Large-scale AI model training faces significant challenges with failure recovery and monitoring. Traditional training requires complete job restarts when even a single training process fails, resulting in additional downtime and increased costs. As training clusters expand, identifying and resolving critical issues like stalled GPUs and numerical instabilities typically requires complex custom monitoring code.
With Amazon SageMaker HyperPod you can accelerate AI model development across hundreds or thousands of GPUs with built-in resiliency, decreasing model training time by up to 40%. The Amazon SageMaker HyperPod training operator further enhances training resilience for Kubernetes workloads through pinpoint recovery and customizable monitoring capabilities.
In this blog post, we show you how to deploy and manage machine learning training workloads using the Amazon SageMaker HyperPod training operator, including setup instructions and a complete training example.
Amazon SageMaker HyperPod training operator
The Amazon SageMaker HyperPod training operator helps you accelerate generative AI model development by efficiently managing distributed training across large GPU clusters. The Amazon SageMaker HyperPod training operator uses built-in fault resiliency components, comes packaged as an Amazon Elastic Kubernetes Service (Amazon EKS) add-on, and deploys the necessary custom resource definitions (CRDs) to the HyperPod cluster.
Solution overview
The following diagram depicts the architecture of Amazon SageMaker HyperPod training operator.
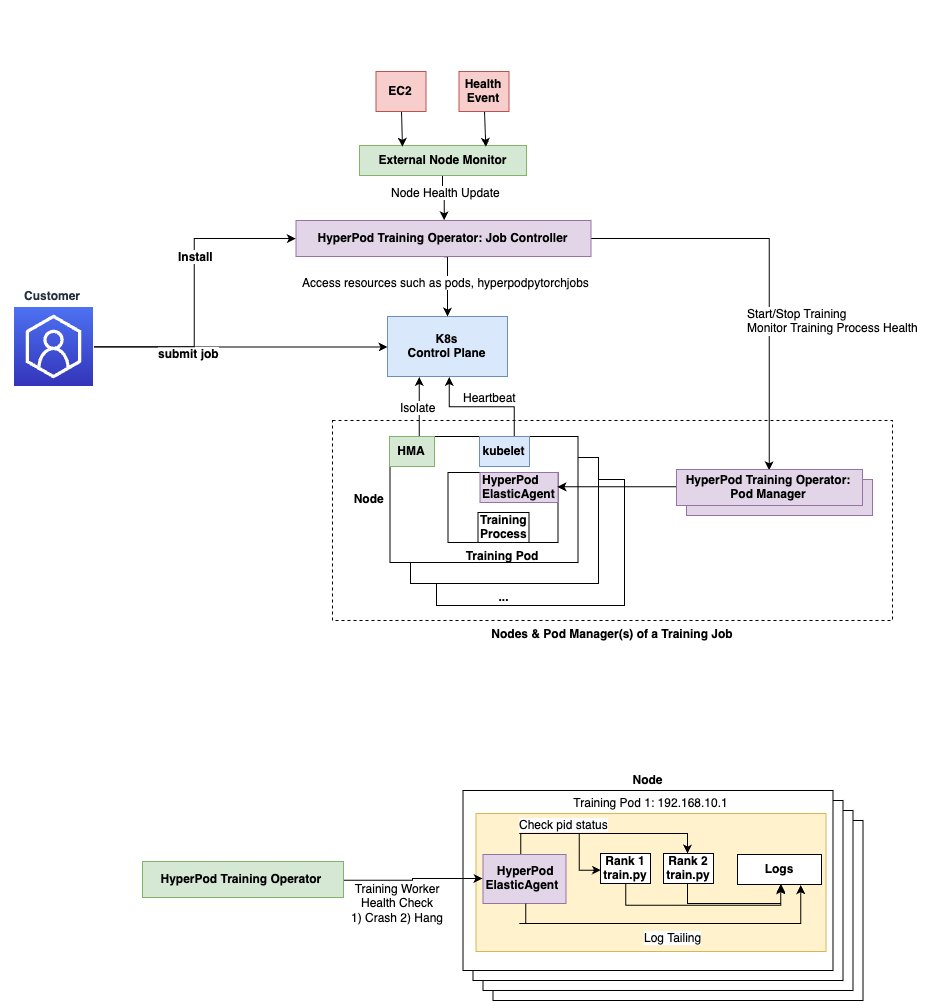
The HyperPod training operator follows Kubernetes operator pattern and has the following major components:
- Custom Resource Definition (CRDs):
HyperPodPyTorchJobdefines the job specification (for example, node count, image) and serves as the interface for customers to submit jobs.
