Organizations are increasingly excited about the potential of AI agents, but many find themselves stuck in what we call “proof of concept purgatory”—where promising agent prototypes struggle to make the leap to production deployment. In our conversations with customers, we’ve heard consistent challenges that block the path from experimentation to enterprise-grade deployment:
“Our developers want to use different frameworks and models for different use cases—forcing standardization slows innovation.”
“The stochastic nature of agents makes security more complex than traditional applications—we need stronger isolation between user sessions.”
“We struggle with identity and access control for agents that need to act on behalf of users or access sensitive systems.”
“Our agents need to handle various input types—text, images, documents—often with large payloads that exceed typical serverless compute limits.”
“We can’t predict the compute resources each agent will need, and costs can spiral when overprovisioning for peak demand.”
“Managing infrastructure for agents that may be a mix of short and long-running requires specialized expertise that diverts our focus from building actual agent functionality.”
Amazon Bedrock AgentCore Runtime addresses these challenges with a secure, serverless hosting environment specifically designed for AI agents and tools. Whereas traditional application hosting systems weren’t built for the unique characteristics of agent workloads—variable execution times, stateful interactions, and complex security requirements—AgentCore Runtime was purpose-built for these needs.
The service alleviates the infrastructure complexity that has kept promising agent prototypes from reaching production. It handles the undifferentiated heavy lifting of container orchestration, session management, scalability, and security isolation, helping developers focus on creating intelligent experiences rather than managing infrastructure. In this post, we discuss how to accomplish the following:
- Use different agent frameworks and different models
- Deploy, scale, and stream agent responses in four lines of code
- Secure agent execution with session isolation and embedded identity
- Use state persistence for stateful agents along with Amazon Bedrock AgentCore Memory
- Process different modalities with large payloads
- Operate asynchronous multi-hour agents
- Pay only for used resources
Use different agent frameworks and models
One advantage of AgentCore Runtime is its framework-agnostic and model-agnostic approach to agent deployment. Whether your team has invested in LangGraph for complex reasoning workflows, adopted CrewAI for multi-agent collaboration, or built custom agents using Strands, AgentCore Runtime can use your existing code base without requiring architectural changes or any framework migrations. Refer to these samples on Github for examples.
With AgentCore Runtime, you can integrate different large language models (LLMs) from your preferred provider, such as Amazon Bedrock managed models, Anthropic’s Claude, OpenAI’s API, or Google’s Gemini. This makes sure your agent implementations remain portable and adaptable as the LLM landscape continues to evolve while helping you pick the right model for your use case to optimize for performance, cost, or other business requirements. This gives you and your team the flexibility to choose your favorite or most useful framework or model using a unified deployment pattern.
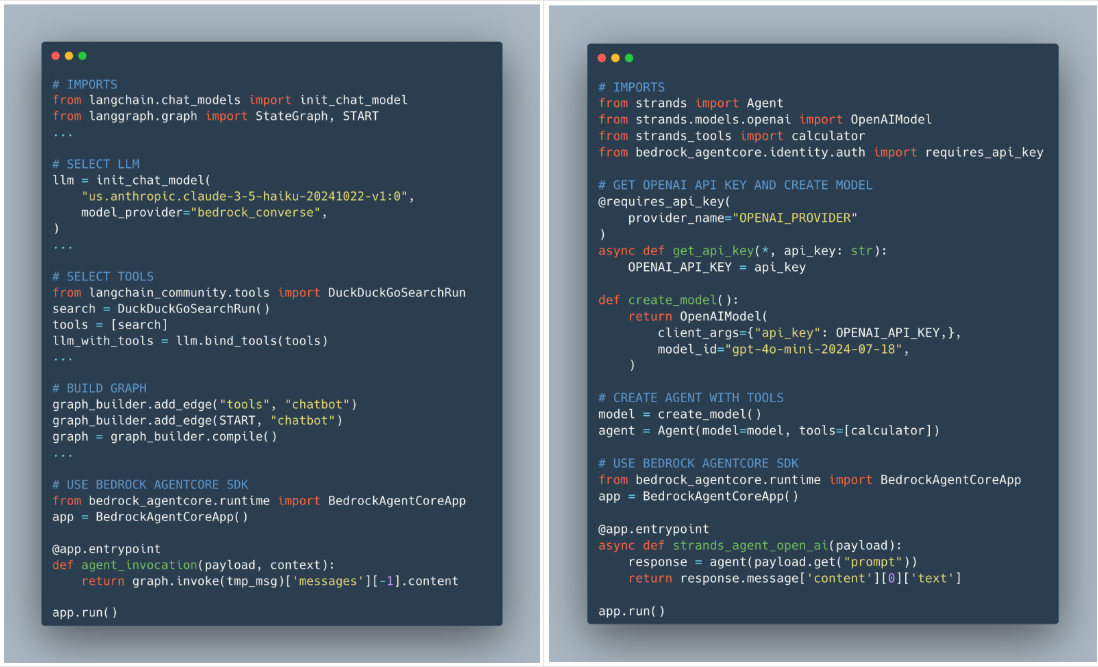
Let’s examine how AgentCore Runtime supports two different frameworks and model providers:
| LangGraph agent using Anthropic’s Claude Sonnet on Amazon Bedrock | Strands agent using GPT 4o mini through the OpenAI API |
 |
|
For the full code examples, refer to langgraph_agent_web_search.py and strands_openai_identity.py on GitHub.
