Meetings play a crucial role in decision-making, project coordination, and collaboration, and remote meetings are common across many organizations. However, capturing and structuring key takeaways from these conversations is often inefficient and inconsistent. Manually summarizing meetings or extracting action items requires significant effort and is prone to omissions or misinterpretations.
Large language models (LLMs) offer a more robust solution by transforming unstructured meeting transcripts into structured summaries and action items. This capability is especially useful for project management, customer support and sales calls, legal and compliance, and enterprise knowledge management.
In this post, we present a benchmark of different understanding models from the Amazon Nova family available on Amazon Bedrock, to provide insights on how you can choose the best model for a meeting summarization task.
LLMs to generate meeting insights
Modern LLMs are highly effective for summarization and action item extraction due to their ability to understand context, infer topic relationships, and generate structured outputs. In these use cases, prompt engineering provides a more efficient and scalable approach compared to traditional model fine-tuning or customization. Rather than modifying the underlying model architecture or training on large labeled datasets, prompt engineering uses carefully crafted input queries to guide the model’s behavior, directly influencing the output format and content. This method allows for rapid, domain-specific customization without the need for resource-intensive retraining processes. For tasks such as meeting summarization and action item extraction, prompt engineering enables precise control over the generated outputs, making sure they meet specific business requirements. It allows for the flexible adjustment of prompts to suit evolving use cases, making it an ideal solution for dynamic environments where model behaviors need to be quickly reoriented without the overhead of model fine-tuning.
Amazon Nova models and Amazon Bedrock
Amazon Nova models, unveiled at AWS re:Invent in December 2024, are built to deliver frontier intelligence at industry-leading price performance. They’re among the fastest and most cost-effective models in their respective intelligence tiers, and are optimized to power enterprise generative AI applications in a reliable, secure, and cost-effective manner.
The understanding model family has four tiers of models: Nova Micro (text-only, ultra-efficient for edge use), Nova Lite (multimodal, balanced for versatility), Nova Pro (multimodal, balance of speed and intelligence, ideal for most enterprise needs) and Nova Premier (multimodal, the most capable Nova model for complex tasks and teacher for model distillation). Amazon Nova models can be used for a variety of tasks, from summarization to structured text generation. With Amazon Bedrock Model Distillation, customers can also bring the intelligence of Nova Premier to a faster and more cost-effective model such as Nova Pro or Nova Lite for their use case or domain. This can be achieved through the Amazon Bedrock console and APIs such as the Converse API and Invoke API.
Solution overview
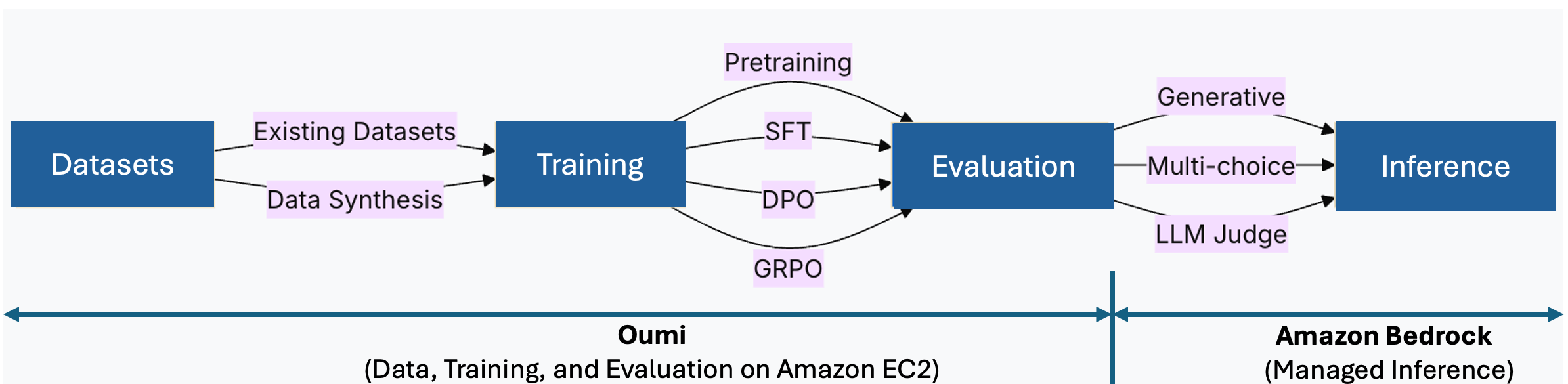
This post demonstrates how to use Amazon Nova understanding models, available through Amazon Bedrock, for automated insight extraction using prompt engineering. We focus on two key outputs:
- Meeting summarization – A high-level abstractive summary that distills key discussion points, decisions made, and critical updates from the meeting transcript
- Action items – A structured list of actionable tasks derived from the meeting conversation that apply to the entire team or project
The following diagram illustrates the solution workflow.