apiVersion: sagemaker.amazonaws.com/v1
kind: HyperPodPyTorchJob - RBAC policies: Defines the actions the controller is allowed to perform, such as creating pods and managing
HyperPodPyTorchJobresources. - Job controller: Listens to job creation and fulfills requests by creating job pods and pod managers.
- Pod manager: Monitors training process health on each pod. The number of Pod Managers is determined by the number of pods required by the job. One Pod Manager currently controls several hundred pods.
- HyperPod elastic agent: Customers install the elastic agent into their training container. It orchestrates lifecycles of training workers on each container and communicates with the Amazon SageMaker HyperPod training operator. The HyperPod elastic agent is an extension of PyTorch’s ElasticAgent.
The job Controller uses fault detection components such as the SageMaker HyperPod health-monitoring agent and node health check mechanisms like AWS retirement notices to update job state and repair faults. It also relies on the HyperPod elastic agent to check the status of training processes for crashes and hung job detection.
When a HyperPodPyTorch job is submitted, the Amazon SageMaker HyperPod training operator spins up job pods along with pod manager pods that help manage the training job lifecycle. The pod managers interact with the HyperPod elastic agent so that all job pods maintain a healthy state.
Benefits of using the operator
The Amazon SageMaker HyperPod training operator can be installed as an EKS add-on on your cluster. The key benefits include:
- Centralized training process monitoring and restart – The HyperPod training operator maintains a control plane with a global view of health across all ranks. When one rank encounters an issue, it broadcasts a stop signal to all ranks to prevent other ranks from failing individually at different times due to collective communication timeout. This supports more efficient fault detection and recovery.
- Centralized efficient rank assignment – A separate HyperPod rendezvous backend allows the HyperPod training operator to assign ranks directly. This reduces initialization overhead by eliminating the need for worker-to-worker discovery.
- Unhealthy training node detection and job restart – The HyperPod training operator is fully integrated with the HyperPod EKS cluster resiliency features, helping restart jobs or training processes due to bad nodes and hardware issues in ML workloads. This reduces the need to self-manage job recovery solutions.
- Granular process recovery – Rather than restarting entire jobs when failures occur, the operator precisely targets and restarts only training processes, reducing recovery times from tens of minutes to seconds. This makes HyperPod training operator job recovery time scale linearly as cluster size grows.
- Hanging job detection and performance degradation detection – Based on training script log monitoring, the HyperPod training operator helps overcome problematic training scenarios including stalled training batches, non-numeric loss values, and performance degradation through simple YAML configurations. For more information see, Using the training operator to run jobs in the Amazon SageMaker AI Developer Guide.
Training operator setup
This section walks through installing the Amazon SageMaker HyperPod training operator as an Amazon EKS add-on.
Estimated Setup Time: 30-45 minutes
Prerequisites
Before getting started, verify that you have the following resources and permissions.