Both examples above show how you can use AgentCore SDK, regardless of the underlying framework or model choice. After you have modified your code as shown in these examples, you can deploy your agent with or without the AgentCore Runtime starter toolkit, discussed in the next section.
Note that there are minimal additions, specific to AgentCore SDK, to the example code above. Let us dive deeper into this in the next section.
Deploy, scale, and stream agent responses with four lines of code
Let’s examine the two examples above. In both examples, we only add four new lines of code:
- Import –
from bedrock_agentcore.runtime import BedrockAgentCoreApp - Initialize –
app = BedrockAgentCoreApp() - Decorate –
@app.entrypoint - Run –
app.run()
Once you have made these changes, the most straightforward way to get started with agentcore is to use the AgentCore Starter toolkit. We suggest using uv to create and manage local development environments and package requirements in python. To get started, install the starter toolkit as follows:
Run the appropriate commands to configure, launch, and invoke to deploy and use your agent. The following video provides a quick walkthrough.
For your chat style applications, AgentCore Runtime supports streaming out of the box. For example, in Strands, locate the following synchronous code:
Change the preceding code to the following and deploy:
For more examples on streaming agents, refer to the following GitHub repo. The following is an example streamlit application streaming back responses from an AgentCore Runtime agent.
Secure agent execution with session isolation and embedded identity
AgentCore Runtime fundamentally changes how we think about serverless compute for agentic applications by introducing persistent execution environments that can maintain an agent’s state across multiple invocations. Rather than the typical serverless model where functions spin up, execute, and immediately terminate, AgentCore Runtime provisions dedicated microVMs that can persist for up to 8 hours. This enables sophisticated multi-step agentic workflows where each subsequent call builds upon the accumulated context and state from previous interactions within the same session. The practical implication of this is that you can now implement complex, stateful logic patterns that would previously require external state management solutions or cumbersome workarounds to maintain context between function executions. This doesn’t obviate the need for external state management (see the following section on using AgentCore Runtime with AgentCore Memory), but is a common need for maintaining local state and files temporarily, within a session context.
Understanding the session lifecycle
The session lifecycle operates through three distinct states that govern resource allocation and availability (see diagram below for a high level view of this session lifecycle). When you first invoke a runtime with a unique session identifier, AgentCore provisions a dedicated execution environment and transitions it to an Active state during request processing or when background tasks are running.
The system automatically tracks synchronous invocation activity, while background processes can signal their status through HealthyBusy responses to health check pings from the service (see the later section on asynchronous workloads). Sessions transition to Idle when not processing requests but remain provisioned and ready for immediate use, reducing cold start penalties for subsequent invocations.
