Foundation model training has reached an inflection point where traditional checkpoint-based recovery methods are becoming a bottleneck to efficiency and cost-effectiveness. As models grow to trillions of parameters and training clusters expand to thousands of AI accelerators, even minor disruptions can result in significant costs and delays.
In this post, we introduce checkpointless training on Amazon SageMaker HyperPod, a paradigm shift in model training that reduces the need for traditional checkpointing by enabling peer-to-peer state recovery. Results from production-scale validation show 80–93% reduction in recovery time (from 15–30 minutes or more to under 2 minutes) and enables up to 95% training goodput on cluster sizes with thousands of AI accelerators.
Understanding goodput
Foundation model training is one of the most resource-intensive processes in AI, often involving millions of dollars in compute spend across thousands of AI accelerators running for days to months. Because of the inherent all-or-none distributed synchrony across all ranks, even a loss of a single rank because of software or hardware faults brings the training workloads to a complete halt. To mitigate such localized faults, the industry has relied on checkpoint-based recovery; periodically saving training states (checkpoints) to a durable store based on a user-defined checkpoint interval. When a fault occurs, the training workload resumes by restoring from the latest saved checkpoint. This traditional restart-to-recover model has become increasingly untenable as model sizes grow from billions to trillions of parameters and training workloads grow from hundreds to thousands of AI accelerators.
This challenge of maintaining efficient training operations at scale has led to the concept of goodput—the actual useful work accomplished in an AI training system compared to its theoretical maximum capacity. In foundation model training, goodput is impacted by system failures and recovery overhead. The gap between the system’s theoretical maximum throughput and its actual productive output (goodput) grows larger with: increased frequency of failures (which rises with cluster size), longer recovery times (which scale with model size and cluster size), and higher costs of idle resources during recovery. This definition helps frame why measuring and optimizing goodput becomes increasingly crucial as AI training scales to larger clusters and more complex models, where even small inefficiencies can result in significant financial and time costs.
A pre-training workload on a HyperPod cluster with 256 P5 instances, checkpointing every 20 minutes, faces two challenges when disrupted: 10 minutes of lost work plus 10 minutes for recovery. With ml.p5.24xlarge instances costing $55 per hour, each disruption costs $4,693 in compute time. For a month-long training, daily disruptions would accumulate to $141,000 in extra costs and delay completion by 10 hours.
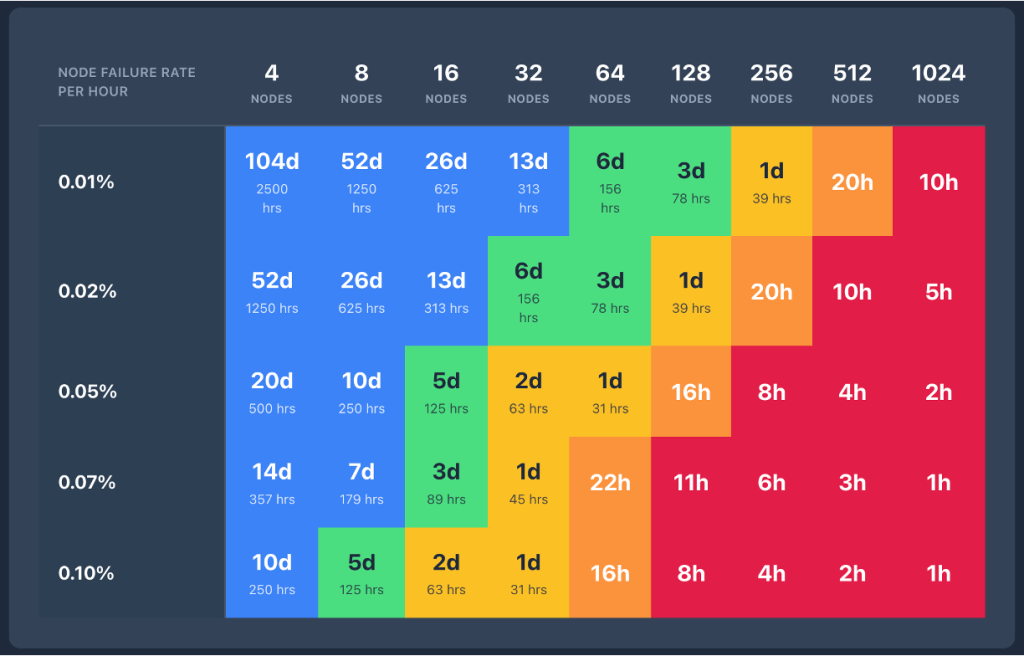
As cluster sizes grow, the probability and frequency of failures can increase.