Required AWS resources:
- Active AWS account
- Amazon EKS cluster (version 1.28 or later)
- Amazon SageMaker HyperPod EKS cluster
- Amazon ECR repository for container images
Required IAM permissions:
AmazonSageMakerHyperPodTrainingOperatorAccessmanaged policy- EKS cluster access permissions
- ECR push/pull permissions
eks-pod-identity-agentadd-on installed on EKS cluster
Required software:
- kubectl (version 1.28 or later), for more information see the kubectl installation documentation
- docker (version 20.10 or later), for more information see the docker installation documentation
- AWS Command Line Interface (AWS CLI) (version 2.0 or later), for more information see the AWS CLI installation documentation
envsubstutility- HuggingFace account with access token
Installation instructions
Before running the installation steps below, you’ll need to first create a HyperPod cluster. If you haven’t done this one already please follow the instructions to create an EKS-orchestrated SageMaker HyperPod cluster to get started. Make sure to install eks-pod-identity-agent add-on on the EKS cluster, by following the Set up the Amazon EKS Pod Identity Agent instructions.
Install cert-manager
First, install the cert-manager add-on which is required for the HyperPod training operator:
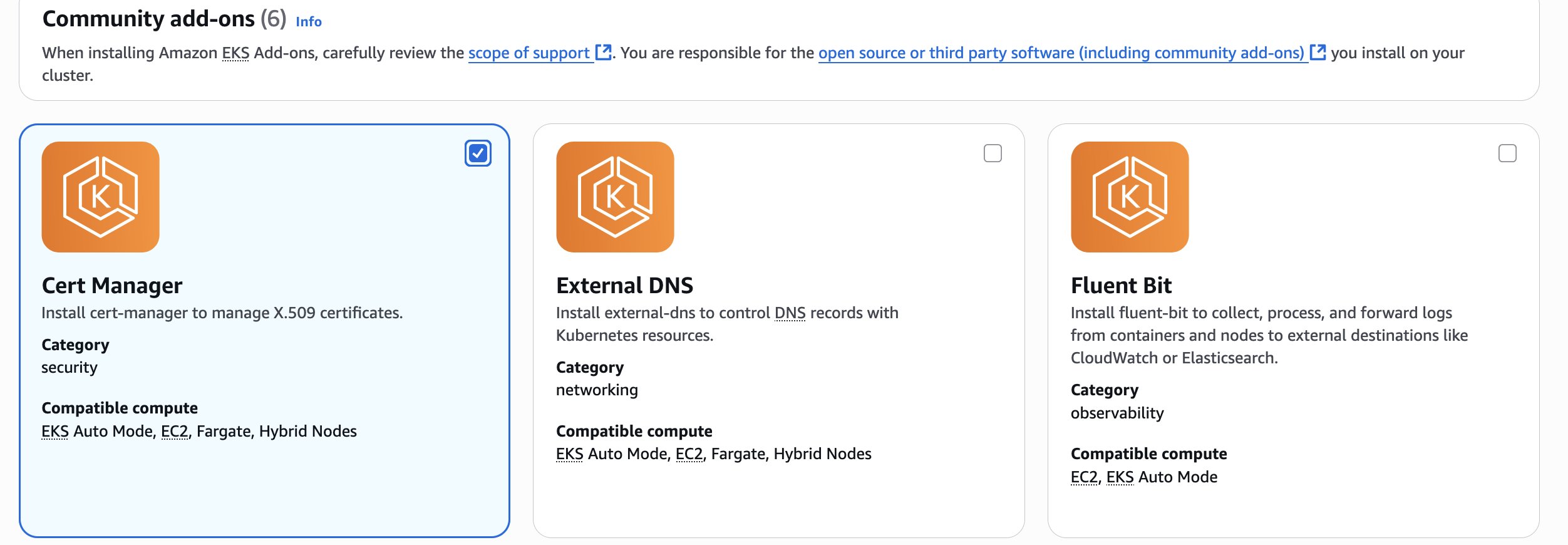
- Open the Amazon EKS console
- Navigate to your EKS cluster and go to the Add-ons page
- On the Add-ons page, locate Get more add-ons and navigate to the Community add-ons section
- Find the Cert Manager add-on, select it, and choose Next
- On the add-on configuration page, proceed with default settings and choose Next
- Preview all selections for the Cert Manager add-on and choose Create
- Wait for the add-on status to change to Active before proceeding
Install the HyperPod training operator add-on
Once cert-manager is active, install the Amazon SageMaker HyperPod training operator:
- Open the Amazon SageMaker console
- Navigate to your cluster’s details page
- On the Dashboard tab, locate Amazon SageMaker HyperPod training operator and choose Install
During installation, SageMaker creates an IAM execution role with permissions similar to the AmazonSageMakerHyperPodTrainingOperatorAccess managed policy and creates a pod identity association between your Amazon EKS cluster and the new execution role.