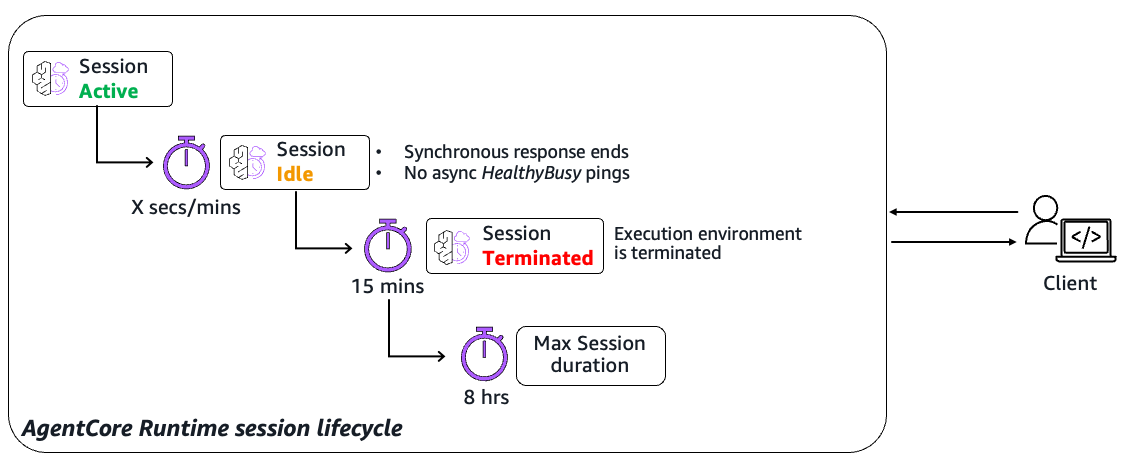
Finally, sessions reach a Terminated state when they currently exceed a 15-minute inactivity threshold, hit the 8-hour maximum duration limit, or fail health checks. Understanding these state transitions is crucial for designing resilient workflows that gracefully handle session boundaries and resource cleanup. For more details on session lifecycle-related quotas, refer to AgentCore Runtime Service Quotas.
The ephemeral nature of AgentCore sessions means that runtime state exists solely within the boundaries of the active session lifecycle. The data your agent accumulates during execution—such as conversation context, user preference mappings, intermediate computational results, or transient workflow state—remains accessible only while the session persists and is completely purged when the session terminates.
For persistent data requirements that extend beyond individual session boundaries, AgentCore Memory provides the architectural solution for durable state management. This purpose-built service is specifically engineered for agent workloads and offers both short-term and long-term memory abstractions that can maintain user conversation histories, learned behavioral patterns, and critical insights across session boundaries. See documentation here for more information on getting started with AgentCore Memory.
True session isolation
Session isolation in AI agent workloads addresses fundamental security and operational challenges that don’t exist in traditional application architectures. Unlike stateless functions that process individual requests independently, AI agents maintain complex contextual state throughout extended reasoning processes, handle privileged operations with sensitive credentials and files, and exhibit non-deterministic behavior patterns. This creates unique risks where one user’s agent could potentially access another’s data—session-specific information could be used across multiple sessions, credentials could leak between sessions, or unpredictable agent behavior could compromise system boundaries. Traditional containerization or process isolation isn’t sufficient because agents need persistent state management while maintaining absolute separation between users.
Let’s explore a case study: In May 2025, Asana deployed a new MCP server to power agentic AI features (integrations with ChatGPT, Anthropic’s Claude, Microsoft Copilot) across its enterprise software as a service (SaaS) offering. Due to a logic flaw in MCP’s tenant isolation and relying solely on user but not agent identity, requests from one organization’s user could inadvertently retrieve cached results containing another organization’s data. This cross-tenant contamination wasn’t triggered by a targeted exploit but was an intrinsic security fault in handling context and cache separation across agentic AI-driven sessions.
The exposure silently persisted for 34 days, impacting roughly 1,000 organizations, including major enterprises. After it was discovered, Asana halted the service, remediated the bug, notified affected customers, and released a fix.
AgentCore Runtime solves these challenges through complete microVM isolation that goes beyond simple resource separation. Each session receives its own dedicated virtual machine with isolated compute, memory, and file system resources, making sure agent state, tool operations, and credential access remain completely compartmentalized. When a session ends, the entire microVM is terminated and memory sanitized, minimizing the risk of data persistence or cross-contamination. This architecture provides the deterministic security boundaries that enterprise deployments require, even when dealing with the inherently probabilistic and non-deterministic nature of AI agents, while still enabling the stateful, personalized experiences that make agents valuable. Although other offerings might provide sandboxed kernels, with the ability to manage your own session state, persistence, and isolation, this should not be treated a strict security boundary. AgentCore Runtime provides consistent, deterministic isolation boundaries regardless of agent execution patterns, delivering the predictable security properties required for enterprise deployments. The following diagram shows how two separate sessions run in isolated microVM kernels.