As the training spans across thousands of nodes, disruptions caused by faults become increasingly frequent. Meanwhile, recovery becomes slower because the workload reinitialization overhead grows linearly with cluster size. The cumulative impact of large-scale AI training failures can reach millions of dollars annually and translate directly to delayed time-to-market, slower model iteration cycles, and competitive disadvantage. Every hour of idle GPU time is an hour not spent advancing model capabilities.
Checkpoint-based recovery
Checkpoint-based recovery in distributed training is far more complex and time-consuming than commonly understood. When a failure occurs in traditional distributed training, the restart process involves far more than loading the last checkpoint. Understanding what happens during recovery reveals why it takes so long and why the entire cluster must sit idle.
The all-or-none cascade
A single failure—one GPU error, one network timeout, or one hardware fault—can trigger a complete training cluster shutdown. Because distributed training treats all processes as tightly coupled, any single failure necessitates a complete restart. When any process fails, the orchestration system (for example, TorchElastic or Kubernetes) must terminate every process across the job and restart from scratch. Each restart requires navigating a complex, multi-stage recovery process where every stage is sequential and blocking:
- Stage 1: Training job restart – The training job orchestrator detects a failure, terminates all processes in all nodes followed by a cluster-wide restart or the training job.
- Stage 2: Process and network initialization – Every process must re-execute the training script from the beginning. That includes rank initialization, loading of Python modules from durable store such as Network File System (NFS) or object storage, establishing the training topology and communication backend through peer discovery and process groups creation. The process group initialization alone can take tens of minutes on large clusters.
- Stage 3: Checkpoint retrieval – Each process must first identify the last completely saved checkpoint, then retrieve it from persistent storage (for example, NFS or object storage) and load multiple state dictionaries: the model’s parameters and buffers, the optimizer’s internal state (momentum, variance, and so on), the learning rate scheduler, and training loop metadata (epoch, batch number). This step can take tens of minutes or longer depending on cluster and model size.
- Stage 4: Data loader initialization – The data-loading ranks have additional responsibility to initialize the data buffers. That includes retrieving the data checkpoint from durable storage such as Amazon FSx or Amazon Simple Storage Service (Amazon S3) and prefetching the training data to start the training loop. Data checkpointing is an essential step to avoid processing the same data samples multiple times or skipping samples upon training disruption. Depending on the data mix strategy, data locality, and bandwidth, the process can take a few minutes.
- Stage 5: First step overhead – After checkpoint and training data are retrieved and loaded, there is additional overhead to run the first training step, we call it first step overhead (FSO). During this first step, there is typically time spent in memory allocation, creating and setting up the CUDA context for communication with GPUs, and compilation part of the CUDA graph, and so on.
- Stage 6: Lost steps overhead – Only after all previous stages complete successfully can the training loop resume its regular progress. Because the training resumes from the last saved model checkpoint, all the steps computed between the checkpoint and the fault encountered are lost. Those lost steps need to be recomputed, we call this lost steps overhead (LSO). Following the recomputation phase, the training job resumes productive work that directly contributes to goodput.
How checkpointless training eliminates these bottlenecks
The five stages outlined above—termination and restart, process discovery and network setup, checkpoint retrieval, GPU context reinitialization, and training loop resumption—represent the fundamental bottlenecks in checkpoint-based recovery. Each stage is sequential and blocking, and training recovery can take minutes to several hours for large models. Critically, the entire cluster must wait for every stage to complete before training can resume.
Checkpointless training eliminates this cascade. Checkpointless training preserves model state coherence across the distributed cluster, eliminating the need for periodic snapshots. When failures occur, the system quickly recovers by using healthy peers, avoiding both storage I/O operations and full process restarts typically required by traditional checkpointing approaches.
