AI agents are evolving beyond basic single-task helpers into more powerful systems that can plan, critique, and collaborate with other agents to solve complex problems. Deep Agents—a recently introduced framework built on LangGraph—bring these capabilities to life, enabling multi-agent workflows that mirror real-world team dynamics. The challenge, however, is not just building such agents but also running them reliably and securely in production. This is where Amazon Bedrock AgentCore Runtime comes in. By providing a secure, serverless environment purpose-built for AI agents and tools, Runtime makes it possible to deploy Deep Agents at enterprise scale without the heavy lifting of managing infrastructure.
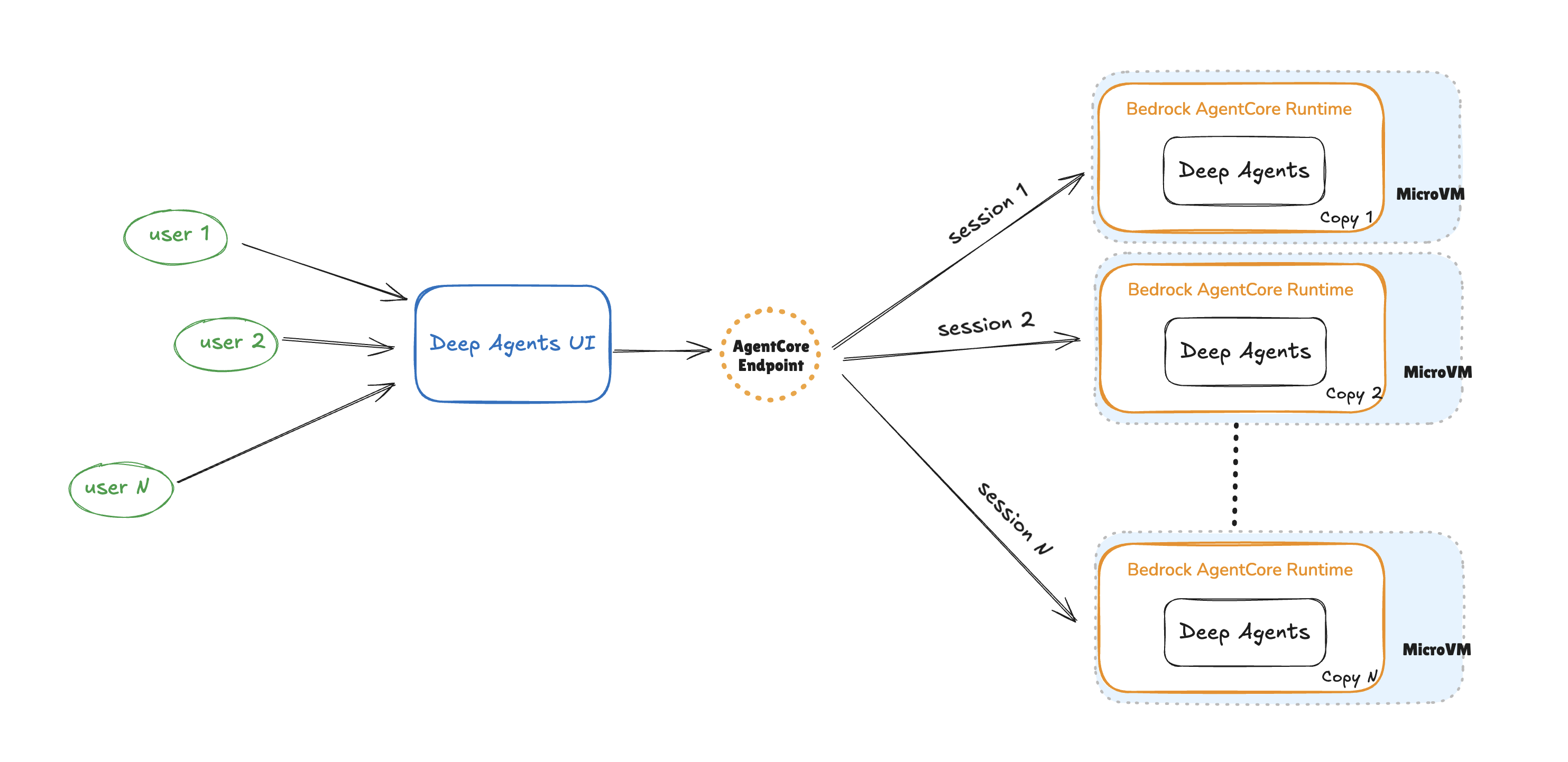
In this post, we demonstrate how to deploy Deep Agents on AgentCore Runtime. As shown in the following figure, AgentCore Runtime scales any agent and provides session isolation by allocating a new microVM for each new session.