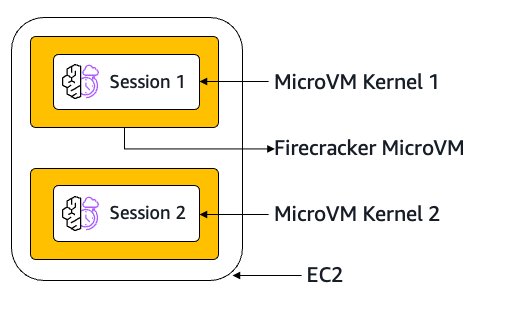
AgentCore Runtime embedded identity
Traditional agent deployments often struggle with identity and access management, particularly when agents need to act on behalf of users or access external services securely. The challenge becomes even more complex in multi-tenant environments—for example, where you need to make sure Agent A accessing Google Drive on behalf of User 1 can never accidentally retrieve data belonging to User 2.
AgentCore Runtime addresses these challenges through its embedded identity system that seamlessly integrates authentication and authorization into the agent execution environment. First, each runtime is associated with a unique workload identity (you can treat this as a unique agent identity). The service supports two primary authentication mechanisms for agents using this unique agent identity: IAM SigV4 Authentication for agents operating within AWS security boundaries, and OAuth based (JWT Bearer Token Authentication) integration with existing enterprise identity providers like Amazon Cognito, Okta, or Microsoft Entra ID.
When deploying an agent with AWS Identity and Access Management (IAM) authentication, users don’t have to incorporate other Amazon Bedrock AgentCore Identity specific settings or setup—simply configure with IAM authorization, launch, and invoke with the right user credentials.
When using JWT authentication, you configure the authorizer during the CreateAgentRuntime operation, specifying your identity provider (IdP)-specific discovery URL and allowed clients. Your existing agent code requires no modification—you simply add the authorizer configuration to your runtime deployment. When a calling entity or user invokes your agent, they pass their IdP-specific access token as a bearer token in the Authorization header. AgentCore Runtime uses AgentCore Identity to automatically validate this token against your configured authorizer and rejects unauthorized requests. The following diagram shows the flow of information between AgentCore runtime, your IdP, AgentCore Identity, other AgentCore services, other AWS services (in orange), and other external APIs or resources (in purple).
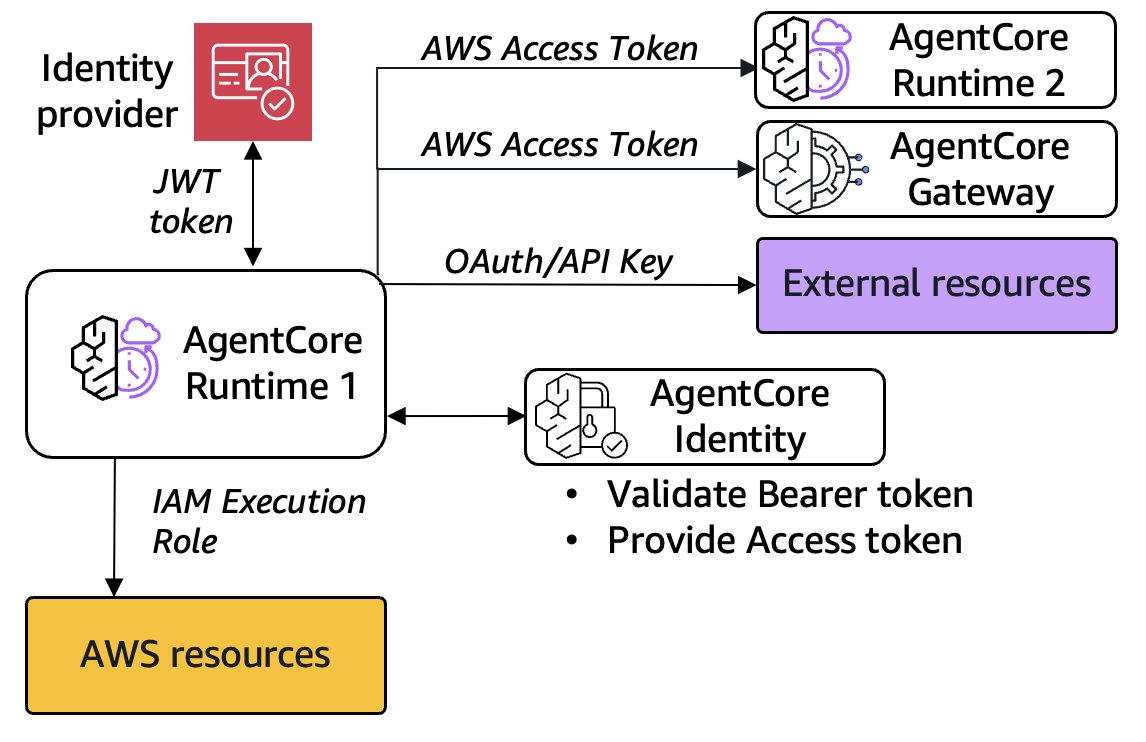