Prerequisites
To follow along with this post, familiarity with calling LLMs using Amazon Bedrock is expected. For detailed steps on using Amazon Bedrock for text summarization tasks, refer to Build an AI text summarizer app with Amazon Bedrock. For additional information about calling LLMs, refer to the Invoke API and Using the Converse API reference documentation.
Solution components
We developed the two core features of the solution—meeting summarization and action item extraction—by using popular models available through Amazon Bedrock. In the following sections, we look at the prompts that were used for these key tasks.
For the meeting summarization task, we used a persona assignment, prompting the LLM to generate a summary in <summary> tags to reduce redundant opening and closing sentences, and a one-shot approach by giving the LLM one example to make sure the LLM consistently follows the right format for summary generation. As part of the system prompt, we give clear and concise rules emphasizing the correct tone, style, length, and faithfulness towards the provided transcript.
For the action item extraction task, we gave specific instructions on generating action items in the prompts and used chain-of-thought to improve the quality of the generated action items. In the assistant message, the prefix <action_items> tag is provided as a prefilling to nudge the model generation in the right direction and to avoid redundant opening and closing sentences.
Different model families respond to the same prompts differently, and it’s important to follow the prompting guide defined for the particular model. For more information on best practices for Amazon Nova prompting, refer to Prompting best practices for Amazon Nova understanding models.
Dataset
To evaluate the solution, we used the samples for the public QMSum dataset. The QMSum dataset is a benchmark for meeting summarization, featuring English language transcripts from academic, business, and governance discussions with manually annotated summaries. It evaluates LLMs on generating structured, coherent summaries from complex and multi-speaker conversations, making it a valuable resource for abstractive summarization and discourse understanding. For testing, we used 30 randomly sampled meetings from the QMSum dataset. Each meeting contained 2–5 topic-wise transcripts and contained approximately 8,600 tokens for each transcript in average.
Evaluation framework
Achieving high-quality outputs from LLMs in meeting summarization and action item extraction can be a challenging task. Traditional evaluation metrics such as ROUGE, BLEU, and METEOR focus on surface-level similarity between generated text and reference summaries, but they often fail to capture nuances such as factual correctness, coherence, and actionability. Human evaluation is the gold standard but is expensive, time-consuming, and not scalable. To address these challenges, you can use LLM-as-a-judge, where another LLM is used to systematically assess the quality of generated outputs based on well-defined criteria. This approach offers a scalable and cost-effective way to automate evaluation while maintaining high accuracy. In this example, we used Anthropic’s Claude 3.5 Sonnet v1 as the judge model because we found it to be most aligned with human judgment. We used the LLM judge to score the generated responses on three main metrics: faithfulness, summarization, and question answering (QA).
The faithfulness score measures the faithfulness of a generated summary by measuring the portion of the parsed statements in a summary that are supported by given context (for example, a meeting transcript) with respect to the total number of statements.
The summarization score is the combination of the QA score and the conciseness score with the same weight (0.5). The QA score measures the coverage of a generated summary from a meeting transcript. It first generates a list of question and answer pairs from a meeting transcript and measures the portion of the questions that are asked correctly when the summary is used as a context instead of a meeting transcript. The QA score is complimentary to the faithfulness score because the faithfulness score doesn’t measure the coverage of a generated summary. We only used the QA score to measure the quality of a generated summary because the action items aren’t supposed to cover all aspects of a meeting transcript. The conciseness score measures the ratio of the length of a generated summary divided by the length of the total meeting transcript.
We used a modified version of the faithfulness score and the summarization score that had much lower latency than the original implementation.
