Finance analysts across Amazon Finance face mounting complexity in financial planning and analysis processes. When working with vast datasets spanning multiple systems, data lakes, and business units, analysts encounter several critical challenges. First, they spend significant time manually browsing data catalogs and reconciling data from disparate sources, leaving less time for valuable analysis and insight generation. Second, historical data and previous business decisions often reside in various documents and legacy systems, making it difficult to use past learnings during planning cycles. Third, as business contexts rapidly evolve, analysts need quick access to relevant metrics, planning assumptions, and financial insights to support data-driven decision-making.
Traditional tools and processes fall short in addressing these challenges. Keyword-based searches often miss contextual relationships in financial data, and rigid query structures limit analysts’ ability to explore data dynamically. Furthermore, the lack of institutional knowledge preservation means valuable insights and decision rationales often remain siloed or get lost over time, leading to redundant analysis and inconsistent planning assumptions across teams. These challenges significantly impact financial planning efficiency, decision-making agility, and the overall quality of business insights. Analysts needed a more intuitive way to access, understand, and use their organization’s collective financial knowledge and data assets.
The Amazon Finance technical team develops and manages comprehensive technology solutions that power financial decision-making and operational efficiency while standardizing across Amazon’s global operations. In this post, we explain how the team conceptualized and implemented a solution to these business challenges by harnessing the power of generative AI using Amazon Bedrock and intelligent search with Amazon Kendra.
Solution overview
To address these business challenges, Amazon Finance developed an AI-powered assistant solution that uses generative AI and enterprise search capabilities. This solution helps analysts interact with financial data sources and documentation through natural language queries, minimizing the need for complex manual searches across multiple systems. The assistant accesses a comprehensive knowledge base of financial documents, historical data, and business context, providing relevant and accurate responses while maintaining enterprise security standards. This approach not only streamlines data discovery but also preserves institutional knowledge and enables more consistent decision-making across the organization.
The AI assistant’s methodology consists of two key solution components: intelligent retrieval and augmented generation. The retrieval system uses vector stores, which are specialized databases that efficiently store and search high-dimensional representations of text meanings. Unlike traditional databases that rely on keyword matching, vector stores enable semantic search by converting user queries into vector representations and finding similar vectors in the database. Building on this retrieval foundation, the system employs augmented generation to create accurate and contextual responses. This approach enhances traditional language models by incorporating external knowledge sources during response generation, significantly reducing hallucinations and improving factual accuracy. The process follows three steps: retrieving relevant information from knowledge sources using semantic search, conditioning the language model with this context, and generating refined responses that incorporate the retrieved information. By combining these technologies, the assistant delivers responses that are both contextually appropriate and grounded in verified organizational knowledge, making it particularly effective for knowledge-intensive applications like financial operations and planning.
We implemented this Retrieval Augmented Generation (RAG) system through a combination of large language models (LLMs) on Amazon Bedrock and intelligent search using Amazon Kendra.
In the following sections, we discuss the key architectural components that we used in the solution and describe how the overall solution works.
Amazon Bedrock
We chose Anthropic’s Claude 3 Sonnet, a powerful language model, for its exceptional language generation capabilities and ability to understand and reason complex topics. By integrating Anthropic’s Claude into the RAG module through Amazon Bedrock, the AI assistant can generate contextual and informative responses that seamlessly combine the retrieved knowledge from the vector store with the model’s natural language processing and generation abilities, resulting in a more human-like and engaging conversational experience.
Amazon Kendra (Enterprise Edition Index)
Amazon Kendra offers powerful natural language processing for AI assistant applications. It excels at understanding user questions and finding relevant answers through semantic search. The service works smoothly with generative AI models, particularly in RAG solutions. The enterprise security features in Amazon Kendra support data protection and compliance. Its ability to understand user intent and connect directly with Amazon Bedrock makes it ideal for business assistants. This helps create meaningful conversations using business documents and data catalogs.