Behind the scenes, AgentCore Runtime automatically exchanges validated user tokens for workload access tokens (through the bedrock-agentcore:GetWorkloadAccessTokenForJWT API). This provides secure outbound access to external services through the AgentCore credential provider system, where tokens are cached using the combination of agent workload identity and user ID as the binding key. This cryptographic binding makes sure, for example, User 1’s Google token can never be accessed when processing requests for User 2, regardless of application logic errors. Note that in the preceding diagram, connecting to AWS resources can be achieved simply by editing the AgentCore Runtime execution role, but connections to Amazon Bedrock AgentCore Gateway or to another runtime will require reauthorization with a new access token.
The most straightforward way to configure your agent with OAuth-based inbound access is to use the AgentCore starter toolkit:
- With the AWS Command Line Interface (AWS CLI), follow the prompts to interactively enter your OAuth discovery URL and allowed Client IDs (comma-separated).
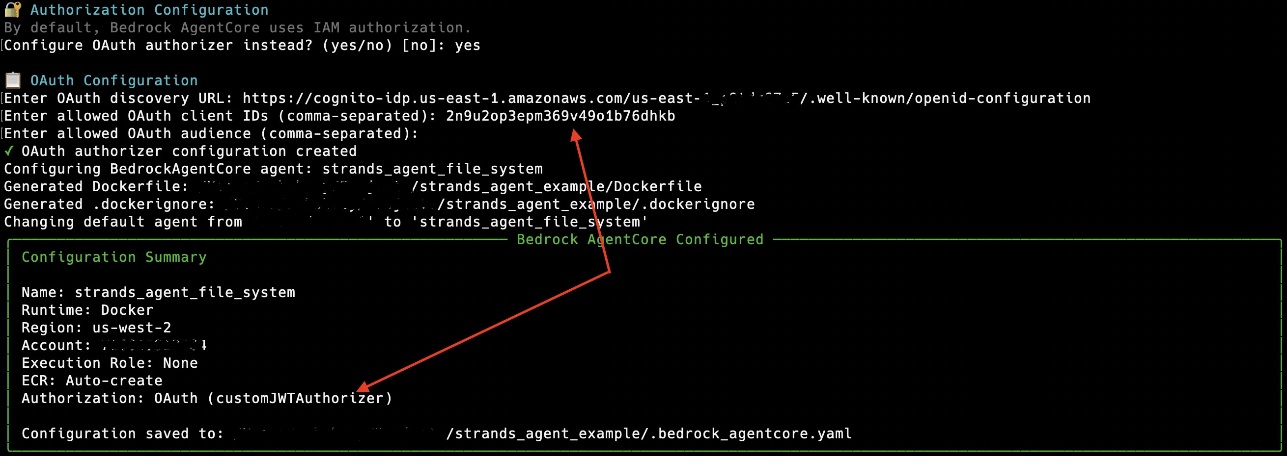
- With Python, use the following code:
- For outbound access (for example, if your agent uses OpenAI APIs), first set up your keys using the API or the Amazon Bedrock console, as shown in the following screenshot.

- Then access your keys from within your AgentCore Runtime agent code:
For more information on AgentCore Identity, refer to Authenticate and authorize with Inbound Auth and Outbound Auth and Hosting AI Agents on AgentCore Runtime.
Use AgentCore Runtime state persistence with AgentCore Memory
AgentCore Runtime provides ephemeral, session-specific state management that maintains context during active conversations but doesn’t persist beyond the session lifecycle. Each user session preserves conversational state, objects in memory, and local temporary files within isolated execution environments. For short-lived agents, you can use the state persistence offered by AgentCore Runtime without needing to save this information externally. However, at the end of the session lifecycle, the ephemeral state is permanently destroyed, making this approach suitable only for interactions that don’t require knowledge retention across separate conversations.