What is Amazon Bedrock AgentCore?
Amazon Bedrock AgentCore is both framework-agnostic and model-agnostic, giving you the flexibility to deploy and operate advanced AI agents securely and at scale. Whether you’re building with Strands Agents, CrewAI, LangGraph, LlamaIndex, or another framework—and running them on a large language model (LLM)—AgentCore provides the infrastructure to support them. Its modular services are purpose-built for dynamic agent workloads, with tools to extend agent capabilities and controls required for production use. By alleviating the undifferentiated heavy lifting of building and managing specialized agent infrastructure, AgentCore lets you bring your preferred framework and model and deploy without rewriting code.
Amazon Bedrock AgentCore offers a comprehensive suite of capabilities designed to transform local agent prototypes into production-ready systems. These include persistent memory for maintaining context in and across conversations, access to existing APIs using Model Context Protocol (MCP), seamless integration with corporate authentication systems, specialized tools for web browsing and code execution, and deep observability into agent reasoning processes. In this post, we focus specifically on the AgentCore Runtime component.
Core capabilities of AgentCore Runtime
AgentCore Runtime provides a serverless, secure hosting environment specifically designed for agentic workloads. It packages code into a lightweight container with a simple, consistent interface, making it equally well-suited for running agents, tools, MCP servers, or other workloads that benefit from seamless scaling and integrated identity management.AgentCore Runtime offers extended execution times up to 8 hours for complex reasoning tasks, handles large payloads for multimodal content, and implements consumption-based pricing that charges only during active processing—not while waiting for LLM or tool responses. Each user session runs in complete isolation within dedicated micro virtual machines (microVMs), maintaining security and helping to prevent cross-session contamination between agent interactions. The runtime works with many frameworks (for example: LangGraph, CrewAI, Strands, and so on) and many foundation model providers, while providing built-in corporate authentication, specialized agent observability, and unified access to the broader AgentCore environment through a single SDK.
Real-world example: Deep Agents integration
In this post we’re going to deploy the recently released Deep Agents implementation example on AgentCore Runtime—showing just how little effort it takes to get the latest agent innovations up and running.
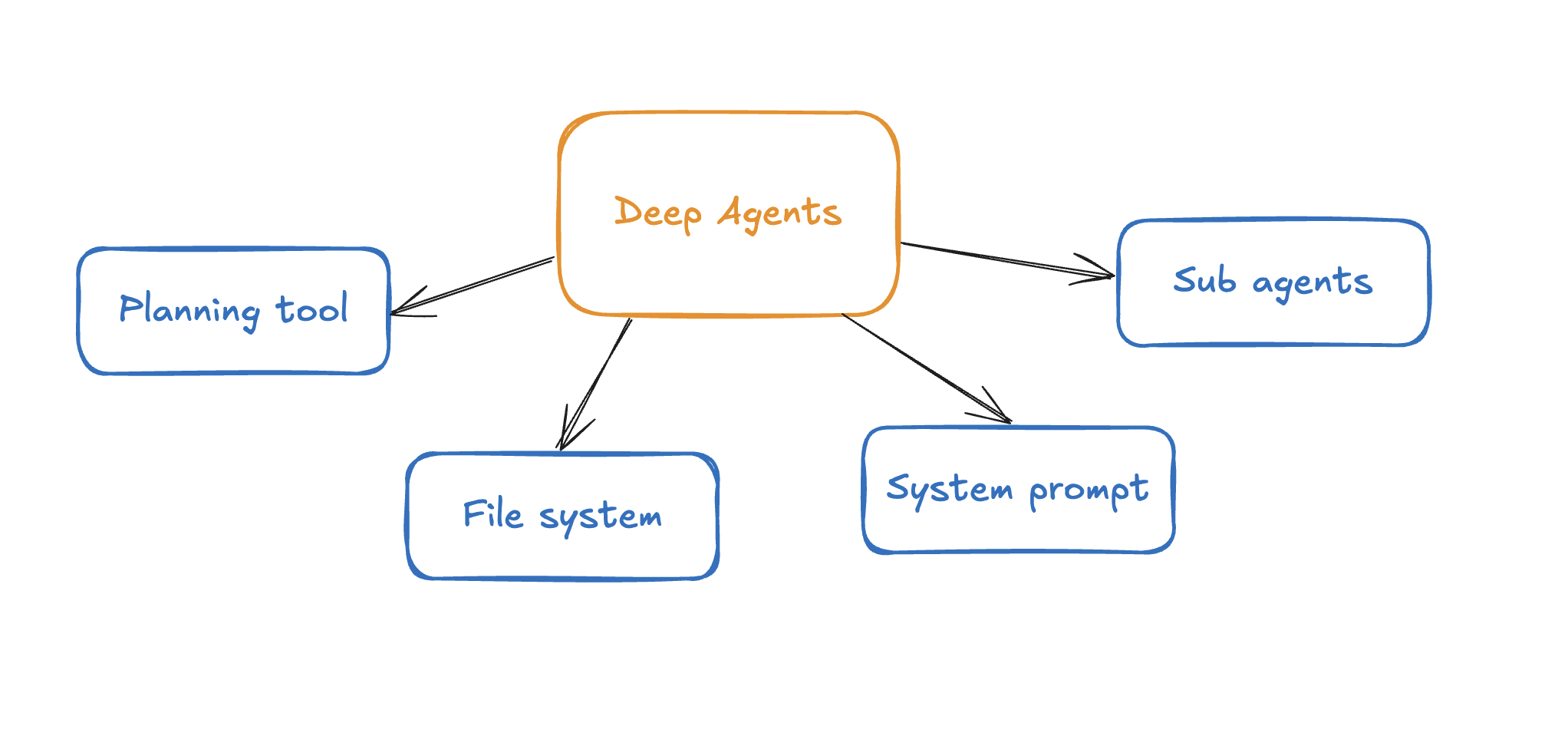
The sample implementation in the preceding diagram includes:
- A research agent that conducts deep internet searches using the Tavily API
- A critique agent that reviews and provides feedback on generated reports
- A main orchestrator that manages the workflow and handles file operations
