Developing robust text-to-SQL capabilities is a critical challenge in the field of natural language processing (NLP) and database management. The complexity of NLP and database management increases in this field, particularly while dealing with complex queries and database structures. In this post, we introduce a straightforward but powerful solution with accompanying code to text-to-SQL using a custom agent implementation along with Amazon Bedrock and Converse API.
The ability to translate natural language queries into SQL statements is a game-changer for businesses and organizations because users can now interact with databases in a more intuitive and accessible manner. However, the complexity of database schemas, relationships between tables, and the nuances of natural language can often lead to inaccurate or incomplete SQL queries. This not only compromises the integrity of the data but also hinders the overall user experience. Through a straightforward yet powerful architecture, the agent can understand your query, develop a plan of execution, create SQL statements, self-correct if there is a SQL error, and learn from its execution to improve in the future. Overtime, the agent can develop a cohesive understanding of what to do and what not to do to efficiently answer queries from users.
Solution overview
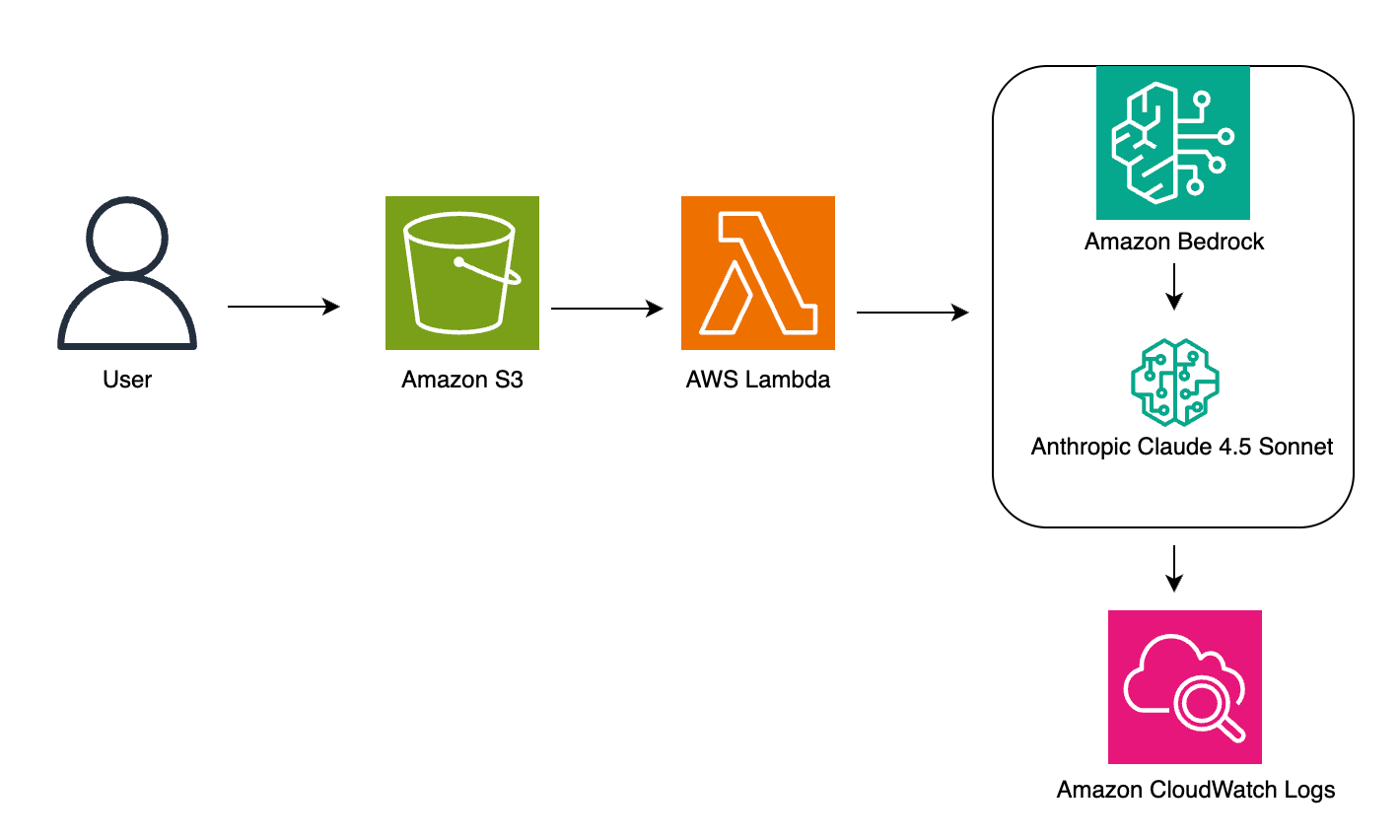
The solution is composed of an AWS Lambda function that contains the logic of the agent that communicates with Amazon DynamoDB for long-term memory retention, calls Anthropic’s Claude Sonnet in Amazon Bedrock through Converse API, uses AWS Secrets Manager to retrieve database connection details and credentials, and Amazon Relational Database Service (Amazon RDS) that contains an example Postgres database called HR Database. The Lambda function is connected to a virtual private cloud (VPC) and communicates with DynamoDB, Amazon Bedrock, and Secrets Manager through AWS PrivateLink VPC endpoints so that the Lambda can communicate with the RDS database while keeping traffic private through AWS networking.
In the demo, you can interact with the agent through the Lambda function. You can provide it a natural language query, such as “How many employees are there in each department in each region?” or “What is the employee mix by gender in each region”. The following is the solution architecture.