AgentCore Memory addresses this challenge by providing persistent storage that survives beyond individual sessions. Short-term memory captures raw interactions as events using create_event, storing the complete conversation history that can be retrieved with get_last_k_turns even if the runtime session restarts. Long-term memory uses configurable strategies to extract and consolidate key insights from these raw interactions, such as user preferences, important facts, or conversation summaries. Through retrieve_memories, agents can access this persistent knowledge across completely different sessions, enabling personalized experiences. The following diagram shows how AgentCore Runtime can use specific APIs to interact with Short-term and Long-term memory in AgentCore Memory.
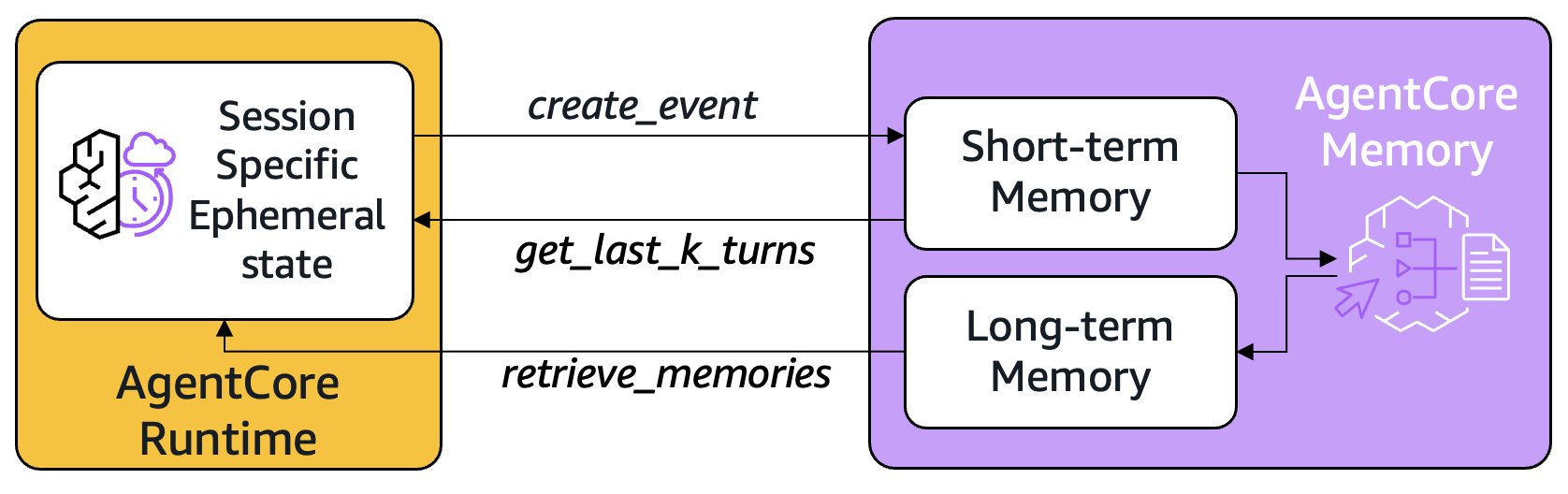
This basic architecture, of using a runtime to host your agents, and a combination of short- and long-term memory has become commonplace in most agentic AI applications today. Invocations to AgentCore Runtime with the same session ID lets you access the agent state (for example, in a conversational flow) as though it were running locally, without the overhead of external storage operations, and AgentCore Memory selectively captures and structures the valuable information worth preserving beyond the session lifecycle. This hybrid approach means agents can maintain fast, contextual responses during active sessions while building cumulative intelligence over time. The automatic asynchronous processing of long-term memories according to each strategy in AgentCore Memory makes sure insights are extracted and consolidated without impacting real-time performance, creating a seamless experience where agents become progressively more helpful while maintaining responsive interactions. This architecture avoids the traditional trade-off between conversation speed and long-term learning, enabling agents that are both immediately useful and continuously improving.