Deep Agents uses LangGraph’s state management to create a multi-agent system with:
- Built-in task planning through a
write_todostool that helps agents break down complex requests - Virtual file system where agents can read/write files to maintain context across interactions
- Sub-agent architecture allowing specialized agents to be invoked for specific tasks while maintaining context isolation
- Recursive reasoning with high recursion limits (more than 1,000) to handle complex, multi-step workflows
This architecture enables Deep Agents to handle research tasks that require multiple rounds of information gathering, synthesis, and refinement.The key integration points in our code showcase how agents work with AgentCore. The beauty is in its simplicity—we only need to add a couple of lines of code to make an agent AgentCore-compatible:
That’s it! The rest of the code—model initialization, API integrations, and agent logic—remains exactly as it was. AgentCore handles the infrastructure while your agent handles the intelligence. This integration pattern works for most Python agent frameworks, making AgentCore truly framework-agnostic.
Deploying to AgentCore Runtime: Step-by-step
Let’s walk through the actual deployment process using the AgentCore Starter ToolKit, which dramatically simplifies the deployment workflow.
Prerequisites
Before you begin, make sure you have:
- Python 3.10 or higher
- AWS credentials configured
- Amazon Bedrock AgentCore SDK installed
Step 1: IAM permissions
There are two different AWS Identity and Access Management (IAM) permissions you need to consider when deploying an agent in an AgentCore Runtime—the role you, as a developer use to create AgentCore resources and the execution role that an agent needs to run in an AgentCore Runtime. While the latter role can now be auto-created by the AgentCore Starter Toolkit (auto_create_execution_role=True), the former must be defined as described in IAM Permissions for AgentCore Runtime.
Step 2: Add a wrapper to your agent
As shown in the preceding Deep Agents example, add the AgentCore imports and decorator to your existing agent code.
Step 3: Deploy using the AgentCore starter toolkit
The starter toolkit provides a three-step deployment process:
Step 4: What happens behind the scenes
When you run the deployment, the starter kit automatically:
- Generates an optimized Docker file with Python 3.13-slim base image and OpenTelemetry instrumentation
- Builds your container with the dependencies from
requirements.txt - Creates an Amazon Elastic Container Registry (Amazon ECR) repository (
if auto_create_ecr=True) and pushes your image - Deploys to AgentCore Runtime and monitors the deployment status
- Configures networking and observability with Amazon CloudWatch and AWS X-Ray integration
The entire process typically takes 2–3 minutes, after which your agent is ready to handle requests at scale. Each new session is launched in its own fresh AgentCore Runtime microVM, maintaining complete environment isolation.