We chose Amazon Kendra Enterprise Edition Index over Amazon OpenSearch Service, primarily due to its sophisticated built-in capabilities and reduced need for manual configuration. Whereas OpenSearch Service requires extensive customization and technical expertise, Amazon Kendra provides out-of-the-box natural language understanding, automatic document processing for over 40 file formats, pre-built enterprise connectors, and intelligent query handling including synonym recognition and refinement suggestions. The service combines keyword, semantic, and vector search approaches automatically, whereas OpenSearch Service requires manual implementation of these features. These features of Amazon Kendra were suitable for our finance domain use case, where accuracy is imperative for usability.
We also chose Amazon Kendra Enterprise Edition Index over Amazon Q Business for information retrieval, because it stands out as a more robust and flexible solution. Although both tools aim to streamline access to company information, Amazon Kendra offers superior retrieval accuracy and greater control over search parameters. With Amazon Kendra, you can fine-tune relevance tuning, customize document attributes, and implement custom synonyms to enhance search precision. This level of customization helped us tailor the search experience to our specific needs in the Amazon Finance domain and monitor the search results prior to the augmented generation step within user conversations.
Streamlit
We selected Streamlit, a Python-based framework for creating interactive web applications, for building the AI assistant’s UI due to its rapid development capabilities, seamless integration with Python and the assistant’s backend components, interactive and responsive UI components, potential