Process different modalities with large payloads
Most AI agent systems struggle with large file processing due to strict payload size limits, typically capping requests at just a few megabytes. This forces developers to implement complex file chunking, multiple API calls, or external storage solutions that add latency and complexity. AgentCore Runtime removes these constraints by supporting payloads up to 100 MB in size, enabling agents to process substantial datasets, high-resolution images, audio, and comprehensive document collections in a single invocation.
Consider a financial audit scenario where you need to verify quarterly sales performance by comparing detailed transaction data against a dashboard screenshot from your analytics system. Traditional approaches would require using external storage such as Amazon Simple Storage Service (Amazon S3) or Google Drive to download the Excel file and image into the container running the agent logic. With AgentCore Runtime, you can send both the comprehensive sales data and the dashboard image in a single payload from the client:
The agent’s entrypoint function can be modified to process both data sources simultaneously, enabling this cross-validation analysis:
To test out an example of using large payloads, refer to the following GitHub repo.
Operate asynchronous multi-hour agents
As AI agents evolve to tackle increasingly complex tasks—from processing large datasets to generating comprehensive reports—they often require multi-step processing that can take significant time to complete. However, most agent implementations are synchronous (with response streaming) that block until completion. While synchronous, streaming agents are a common way to expose agentic chat applications to users, users cannot interact with the agent when a task or tool is still running, view the status of, or cancel background operations, or start more concurrent tasks while others have still not completed.
Building asynchronous agents forces developers to implement complex distributed task management systems with state persistence, job queues, worker coordination, failure recovery, and cross-invocation state management while also navigating serverless system limitations like execution timeouts (tens of minutes), payload size restrictions, and cold start penalties for long-running compute operations—a significant heavy lift that diverts focus from core functionality.
AgentCore Runtime alleviates this complexity through stateful execution sessions that maintain context across invocations, so developers can build upon previous work incrementally without implementing complex task management logic. The AgentCore SDK provides ready-to-use constructs for tracking asynchronous tasks and seamlessly managing compute lifecycles, and AgentCore Runtime supports execution times up to 8 hours and request/response payload sizes of 100 MB, making it suitable for most asynchronous agent tasks.
Getting started with asynchronous agents
You can get started with just a couple of code changes:
To build interactive agents that perform asynchronous tasks, simply call add_async_task when starting a task and complete_async_task when finished. The SDK automatically handles task tracking and manages compute lifecycle for you.
These two method calls transform your synchronous agent into a fully asynchronous, interactive system. Refer to this sample for more details.
The following example shows the difference between a synchronous agent that streams back responses to the user immediately vs. a more complex multi-agent scenario where longer running, asynchronous background shopping agents use Amazon Bedrock AgentCore Browser to automate a shopping experience on amazon.com on behalf of the user.
Pay only for Used Resources
Amazon Bedrock AgentCore Runtime introduces a consumption-based pricing model that fundamentally changes how you pay for AI agent infrastructure. Unlike traditional compute models that charge for allocated resources regardless of utilization, AgentCore Runtime bills you only for what you actually use however long you use it; said differently, you don’t have to pre-allocate resources like CPU or GB Memory, and you don’t pay for CPU resources during I/O wait periods. This distinction is particularly valuable for AI agents, which typically spend significant time waiting for LLM responses or external API calls to complete. Here is a typical Agent event loop, where we only expect the purple boxes to be processed within Runtime:

The LLM call (light blue) and tool call (green) boxes take time, but are run outside the context of AgentCore Runtime; users only pay for processing that happens in Runtime itself (purple boxes). Let’s look at some real-world examples to understand the impact:
Customer support agent example
Consider a customer support agent that handles 10,000 user inquiries per day. Each interaction involves initial query processing, knowledge retrieval from Retrieval Augmented Generation (RAG) systems, LLM reasoning for response formulation, API calls to order systems, and final response generation. In a typical session lasting 60 seconds, the agent could actively use CPU for only 18 seconds (30%) while spending the remaining 42 seconds (70%) waiting for LLM responses or API calls to complete. Memory usage can fluctuate between 1.5 GB to 2.5 GB depending on the complexity of the customer query and the amount of context needed. With traditional compute models, you would pay for the full 60 seconds of CPU time and peak memory allocation. With AgentCore Runtime, you only pay for the 18 seconds of active CPU processing and the actual memory consumed moment-by-moment:
For 10,000 daily sessions, this represents a 70% reduction in CPU costs compared to traditional models that would charge for the full 60 seconds.
