filter parameter to target specific data sources during retrieval:
When choosing between these approaches, weigh these specific trade-offs:
- Separate knowledge bases per version (the approach that Ring uses): Provides data source management and cleaner rollback capabilities, but requires managing more knowledge base instances.
- Single knowledge base with multiple data sources: Reduces the number of knowledge base instances to maintain, but introduces complexity in data source routing logic and filtering mechanisms, plus requires maintaining separate data stores for each data source ID.
Disaster recovery: Multi-Region deployment
Consider your disaster recovery requirements when designing your RAG architecture. Amazon Bedrock Knowledge Bases are Regional resources. To achieve robust disaster recovery, deploy your complete architecture across multiple Regions:
- Knowledge bases: Create Knowledge Base instances in multiple Regions
- Amazon S3 buckets: Maintain cross-Region copies of your Golden Data Source
- Lambda functions and Step Functions workflows: Deploy your orchestration logic in each Region
- Data synchronization: Implement processes to keep content synchronized across Regions
The centralized architecture serves its traffic from a single Region, prioritizing cost optimization over multi-region deployment. Evaluate your own Recovery Time Objective (RTO) and Recovery Point Objective (RPO) requirements to determine whether a multi-Region deployment is necessary for your use case.
Foundation model throughput: Cross-Region inference
Amazon Bedrock foundation models are Regional resources with Regional quotas. To handle traffic bursts and scale beyond single-Region quotas, Amazon Bedrock supports cross-Region inference (CRIS). CRIS automatically routes inference requests across multiple AWS Regions to increase throughput:
CRIS: Routes requests only within specific geographic boundaries (such as within the US or within the EU) to meet data residency requirements. This can provide up to double the default in-Region quotas.
Global CRIS: Routes requests across multiple commercial Regions worldwide, optimizing available resources and providing higher model throughput beyond geographic CRIS capabilities. Global CRIS automatically selects the optimal Region to process each request.
CRIS operates independently from your Knowledge Base deployment strategy. Even with a single-Region Knowledge Base deployment, you can configure CRIS to scale your foundation model throughput during traffic bursts. Note that CRIS applies only to the inference layer—your Knowledge Bases, S3 buckets, and orchestration logic remain Regional resources that require separate multi-Region deployment for disaster recovery.
Embedding model selection and chunking strategy
Selecting the appropriate embedding model and chunking strategy is important for RAG system performance because it directly affects retrieval accuracy and response quality. Ring uses the Amazon Titan Embeddings model with the default chunking strategy, which proved effective for their support documentation.
Amazon Bedrock offers flexibility with multiple options:
Embedding models:
- Amazon Titan embeddings: Optimized for text-based content
- Amazon Nova multimodal embeddings: Supports “Text”, “Image”, “Audio”, and “Video” modalities
Chunking strategies:
When ingesting data, Amazon Bedrock splits documents into manageable chunks for efficient retrieval using four strategies:
- Standard chunking: Fixed-size chunks for uniform documents
- Hierarchical chunking: For structured documents with clear section hierarchies
- Semantic chunking: Splits content based on topic boundaries
- Multimodal content chunking: For documents with mixed content types (text, images, tables)
Evaluate your content characteristics to select the optimal combination for your specific use case.
Conclusion
In this post, we showed how Ring built a production-ready, multi-locale RAG-based support chatbot using Amazon Bedrock Knowledge Bases. The architecture combines automated content ingestion, systematic daily evaluation using an LLM-as-judge approach, and metadata-driven content targeting to achieve a 21% reduction in infrastructure and operational cost per additional locale, while maintaining consistent customer experiences across 10 international Regions.
Beyond the core RAG architecture, we covered key design considerations for production deployments: vector store selection, versioning strategies, multi-Region deployment for disaster recovery, Cross-Region Inference for scaling foundation model throughput, embedding model selection and chunking strategies. These patterns apply broadly to any team building multi-locale or high-availability RAG systems on AWS.Ring continues to evolve their chatbot architecture toward an agentic model with dynamic agent selection and integration of multiple specialized agents. This agentic approach will allow Ring to route customer inquiries to specialized agents for device troubleshooting, order management, and product recommendations, demonstrating the extensibility of RAG-based support systems built on Amazon Bedrock.
To learn more about Amazon Bedrock Knowledge Bases, visit the Amazon Bedrock documentation.
About the authors