for data visualization, and straightforward deployment options. With the Streamlit UI, the assistant provides a user-friendly and engaging interface that facilitates natural language interactions while allowing for efficient iteration and deployment of the application.
Prompt template
Prompt templates allow for formatting user queries, integrating retrieved knowledge, and providing instructions or constraints for response generation, which are essential for generating contextual and informative responses that combine the language generation abilities of Anthropic’s Claude with the relevant knowledge retrieved from the search powered by Amazon Kendra. The following is an example prompt:
Solution architecture
The following solution architecture diagram depicts how the key architectural components work with each other to power the solution.
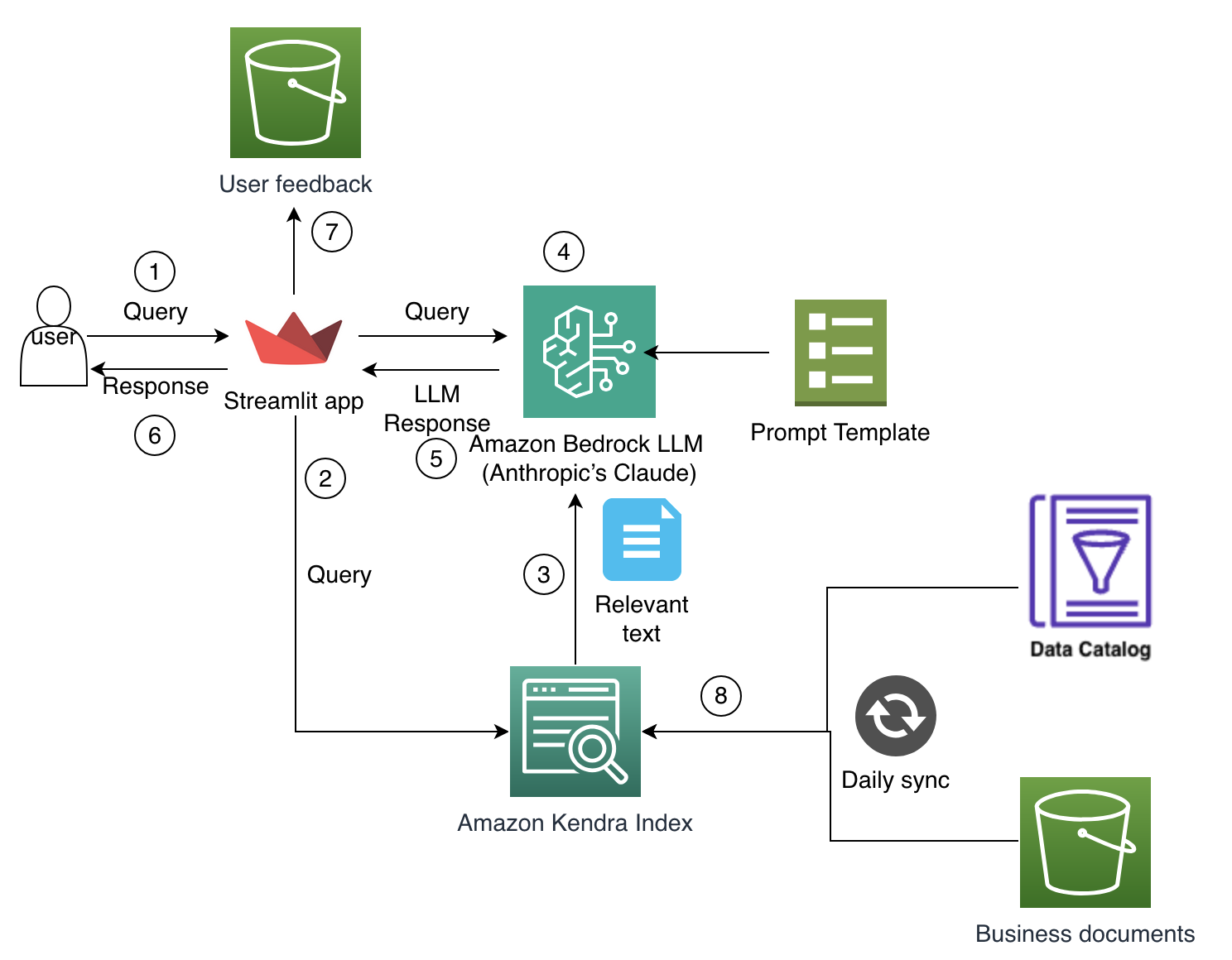
The workflow consists of the following steps:
- The user asks the question in a chat box after authentication.
- The Streamlit application sends the query to an Amazon Kendra retriever for relevant document retrieval.
- Amazon Kendra sends the relevant paragraph and document references to the RAG solution.
- The RAG solution uses Anthropic’s Claude in Amazon Bedrock along with the prompt template and relevant paragraph as context.
- The LLM response is sent back to the Streamlit UI.
- The response is shown to the user along with the feedback feature and session history.
- The user feedback on responses is stored separately in Amazon Simple Storage Service (Amazon S3)
- Amazon Kendra indexes relevant documents stored in S3 buckets for document search and retrieval.
Frontend architecture
We designed the following frontend architecture to allow for rapid modifications and deployment, keeping in mind the scalability and security of the solution.