Data analysis agent example
The savings become even more dramatic for data processing agents that handle complex workflows. A financial analysis agent processing quarterly reports might run for three hours but have highly variable resource needs. During data loading and initial parsing, it might use minimal resources (0.5 vCPU, 2 GB memory). When performing complex calculations or running statistical models, it might spike to 2 vCPU and 8 GB memory for just 15 minutes of the total runtime, while spending the remaining time waiting for batch operations or model inferences at much lower resource utilization. By charging only for actual resource consumption while maintaining your session state during I/O waits, AgentCore Runtime aligns costs directly with value creation, making sophisticated agent deployments economically viable at scale.
Conclusion
In this post, we explored how AgentCore Runtime simplifies the deployment and management of AI agents. The service addresses critical challenges that have traditionally blocked agent adoption at scale, offering framework-agnostic deployment, true session isolation, embedded identity management, and support for large payloads and long-running, asynchronous agents, all with a consumption based model where you pay only for the resources you use.
With just four lines of code, developers can securely launch and scale their agents while using AgentCore Memory for persistent state management across sessions. For hands-on examples on AgentCore Runtime covering simple tutorials to complex use cases, and demonstrating integrations with various frameworks such as LangGraph, Strands, CrewAI, MCP, ADK, Autogen, LlamaIndex, and OpenAI Agents, refer to the following examples on GitHub:
- Amazon Bedrock AgentCore Runtime
- Amazon Bedrock AgentCore Samples: Agentic Frameworks
- Hosting MCP server on AgentCore Runtime
- Amazon Bedrock AgentCore Starter Toolkit
- Runtime QuickStart guide
About the authors
 Shreyas Subramanian is a Principal Data Scientist and helps customers by using Generative AI and deep learning to solve their business challenges using AWS services like Amazon Bedrock and AgentCore. Dr. Subramanian contributes to cutting-edge research in deep learning, Agentic AI, foundation models and optimization techniques with several books, papers and patents to his name. In his current role at Amazon, Dr. Subramanian works with various science leaders and research teams within and outside Amazon, helping to guide customers to best leverage state-of-the-art algorithms and techniques to solve business critical problems. Outside AWS, Dr. Subramanian is a expert reviewer for AI papers and funding via organizations like Neurips, ICML, ICLR, NASA and NSF.
Shreyas Subramanian is a Principal Data Scientist and helps customers by using Generative AI and deep learning to solve their business challenges using AWS services like Amazon Bedrock and AgentCore. Dr. Subramanian contributes to cutting-edge research in deep learning, Agentic AI, foundation models and optimization techniques with several books, papers and patents to his name. In his current role at Amazon, Dr. Subramanian works with various science leaders and research teams within and outside Amazon, helping to guide customers to best leverage state-of-the-art algorithms and techniques to solve business critical problems. Outside AWS, Dr. Subramanian is a expert reviewer for AI papers and funding via organizations like Neurips, ICML, ICLR, NASA and NSF.
 Kosti Vasilakakis is a Principal PM at AWS on the Agentic AI team, where he has led the design and development of several Bedrock AgentCore services from the ground up, including Runtime. He previously worked on Amazon SageMaker since its early days, launching AI/ML capabilities now used by thousands of companies worldwide. Earlier in his career, Kosti was a data scientist. Outside of work, he builds personal productivity automations, plays tennis, and explores the wilderness with his family.
Kosti Vasilakakis is a Principal PM at AWS on the Agentic AI team, where he has led the design and development of several Bedrock AgentCore services from the ground up, including Runtime. He previously worked on Amazon SageMaker since its early days, launching AI/ML capabilities now used by thousands of companies worldwide. Earlier in his career, Kosti was a data scientist. Outside of work, he builds personal productivity automations, plays tennis, and explores the wilderness with his family.
 Vivek Bhadauria is a Principal Engineer at Amazon Bedrock with almost a decade of experience in building AI/ML services. He now focuses on building generative AI services such as Amazon Bedrock Agents and Amazon Bedrock Guardrails. In his free time, he enjoys biking and hiking.
Vivek Bhadauria is a Principal Engineer at Amazon Bedrock with almost a decade of experience in building AI/ML services. He now focuses on building generative AI services such as Amazon Bedrock Agents and Amazon Bedrock Guardrails. In his free time, he enjoys biking and hiking.