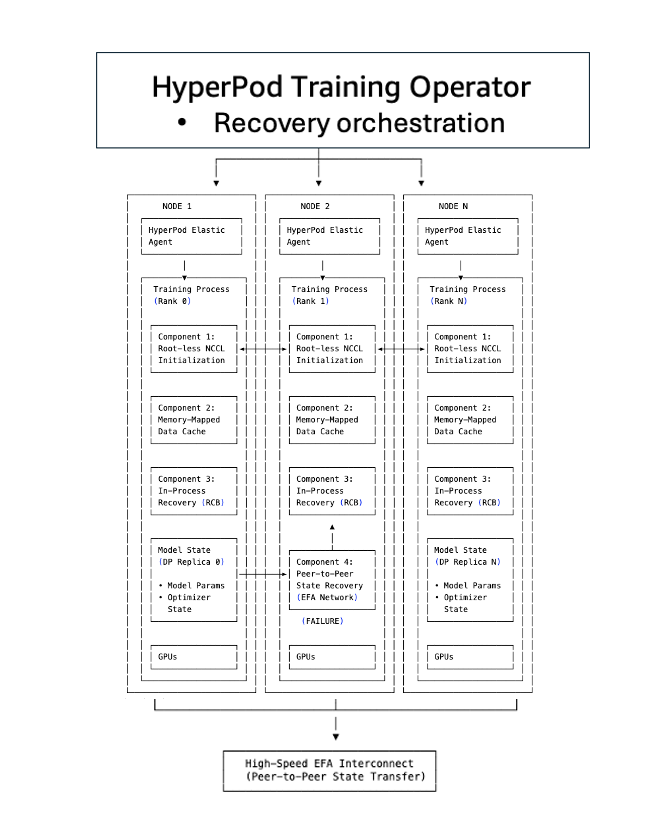
Checkpointless training architecture
Checkpointless training is built on five components that work together to eliminate the traditional checkpoint-restart bottlenecks. Each component addresses a specific bottleneck in the recovery process, and together they enable automatic detection and recovery of infrastructure faults in minutes with zero manual intervention, even with thousands of AI accelerators.
Component 1: TCPStore-less/root-less NCCL and Gloo initialization (optimizing stage 2)
In a typical distributed training setup (for example, using torch.distributed), all ranks must initialize a process group. The process group creates a communication layer, allowing all processes (or ranks, that is, individual nodes) to be aware of each other and exchange information. A TCPStore is often used as a rendezvous point where all ranks check in to discover each other’s connection information. When thousands of ranks try to contact a designated root server (typically rank 0) simultaneously, it becomes a bottleneck. This leads to a flood of simultaneous network requests to a single root server that can cause network congestion, increase latency by tens of minutes, and further slow the communication process.
Checkpointless training eliminates this centralized dependency. Instead of funneling all connection requests through a single root server, the system uses a symmetric address pattern where each rank independently computes peer connection information using a global group counter. Ranks connect directly to each other using predetermined port assignments, avoiding the TCPStore bottleneck. Process group initialization drops from tens of minutes to seconds, even on clusters with thousands of nodes. The system also eliminates the single-point-of-failure risk inherent in root-based initialization.
Component 2: Memory-mapped data loading (optimizing stage 4)
One of the hidden costs in traditional recovery is reloading training data. When a process restarts, it must reload batches from disk, rebuild data loader state, and carefully position itself to avoid processing duplicate samples or skipping data. On large-scale training runs, this data loading can add minutes to every recovery cycle.
Checkpointless training uses memory-mapped data loading to maintain cached data across accelerators. Training data is mapped into shared memory regions that persist even when individual processes fail. When a node recovers, it doesn’t reload data from disk but reconnects to the existing memory-mapped cache. The data loader state is preserved, helping to ensure that training continues from the correct position without duplicate or skipped samples. MMAP also reduces host CPU memory usage by maintaining only one copy of data per node (compared to eight copies with traditional data loaders on 8-GPU nodes), and training can resume immediately using cached batches while the data loader concurrently prefetches the next data in the background.