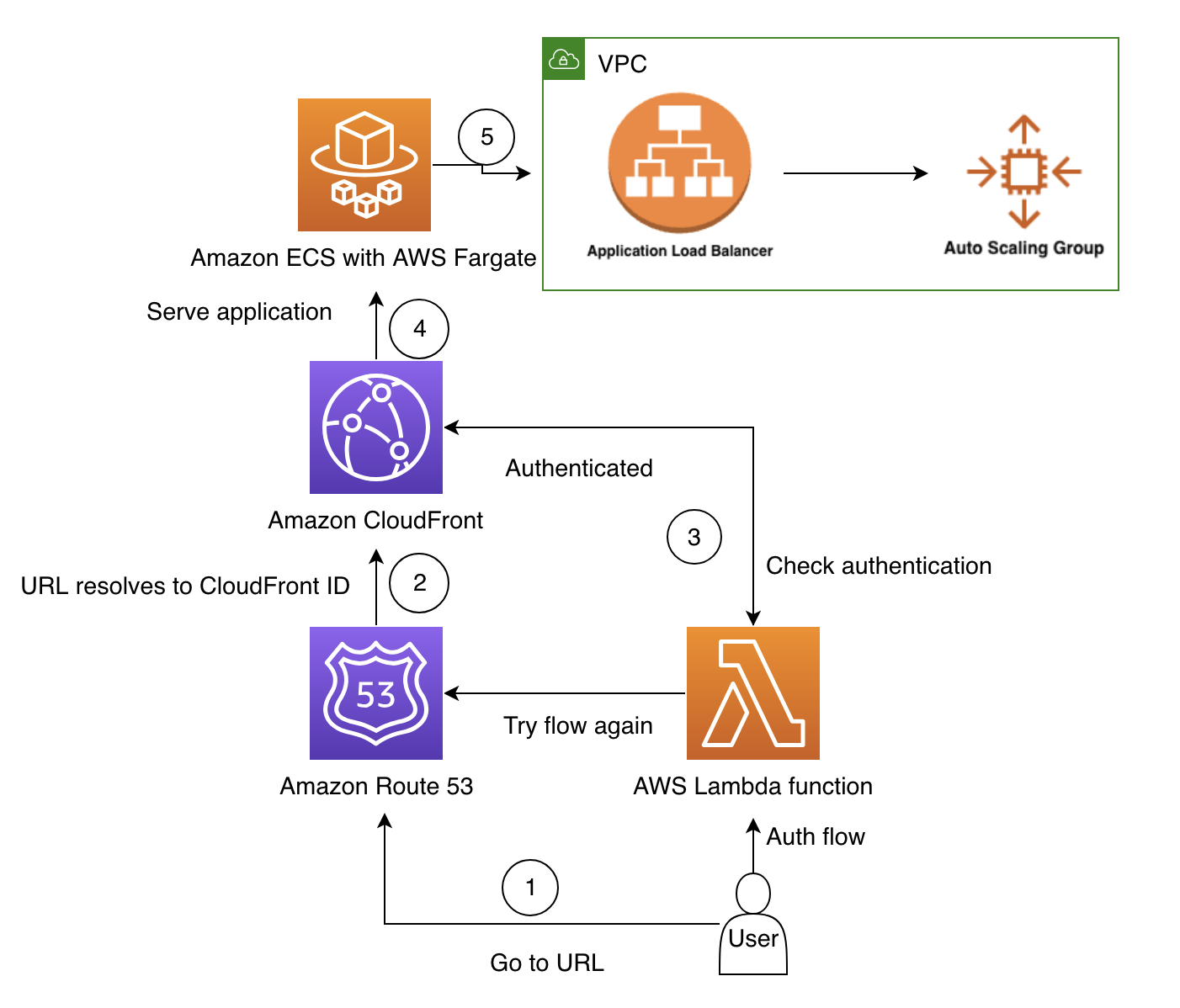
This workflow consists of the following steps:
- The user navigates to the application URL in their browser.
- Amazon Route 53 resolves their request to the Amazon CloudFront distribution, which then selects the server closest to the user (to minimize latency).
- CloudFront runs an AWS Lambda function that makes sure the user has been authenticated. If not, the user is redirected to sign in. After they successfully sign in, they are redirected back to the application website. The flow repeats, and CloudFront triggers the Lambda function again. This time, the user is now able to access the website.
- Now authenticated, CloudFront returns the assets of the web application.
- AWS Fargate makes it possible to run containers without having to manage the underlying Amazon Elastic Compute Cloud (Amazon EC2) instances. This allows running containers as a true serverless service. Amazon Elastic Container Service (Amazon ECS) is configured with automatic scaling (target tracking automatic scaling, which scales based on the Application Load Balancer (ALB) requests per target).
Evaluation of the solution’s performance
We implemented a comprehensive evaluation framework to rigorously assess the AI assistant’s performance and make sure it meets the high standards required for financial applications. Our framework was designed to capture both quantitative metrics for measurable performance and qualitative indicators for user experience and response quality. During our benchmarking tests with analysts, we found that this solution dramatically reduced search time by 30% because analysts can now perform natural language search, and it improved the accuracy of search results by 80%.