Results
Our evaluation of Amazon Nova models across meeting summarization and action item extraction tasks revealed clear performance-latency patterns. For summarization, Nova Premier achieved the highest faithfulness score (1.0) with a processing time of 5.34s, while Nova Pro delivered 0.94 faithfulness in 2.9s. The smaller Nova Lite and Nova Micro models provided faithfulness scores of 0.86 and 0.83 respectively, with faster processing times of 2.13s and 1.52s. In action item extraction, Nova Premier again led in faithfulness (0.83) with 4.94s processing time, followed by Nova Pro (0.8 faithfulness, 2.03s). Interestingly, Nova Micro (0.7 faithfulness, 1.43s) outperformed Nova Lite (0.63 faithfulness, 1.53s) in this particular task despite its smaller size. These measurements provide valuable insights into the performance-speed characteristics across the Amazon Nova model family for text-processing applications. The following graphs show these results. The following screenshot shows a sample output for our summarization task, including the LLM-generated meeting summary and a list of action items.



Conclusion
In this post, we showed how you can use prompting to generate meeting insights such as meeting summaries and action items using Amazon Nova models available through Amazon Bedrock. For large-scale AI-driven meeting summarization, optimizing latency, cost, and accuracy is essential. The Amazon Nova family of understanding models (Nova Micro, Nova Lite, Nova Pro, and Nova Premier) offers a practical alternative to high-end models, significantly improving inference speed while reducing operational costs. These factors make Amazon Nova an attractive choice for enterprises handling large volumes of meeting data at scale.
For more information on Amazon Bedrock and the latest Amazon Nova models, refer to the Amazon Bedrock User Guide and Amazon Nova User Guide, respectively. The AWS Generative AI Innovation Center has a group of AWS science and strategy experts with comprehensive expertise spanning the generative AI journey, helping customers prioritize use cases, build a roadmap, and move solutions into production. Check out the Generative AI Innovation Center for our latest work and customer success stories.
About the Authors
 Baishali Chaudhury is an Applied Scientist at the Generative AI Innovation Center at AWS, where she focuses on advancing Generative AI solutions for real-world applications. She has a strong background in computer vision, machine learning, and AI for healthcare. Baishali holds a PhD in Computer Science from University of South Florida and PostDoc from Moffitt Cancer Centre.
Baishali Chaudhury is an Applied Scientist at the Generative AI Innovation Center at AWS, where she focuses on advancing Generative AI solutions for real-world applications. She has a strong background in computer vision, machine learning, and AI for healthcare. Baishali holds a PhD in Computer Science from University of South Florida and PostDoc from Moffitt Cancer Centre.
 Sungmin Hong is a Senior Applied Scientist at Amazon Generative AI Innovation Center where he helps expedite the variety of use cases of AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds Ph.D. in Computer Science from New York University. Outside of work, he prides himself on keeping his indoor plants alive for 3+ years.
Sungmin Hong is a Senior Applied Scientist at Amazon Generative AI Innovation Center where he helps expedite the variety of use cases of AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds Ph.D. in Computer Science from New York University. Outside of work, he prides himself on keeping his indoor plants alive for 3+ years.
 Mengdie (Flora) Wang is a Data Scientist at AWS Generative AI Innovation Center, where she works with customers to architect and implement scalable Generative AI solutions that address their unique business challenges. She specializes in model customization techniques and agent-based AI systems, helping organizations harness the full potential of generative AI technology. Prior to AWS, Flora earned her Master’s degree in Computer Science from the University of Minnesota, where she developed her expertise in machine learning and artificial intelligence.
Mengdie (Flora) Wang is a Data Scientist at AWS Generative AI Innovation Center, where she works with customers to architect and implement scalable Generative AI solutions that address their unique business challenges. She specializes in model customization techniques and agent-based AI systems, helping organizations harness the full potential of generative AI technology. Prior to AWS, Flora earned her Master’s degree in Computer Science from the University of Minnesota, where she developed her expertise in machine learning and artificial intelligence.
 Anila Joshi has more than a decade of experience building AI solutions. As a AWSI Geo Leader at AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and accelerate the adoption of AWS services with customers by helping customers ideate, identify, and implement secure generative AI solutions.
Anila Joshi has more than a decade of experience building AI solutions. As a AWSI Geo Leader at AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and accelerate the adoption of AWS services with customers by helping customers ideate, identify, and implement secure generative AI solutions.