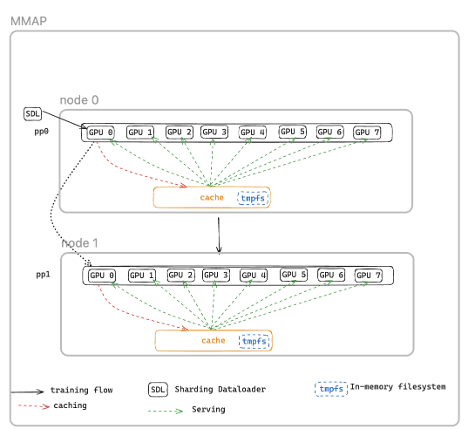
Memory-mapped data loading workflow
Component 3: In-process recovery (optimizing stage 1, 2, and 5)
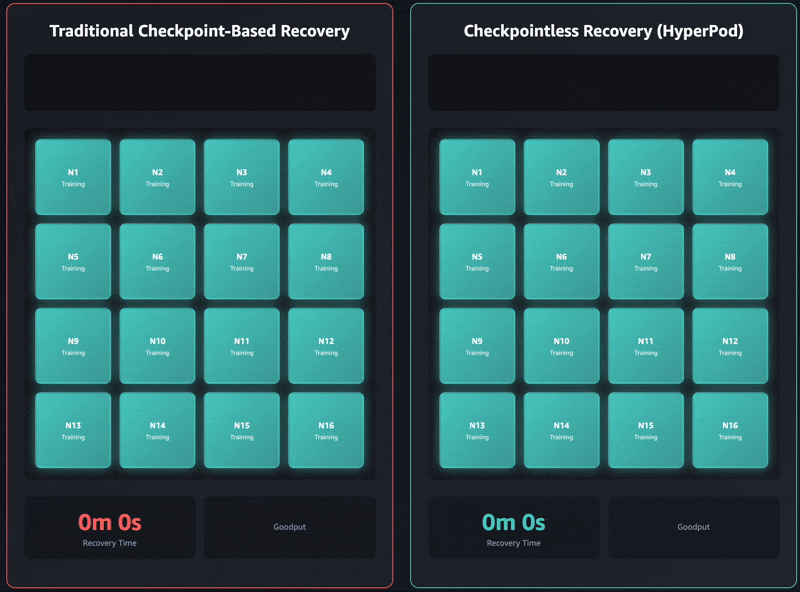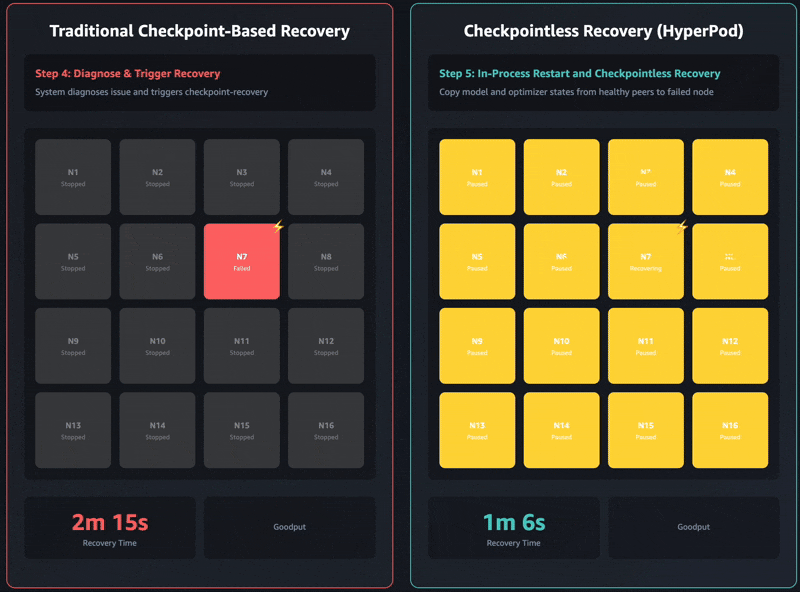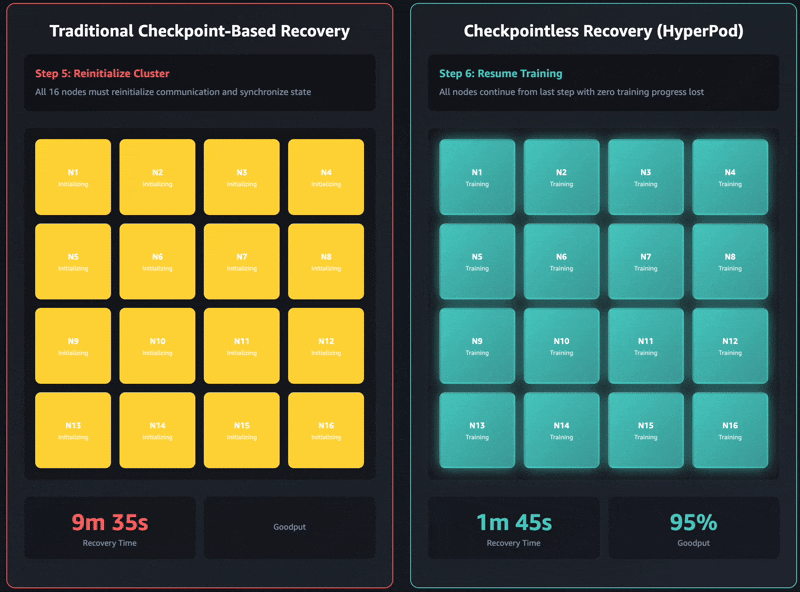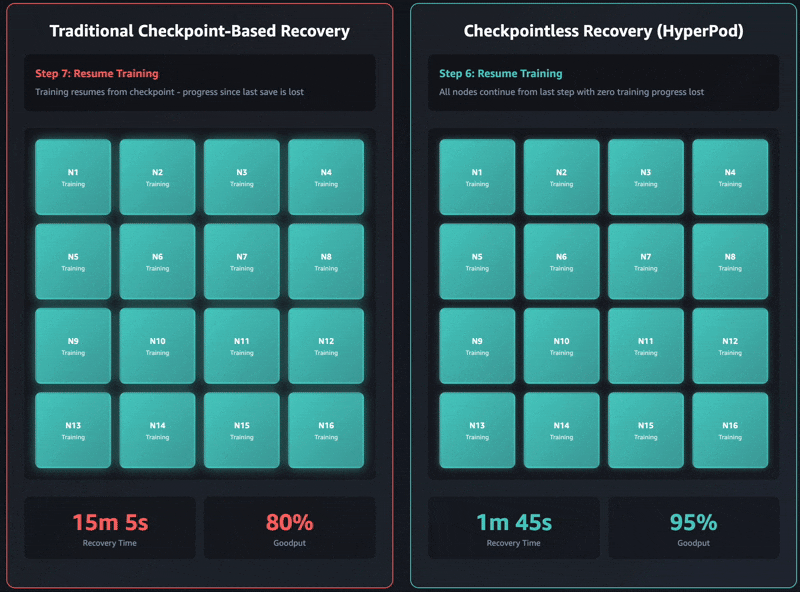
Traditional checkpoint-based recovery treats failures as job-level events: a single GPU error triggers termination of the entire distributed training job. Every process across the cluster must be killed and restarted, even though only one component failed.
Checkpointless training uses in-process recovery to isolate failures at the process level. When a GPU or process fails, only the failed process executes an in-process recovery to rejoin the training loop within seconds, overcoming recoverable or transient errors. Healthy processes continue running without interruption. The failed process stays alive (avoiding full process teardown), preserving the CUDA context, compiler cache, and GPU state, hence eliminating minutes of reinitialization overhead. In cases where the error is non-recoverable (such as hardware failure), the system automatically swaps the faulty component with a pre-warmed hot spare, enabling training to continue without disruptions.
This eliminates the need for full cluster termination and restart, dramatically reducing recovery overhead.
Component 4: Peer-to-peer state replication (optimizing stage 3 and 6)
Checkpoint-based recovery requires loading model and optimizer state from persistent storage (such as Amazon S3 or FSx for Lustre). For models with billions to trillions of parameters, this means transferring tens to hundreds of gigabytes over the network, deserializing state dictionaries, and reconstructing optimizer buffers which could take tens of minutes and create a massive I/O bottleneck.