Quantitative assessment
We focused primarily on precision and recall testing, creating a diverse test set of over 50 business queries that represented typical use cases our analysts encounter. Using human-labeled answers as our ground truth, we evaluated the system’s performance across two main categories: data discovery and knowledge search. In data discovery scenarios, where the system helps analysts locate specific data sources and metrics, we achieved an initial precision rate of 65% and a recall rate of 60% without performing metadata enrichment on the data sources. Although these rates might appear moderate, they represent a significant improvement over the previous manual search process, which had an estimated success rate of only 35% and often required multiple iterations across different systems. The primary reasons for the current rates of the new system were attributed to the lack of rich metadata about data sources and was a good indicator for teams to facilitate better metadata collection of data assets, which is currently underway.
The knowledge search capability demonstrated initial rates of 83% precision and 74% recall without performing metadata enrichment on data sources. This marked a substantial improvement over traditional keyword-based search methods, which typically achieved only 45–50% precision in our internal testing. This improvement is particularly meaningful because it translates to analysts finding the right information in their first search attempt roughly 8 out of 10 times, compared to the previous average of 3–4 attempts needed to locate the same information.
Qualitative metrics
The qualitative evaluation centered around the concept of faithfulness—a critical metric for financial applications where accuracy and reliability are paramount. We employed an innovative LLM-as-a-judge methodology to evaluate how well the AI assistant’s responses aligned with source documentation and avoided hallucinations or unsupported assertions. The results showed a marked difference between use cases: data discovery achieved a faithfulness score of 70%, and business knowledge search demonstrated an impressive 88% faithfulness. These scores significantly outperform our previous documentation search system, which had no built-in verification mechanism and often led to analysts working with outdated or incorrect information.
Most importantly, the new system reduced the average time to find relevant information from 45–60 minutes to just 5–10 minutes—an 85% improvement in efficiency. User satisfaction surveys indicate that 92% of analysts prefer the new system over traditional search methods, citing improved accuracy and time savings as key benefits.
These evaluation results have not only validated our approach but also highlighted specific areas for future enhancement. We continue to refine our evaluation framework as the system evolves, making sure it maintains high standards of accuracy and reliability while meeting the dynamic needs of our financial analysts. The evaluation framework was instrumental in building confidence within our business user community, providing transparent metrics that demonstrate the system’s capability to handle complex financial queries while maintaining the accuracy standards essential for financial operations.
Use cases
Our solution transforms how finance users interact with complex financial and operational data through natural language queries. In this section, we discuss some key examples demonstrating how the system simplifies data discovery.
Seamless data discovery
The solution enables users to find data sources through natural language queries rather than requiring technical knowledge of database structures. It uses a sophisticated combination of vector stores and enterprise search capabilities to match user questions with relevant data sources, though careful attention must be paid to context management and preventing over-reliance on previous interactions. Prior to the AI assistant solution, finance analysts needed deep technical knowledge to navigate complex database structures, often spending hours searching through multiple documentation sources just to locate specific data tables. Understanding system workflows required extensive review of technical documentation or reaching out to subject matter experts, creating bottlenecks and reducing productivity. Even experienced users struggled to piece together complete information about business processes from fragmented sources across different systems. Now, analysts can simply ask questions in natural language, such as “Where can I find productivity metrics?”, “How do I access facility information?”, or “Which dashboard shows operational data?” and receive precise, contextual answers. The solution combines enterprise search capabilities with LLMs to understand user intent and deliver relevant information from both structured and unstructured data sources. Analysts now receive accurate directions to specific consolidated reporting tables, clear explanations of business processes, and relevant technical details when needed. In our benchmark tests, for data discovery tasks alone, the system achieved 70% faithfulness and 65% precision, and document search demonstrated even stronger results with 83% precision and 88% faithfulness, without metadata enrichments.