Verify installation
We have now successfully setup of the Amazon SageMaker HyperPod training operator. You can confirm that the pods are running by using the following command:
Your output should contain the training operator controller as shown below:
Set up training job
Let’s run a PyTorch-based training example on a Llama model. We begin by checking out the following code base:
These scripts provide an easy way to get started with multinode FSDP training on EKS. It is designed to be as simple as possible, requires no data preparation, and uses a container image.
Next, build the docker container image.
The above command works with linux based environments, if you are on a Mac, use buildx to target linux/amd64 architecture:
Push the image to Amazon ECR:
Note: Pushing the image may take some time depending on your network bandwidth.
Data
For this example, we’ll be using the allenai/c4 dataset. Instead of downloading the whole thing, the create_streaming_dataloaders function will stream the dataset from HuggingFace, so there’s no data prep required for running this training.
If you’d like to instead use your own dataset, you can do so by formatting it as a HuggingFace dataset, and passing its location to the --dataset_path argument.
For the dataset, you will need a Hugging Face access token. First, create a Hugging Face account. Then generate your access token with read permissions.
We will reference this token in the next step by setting it as an environment variable.
This example uses envsubst to generate a Kubernetes manifest file from a template file and parameters. If you don’t have envsubst on your development environment, install it by following the installation instructions.
Launch Llama 3.1 8B training job
Next, we generate the Kubernetes manifest and apply it to the cluster. Let’s navigate to the FSDP source repo:
Here, we start by creating environment variables that are used in our training job. Fill out the placeholders as per your cluster size.
Once you fill in env_vars and then source variables:
You can apply yaml to submit the training job:
You can also adjust the training parameters in the TRAINING_ARGS section of the llama3_1_8b-fsdp-hpto.yaml. Additional parameters can be found under model/arguments.py. Note that we use the same directory for both --checkpoint_dir and --resume_from_checkpoint. If there are multiple checkpoints, --resume_from_checkpoint will automatically select the most recent one. This way if our training is interrupted for any reason, it will automatically pick up the most recent checkpoint.
Additionally, you can also prepare and submit your jobs compatible with the Amazon SageMaker HyperPod training operator through the HyperPod CLI and SDK capabilities that have been recently announced, more reading information on how to use it is available in this development guide.
Monitor training job
To see the status of your job, use the following command:
Use the following command to list the jobs ran using HyperPod training operator:
Use the following command to list all the pods for the training jobs:
To check the pod logs run the below command to continuously stream the logs to stdout, use the following command:
Configure log monitoring
With Amazon SageMaker HyperPod training operators users can configure log patterns that the operator continuously monitors. The HyperPod operator continuously looks for the configured regex pattern and stops the training job if it finds a violation. The llama3_1_13b-fsdp-hpto.yaml file that we used previously contains log monitoring configurations for tracking Job start hangs, hang detection during training, and checkpoint creation failures as shown below:
And the corresponding code files in /src/train.py have the necessary log statements.
Any time these metrics exhibit deviation from their expected values, the operator will detect it as a fault, and trigger a recovery process to re-execute the job, up to a user-specified maximum number of retries.
Additionally, the HyperPod training operator also supports integration with Amazon SageMaker Task Governance.
Integration with HyperPod Observability
SageMaker HyperPod offers a managed observability experience through the newly launched the HyperPod Monitoring and Observability EKS add-on. The observability add-on automatically populates Kubeflow Training metrics in Grafana dashboards out of the box, but for HyperPod PyTorch job metrics, you would have to turn on the advanced training metrics which leverage the HyperPod training operator to show information around job downtime, job recovery and faults, and downtime.