The most critical innovation in checkpointless training is continuous peer-to-peer state replication. Instead of periodically saving model state to centralized storage, each GPU maintains redundant copies of its model shards on peer GPUs. When a failure occurs, the recovering process doesn’t load from Amazon S3. It copies state directly from a healthy peer over the high-speed Elastic Fabric Adapter (EFA) network interconnect. This peer-to-peer architecture eliminates the I/O bottleneck that dominates traditional checkpoint recovery. State transfer happens in seconds, compared to minutes for loading multi-gigabyte checkpoints from storage. The recovering node pulls only the specific shards it needs, further reducing transfer time.
Component 5: SageMaker HyperPod training operator (optimizing all stages)
The SageMaker HyperPod training operator orchestrates the checkpointless training components, serving as the coordination layer that ties together initialization, data loading, checkpointless recovery, and checkpoint fallback mechanisms. It maintains a centralized control plane with a global view of training process health across the entire cluster, coordinating fault detection, recovery decisions, and cluster-wide synchronization.
The operator implements intelligent recovery escalation: it first attempts in-process restart for failed components, and if that’s not feasible (for example, because of container crashes or node failures), it escalates to process-level recovery. During a process-level recovery, instead of restarting the entire job when failures occur, the operator restarts only training processes, keeping the containers alive. As a result, the recovery times are faster than a job-level restart, which requires tearing down and recreating the training infrastructure, involving pod rescheduling, container pulls, environment initialization, and re-loading from checkpoints. When failures occur, the operator broadcasts coordinated stop signals to prevent cascading timeouts and integrates with the SageMaker HyperPod health-monitoring agent to automatically detect hardware issues and trigger recovery without manual intervention.
Getting started with checkpointless training
This section guides you through setting up and configuring checkpointless training on SageMaker HyperPod to reduce fault recovery from hours to minutes.
Prerequisites
Before integrating checkpointless training into your training workload, verify that your environment meets the following requirements:
Infrastructure requirements:
- Amazon SageMaker HyperPod cluster orchestrated by Amazon Elastic Kubernetes Service (Amazon EKS)
- HyperPod training operator v1.2 or later installed on the cluster
- Recommended instance types: ml.p5., p5e., or p5en.48xlarge, ml.p6.p6-b200.48xlarge, or ml.p6e-gb200.36xlarge
- Minimum cluster size: Two nodes for peer-to-peer checkpointless recovery
Software requirements:
- Supported frameworks: Nemo, PyTorch, PyTorch Lightning
- Training data formats: JSON, JSONGZ (compressed JSON), or ARROW
- Amazon Elastic Container Registry (Amazon ECR) repository for container images. Use the HyperPod checkpointless training container—required for rootless NCCL initialization (Tier 1) and peer-to-peer checkpointless recovery (Tier 4)
Checkpointless training workflow
Checkpointless training is designed for incremental adoption. You can start with basic capabilities and progressively enable advanced features as your training scales. The integration is organized into four tiers, each building on the previous one:
Tier 1: NCCL initialization optimization
NCCL initialization optimization eliminates the centralized root process bottleneck during initialization. Nodes discover and connect to peers independently using infrastructure signals. This enables faster process group initialization (seconds instead of minutes) and elimination of single-point-of-failure during startup.
Integration steps: Enable an environment variable as part of the job specification and verify that the job runs with the checkpointless training container.
Tier 2: Memory-mapped data loading
Memory mapped data loading keeps training data cached in shared memory across process restarts, eliminating data reload overhead during recovery. This enables instant data access during recovery. No need to reload or re-shuffle data when a process restarts.
Integration steps: Augment the existing data loader with a memory mapped cache
Tier 3: In-process recovery
In-process recovery isolates failures to individual processes instead of requiring full job restarts. Failed processes recover independently while healthy processes continue training. It enables sub-minute recovery from process-level failures. Healthy processes stay alive, while failed processes recover independently.
Integration steps:
Tier 4: Checkpointless (peer-to-peer recovery) (NeMo integration)
Checkpointless recovery enables complete peer-to-peer state replication and recovery. Failed processes recover model and optimizer state directly from healthy peers without loading from storage. This step enables elimination of checkpoint loading. Failed processes recover model and optimizer state from healthy replicas over the high-speed EFA interconnect.