The starter kit generates a configuration file (.bedrock_agentcore.yaml) that captures your deployment settings, making it straightforward to redeploy or update your agent later.
Invoking your deployed agent
After deployment, you have two options for invoking your agent:
Option 1: Using the start kit (shown in Step 3)
Option 2: Using boto3 SDK directly
Deep Agents in action
As the code executes in Bedrock AgentCore Runtime, the primary agent orchestrates specialized sub-agents—each with its own purpose, prompt, and tool access—to solve complex tasks more effectively. In this case, the orchestrator prompt (research_instructions) sets the plan:
- Write the question to question.txt
- Fan out to one or more research-agent calls (each on a single sub-topic) using the internet_search tool
- Synthesize findings into final_report.md
- Call critique-agent to evaluate gaps and structure
- Optionally loop back to more research/edits until quality is met
Here it is in action:
Clean up
When finished, don’t forget to de-allocate provisioned AgentCore Runtime in addition to the container repository that was created during the process:
Conclusion
Amazon Bedrock AgentCore represents a paradigm shift in how we deploy AI agents. By abstracting away infrastructure complexity while maintaining framework and model flexibility, AgentCore enables developers to focus on building sophisticated agent logic rather than managing deployment pipelines. Our Deep Agents deployment demonstrates that even complex, multi-agent systems with external API integrations can be deployed with minimal code changes. The combination of enterprise-grade security, built-in observability, and serverless scaling makes AgentCore the best choice for production AI agent deployments. Specifically for deep research agents, AgentCore offers the following unique capabilities that you can explore:
- AgentCore Runtime can handle asynchronous processing and long running (up to 8 hours) agents. Asynchronous tasks allow your agent to continue processing after responding to the client and handle long-running operations without blocking responses. Your background research sub-agent could be asynchronously researching for hours.
- AgentCore Runtime works with AgentCore Memory, enabling capabilities such as building upon previous findings, remembering research preferences, and maintaining complex investigation context without losing progress between sessions.
- You can use AgentCore Gateway to extend your deep research to include proprietary insights from enterprise services and data sources. By exposing these differentiated resources as MCP tools, your agents can quickly take advantage and combine that with publicly available knowledge.
Ready to deploy your agents to production? Here’s how to get started:
- Install the AgentCore starter kit:
pip install bedrock-agentcore-starter-toolkit - Experiment: Deploy your code by following this step by step guide.
The era of production-ready AI agents is here. With AgentCore, the journey from prototype to production has never been shorter.
About the authors
 Vadim Omeltchenko is a Sr. AI/ML Solutions Architect who is passionate about helping AWS customers innovate in the cloud. His prior IT experience was predominantly on the ground.
Vadim Omeltchenko is a Sr. AI/ML Solutions Architect who is passionate about helping AWS customers innovate in the cloud. His prior IT experience was predominantly on the ground.
 Eashan Kaushik is a Specialist Solutions Architect AI/ML at Amazon Web Services. He is driven by creating cutting-edge generative AI solutions while prioritizing a customer-centric approach to his work. Before this role, he obtained an MS in Computer Science from NYU Tandon School of Engineering. Outside of work, he enjoys sports, lifting, and running marathons.
Eashan Kaushik is a Specialist Solutions Architect AI/ML at Amazon Web Services. He is driven by creating cutting-edge generative AI solutions while prioritizing a customer-centric approach to his work. Before this role, he obtained an MS in Computer Science from NYU Tandon School of Engineering. Outside of work, he enjoys sports, lifting, and running marathons.
 Shreyas Subramanian is a Principal data scientist and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal data scientist and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build generative AI solutions. His focus since early 2023 has been leading solution architecture efforts for the launch of Amazon Bedrock, the flagship generative AI offering from AWS for builders. Mark’s work covers a wide range of use cases, with a primary interest in generative AI, agents, and scaling ML across the enterprise. He has helped companies in insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services. Mark holds six AWS Certifications, including the ML Specialty Certification.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build generative AI solutions. His focus since early 2023 has been leading solution architecture efforts for the launch of Amazon Bedrock, the flagship generative AI offering from AWS for builders. Mark’s work covers a wide range of use cases, with a primary interest in generative AI, agents, and scaling ML across the enterprise. He has helped companies in insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services. Mark holds six AWS Certifications, including the ML Specialty Certification.