Assisting understanding of internal business processes from knowledge documentation
Financial analysts previously faced a steep learning curve when working with enterprise planning tools. The complexity of these systems meant that even basic tasks required extensive documentation review or waiting for support from overwhelmed subject matter experts. New team members could take weeks or months to become proficient, while even experienced users struggled to keep up with system updates and changes. This created a persistent bottleneck in financial operations and planning processes. The introduction of the AI-powered assistant has fundamentally changed how analysts learn and interact with these planning tools. Rather than searching through hundreds of pages of technical documentation, analysts can now ask straightforward questions like “How do I forecast depreciation for new assets?”, “How does the quarterly planning process work?” or “What inputs are needed for the quarterly planning cycle?” The system provides clear, contextualized explanations drawn from verified documentation and system specifications. Our benchmark tests revealed that it achieved 83% precision and 88% faithfulness in retrieving and explaining technical and business information. New analysts can become productive in a matter of weeks, experienced users can quickly verify procedures, and subject matter experts can focus on more complex challenges rather than routine questions. This represents a significant advancement in making enterprise systems more accessible and efficient, while maintaining the accuracy and reliability required for financial operations.While the technology continues to evolve, particularly in handling nuanced queries and maintaining comprehensive coverage of system updates, it has already transformed the way teams interact with planning tools independently.
Conclusion
The AI-powered assistant solution discussed in this post has demonstrated significant improvements in data discovery and business insights generation, delivering multiple key benefits across Amazon Finance. Analysts can now quickly find relevant information through natural language queries, dramatically reducing search time. The system’s ability to synthesize insights from disparate data sources has notably enhanced data-driven decision-making, and its conversational interface and contextual responses promote self-service data exploration, effectively reducing the burden on centralized data teams.
This innovative AI assistant solution showcases the practical power of AWS generative AI in transforming enterprise data discovery and document search. By combining Amazon Kendra Enterprise Edition Index, Amazon Bedrock, and advanced LLMs, the implementation achieves impressive precision rates, proving that sophisticated AI-powered search is both achievable and effective. This success demonstrates how AWS generative AI services can meet current business needs while promoting future innovations in enterprise search. These services provide a strong foundation for organizations looking to enhance data discovery processes using natural language to support intelligent enterprise applications. To learn more about implementing AI-powered search solutions, see Build and scale the next wave of AI innovation on AWS and explore AWS AI use cases.
About the authors
 Saikat Gomes is part of the Customer Solutions team in Amazon Web Services. He is passionate about helping enterprises succeed and realize benefits from cloud adoption. He is a strategic advisor to his customers for large-scale cloud transformations involving people, process, and technology. Prior to joining AWS, he held multiple consulting leadership positions and led large- scale transformation programs in the retail industry for over 20 years. He is based out of Los Angeles, California.
Saikat Gomes is part of the Customer Solutions team in Amazon Web Services. He is passionate about helping enterprises succeed and realize benefits from cloud adoption. He is a strategic advisor to his customers for large-scale cloud transformations involving people, process, and technology. Prior to joining AWS, he held multiple consulting leadership positions and led large- scale transformation programs in the retail industry for over 20 years. He is based out of Los Angeles, California.
 Amit Dhanda serves as a Senior Scientist at Amazon’s Worldwide Operations Finance team, where he uses AI/ML technologies to solve complex ecommerce challenges. Prior to Amazon, he was Director of Data Science at Adore Me (now part of Victoria’s Secret), where he enhanced digital retail experiences through recommender systems. He held science leadership roles at EXL and Thomson Reuters, where he developed ML models for customer engagement/growth and text classification.
Amit Dhanda serves as a Senior Scientist at Amazon’s Worldwide Operations Finance team, where he uses AI/ML technologies to solve complex ecommerce challenges. Prior to Amazon, he was Director of Data Science at Adore Me (now part of Victoria’s Secret), where he enhanced digital retail experiences through recommender systems. He held science leadership roles at EXL and Thomson Reuters, where he developed ML models for customer engagement/growth and text classification.