Integration steps:
wait_rank: All ranks will wait for the rank information from the Hyperod training operator infrastructure.
HPWrapper: Python function wrapper that enables restart capabilities for a restart code block (RCB). The implementation uses a context manager instead of a Python decorator because the call wrapper lacks information about the number of RCBs it should monitor.
CudaHealthCheck: Helps ensure that the CUDA context for the current process is in a healthy state. It synchronizes with the GPU and uses the device corresponding to LOCAL_RANK environment variable, or the main thread’s default CUDA device if LOCAL_RANK was not specified in the environment.
HPAgentK8sAPIFactory: This is the API that checkpointless training will use to understand the training status from the other pods in a K8s training cluster. It also provides an infrastructure-level barrier, which makes sure every rank can successfully perform the abort and restart.
CheckpointManager: Manages in-memory checkpoints and peer-to-peer recovery for checkpointless fault tolerance.
We recommend starting with Tier 1 and validating it in your environment. Add Tier 2 when data loading overhead becomes a bottleneck. Adopt Tier 3 and Tier 4 for maximum resilience on the largest training clusters.
For NeMo users and HyperPod recipe users, Tier 4 is available out-of-the-box with minimal configuration changes for Llama and GPT open source recipes. NeMo examples for Llama and GPT open source models can be found in SageMaker HyperPod checkpointless training.
Performance results
Checkpointless training has been validated at production scale across multiple cluster configurations. The latest Amazon Nova models were trained using this technology on tens of thousands of AI accelerators.
In this section, we demonstrate results from extensive testing across a range of cluster sizes, spanning 16 GPUs to 2,304 GPUs. Checkpointless training demonstrated significant improvements in recovery time, consistently reducing downtime by 80–93% compared to traditional checkpoint-based recovery.
| Cluster (H100s) | Model | Traditional recovery | Checkpointless recovery | Improvement |
|---|---|---|---|---|
| 2,304 GPUs | Internal model | 15–30 minutes | Less than 2 minutes | ~87–93% faster |
| 256 GPUs | Llama-3 70B (pre-training) | 4 min, 52 sec | 47 seconds | ~84% faster |
| 16 GPUs | Llama-3 70B (fine-tuning) | 5 min 10 sec | 50 seconds | ~84% faster |
These recovery time improvements have a direct relationship to ML goodput, defined as the percentage of time your cluster spends making forward progress on training rather than sitting idle during failures. As clusters scale to thousands of nodes, failure frequency increases proportionally. At the same time, traditional checkpoint-based recovery times also increase with cluster size due to growing coordination overhead. This creates a compounding problem: more frequent failures combined with longer recovery times rapidly erode goodput at scale.
Checkpointless training makes optimizations across the entire recovery stack, enabling more than 95% goodput even on clusters with thousands of AI accelerators. Based on our internal studies, we consistently observed goodput upwards of 95% across massive-scale deployments that exceeded 2,300 GPUs.
We also verified that model training accuracy is not impacted by checkpointless training. Specifically, we measured checksum matching for traditional checkpoint-based training and checkpointless training, and at every training step verified a bit-wise match on training loss. The following is a plot for the training loss for a Llama-3 70B pre-training workload on 32 x ml.p5.48xlarge instances for both traditional checkpointing versus checkpointless training.

Conclusion
Foundation model training has reached an inflection point. As clusters scale to thousands of AI accelerators and training runs extend to months, the traditional checkpoint-based recovery paradigm is increasingly becoming a bottleneck. A single GPU failure that previously would have caused minutes of downtime now triggers tens of minutes of cluster-wide idle time on thousands of AI accelerators, with cumulative costs reaching millions of dollars annually.
Checkpointless training rethinks this paradigm entirely by treating failures as local, recoverable events rather than cluster-wide catastrophes. Failed processes recover state from healthy peers in seconds, enabling the rest of the cluster to continue making forward progress. The shift is fundamental: from How do we restart quickly? to How do we avoid stopping at all?
This technology has enabled more than 95% goodput when training on SageMaker HyperPod. Our internal studies on 2,304 GPUs show recovery times dropped from 15–30 minutes to under 90 seconds, translating to over 80% reduction in idle GPU time per failure.