To get these advanced metrics, you can refer to Setting up the SageMaker HyperPod observability add-on. This helps to streamline the process of manually setting up a scraper and building dashboards.
Clean up
To avoid incurring unnecessary charges, clean up the resources created in this walkthrough.
Delete training jobs
Remove all HyperPod training jobs:
Verify jobs are deleted:
Remove container images
Delete the ECR repository and images:
Remove add-ons:
Remove the following add-ons:
Remove the Amazon SageMaker HyperPod training operator add-on:
- Open the Amazon SageMaker console
- Navigate to your cluster’s details page
- On the Add-ons tab, select the Amazon SageMaker HyperPod training operator
- Choose Remove
Remove the cert manager add-on:
- Open the Amazon EKS console
- Navigate to your EKS cluster’s Add-ons page
- Select Cert Manager and choose Remove
Additional clean up
Consider removing these resources if no longer needed:
- Any persistent volumes created during training
- CloudWatch log groups (if you want to retain logs, leave these)
- Custom IAM roles created specifically for this example
- The HyperPod cluster itself (if no longer needed).
Conclusion
As organizations continue to push the boundaries of AI model development, tools like the Amazon SageMaker HyperPod training operator can be used to maintain efficiency and reliability at scale. Amazon SageMaker HyperPod training operator offers a robust solution to common challenges in large model training. Key takeaways include:
- One-click installation through AWS SageMaker HyperPod cluster console user-interface.
- Custom rendezvous backend eliminates initialization and worker synchronization overhead which results in faster job starts and recovery.
- Process level restarts maximize recovery efficiency when runtime faults occur.
- Customizable hang job detection during training.
- Comprehensive monitoring for early detection of training issues.
- Out-of-box integration with existing HyperPod resiliency features.
To get started with the Amazon SageMaker HyperPod training operator, follow the setup instructions provided in this post and explore the example training job to understand how it can benefit your specific use case. For more information and best practices, visit the Amazon SageMaker documentation.
About the authors
 Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker AI. He holds a Master’s degree from UIUC with a specialization in Data science. He specializes in Generative AI workloads, helping customers build and deploy LLM’s using SageMaker HyperPod, SageMaker training jobs, and SageMaker distributed training. Outside of work, he enjoys running, hiking, and cooking.
Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker AI. He holds a Master’s degree from UIUC with a specialization in Data science. He specializes in Generative AI workloads, helping customers build and deploy LLM’s using SageMaker HyperPod, SageMaker training jobs, and SageMaker distributed training. Outside of work, he enjoys running, hiking, and cooking.
 Haard Mehta is a Software Engineer with Amazon’s SageMaker AI team and holds a Master’s degree in Computer Science with a specialization in big data systems from Arizona State University. He has extensive experience building managed machine learning services at scale, with a focus on hardware resiliency and enabling customers to succeed in their AI use cases without complex infrastructure management. Haard enjoys exploring new places, photography, cooking, and road trips.
Haard Mehta is a Software Engineer with Amazon’s SageMaker AI team and holds a Master’s degree in Computer Science with a specialization in big data systems from Arizona State University. He has extensive experience building managed machine learning services at scale, with a focus on hardware resiliency and enabling customers to succeed in their AI use cases without complex infrastructure management. Haard enjoys exploring new places, photography, cooking, and road trips.
 Anirudh Viswanathan is a Sr Product Manager, Technical – External Services with the SageMaker AI Training team. He holds a Masters in Robotics from Carnegie Mellon University, an MBA from the Wharton School of Business, and is named inventor on over 40 patents. He enjoys long-distance running, visiting art galleries, and Broadway shows.
Anirudh Viswanathan is a Sr Product Manager, Technical – External Services with the SageMaker AI Training team. He holds a Masters in Robotics from Carnegie Mellon University, an MBA from the Wharton School of Business, and is named inventor on over 40 patents. He enjoys long-distance running, visiting art galleries, and Broadway shows.