To get started, explore What is Amazon SageMaker AI?. Sample implementations and recipes are available in the AWS GitHub HyperPod checkpointless training and SageMaker HyperPod recipes repositories.
About the Authors
 Anirudh Viswanathan is a Senior Product Manager, Technical, at AWS with the SageMaker team, where he focuses on Machine Learning. He holds a Master’s in Robotics from Carnegie Mellon University and an MBA from the Wharton School of Business. Anirudh is a named inventor on more than 50 AI/ML patents. He enjoys long-distance running, exploring art galleries, and attending Broadway shows. You can connect with Anirudh on LinkedIn.
Anirudh Viswanathan is a Senior Product Manager, Technical, at AWS with the SageMaker team, where he focuses on Machine Learning. He holds a Master’s in Robotics from Carnegie Mellon University and an MBA from the Wharton School of Business. Anirudh is a named inventor on more than 50 AI/ML patents. He enjoys long-distance running, exploring art galleries, and attending Broadway shows. You can connect with Anirudh on LinkedIn.
 Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS. He helps AWS customers, from small startups to large enterprises to train and deploy foundation models efficiently on AWS. He has a background in Microprocessor Engineering passionate about computational optimization problems and improving the performance of AI workloads. You can connect with Roy on LinkedIn.
Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS. He helps AWS customers, from small startups to large enterprises to train and deploy foundation models efficiently on AWS. He has a background in Microprocessor Engineering passionate about computational optimization problems and improving the performance of AI workloads. You can connect with Roy on LinkedIn.
 Fei Wu is a Senior Software Developer at AWS with Sagemaker team. Fei’s focus is on ML system and distributed training techniques. He holds a PhD in Electrical Engineering from StonyBrook University. When outside of work, Fei enjoys playing basketball and watching movies. You can connect with Fei on LinkedIn.
Fei Wu is a Senior Software Developer at AWS with Sagemaker team. Fei’s focus is on ML system and distributed training techniques. He holds a PhD in Electrical Engineering from StonyBrook University. When outside of work, Fei enjoys playing basketball and watching movies. You can connect with Fei on LinkedIn.
 Trevor Harvey is a Principal Specialist in Generative AI at Amazon Web Services (AWS) and an AWS Certified Solutions Architect – Professional. At AWS, Trevor works with customers to design and implement machine learning solutions and leads go-to-market strategies for generative AI services.
Trevor Harvey is a Principal Specialist in Generative AI at Amazon Web Services (AWS) and an AWS Certified Solutions Architect – Professional. At AWS, Trevor works with customers to design and implement machine learning solutions and leads go-to-market strategies for generative AI services.
 Anirban Roy is a Principal Engineer at AWS with the SageMaker team, primarily focussing on AI training infra, resiliency and observability. He holds a Master’s in Computer Science from Indian Statistical Institute in Kolkata. Anirban is a seasoned distributed software system builder with more than 20 years of experience and multiple patents and publications. He enjoys road biking, reading non-fiction, gardening and nature traveling. You can connect with Anirban on LinkedIn
Anirban Roy is a Principal Engineer at AWS with the SageMaker team, primarily focussing on AI training infra, resiliency and observability. He holds a Master’s in Computer Science from Indian Statistical Institute in Kolkata. Anirban is a seasoned distributed software system builder with more than 20 years of experience and multiple patents and publications. He enjoys road biking, reading non-fiction, gardening and nature traveling. You can connect with Anirban on LinkedIn
 Arun Nagarajan is a Principal Engineer on the Amazon SageMaker AI team, where he currently focuses on distributed training across the entire stack. Since joining the SageMaker team during its launch year, Arun has contributed to multiple products within SageMaker AI, including real-time inference and MLOps solutions. When he’s not working on machine learning infrastructure, he enjoys exploring the outdoors in the Pacific Northwest and hitting the slopes for skiing.
Arun Nagarajan is a Principal Engineer on the Amazon SageMaker AI team, where he currently focuses on distributed training across the entire stack. Since joining the SageMaker team during its launch year, Arun has contributed to multiple products within SageMaker AI, including real-time inference and MLOps solutions. When he’s not working on machine learning infrastructure, he enjoys exploring the outdoors in the Pacific Northwest and hitting the slopes for skiing.