A custom agent build using Converse API
Converse API is provided by Amazon Bedrock for you to be able to create conversational applications. It enables powerful features such as tool use. Tool use is the ability for a large language model (LLM) to choose from a list of tools, such as running SQL queries against a database, and decide which tool to use depending on the context of the conversation. Using Converse API also means you can maintain a series of messages between User and Assistant roles to carry out a chat with an LLM such as Anthropic’s Claude 3.5 Sonnet. In this post, a custom agent called ConverseSQLAgent was created specifically for long-running agent executions and to follow a plan of execution.
The Agent loop: Agent planning, self-correction, and long-term learning
The agent contains several key features: planning and carry-over, execution and tool use, SQLAlchemy and self-correction, reflection and long-term learning using memory.
Planning and carry-over
The first step that the agent takes is to create a plan of execution to perform the text-to-SQL task. It first thinks through what the user is asking and develops a plan on how it will fulfill the request of the user. This behavior is controlled using a system prompt, which defines how the agent should behave. After the agent thinks through what it should do, it outputs the plan.
One of the challenges with long-running agent execution is that sometimes the agent will forget the plan that it was supposed to execute as the context becomes longer and longer as it conducts its steps. One of the primary ways to deal with this is by “carrying over” the initial plan by injecting it back into a section in the system prompt. The system prompt is part of every converse API call, and it improves the ability of the agent to follow its plan. Because the agent may revise its plan as it progresses through the execution, the plan in the system prompt is updated as new plans emerge. Refer to the following figure on how the carry over works.

Execution and tool use
After the plan has been created, the agent will execute its plan one step at a time. It might decide to call on one or more tools it has access to. With Converse API, you can pass in a toolConfig that contains the toolSpec for each tool it has access to. The toolSpec defines what the tool is, a description of the tool, and the parameters that the tool requires. When the LLM decides to use a tool, it outputs a tool use block as part of its response. The application, in this case the Lambda code, needs to identify that tool use block, execute the corresponding tool, append the tool result response to the message list, and call the Converse API again. As shown at (a) in the following figure, you can add tools for the LLM to choose from by adding in a toolConfig along with toolSpecs. Part (b) shows that in the implementation of ConverseSQLAgent, tool groups contain a collection of tools, and each tool contains the toolSpec and the callable function. The tool groups are added to the agent, which in turn adds it to the Converse API call. Tool group instructions are additional instructions on how to use the tool group that get injected into the system prompt. Although you can add descriptions to each individual tool, having tool group–wide instructions enable more effective usage of the group.

SQLAlchemy and self-correction
The SQL tool group (these tools are part of the demo code provided), as shown in the preceding figure, is implemented using SQLAlchemy, which is a Python SQL toolkit you can use to interface with different databases without having to worry about database-specific SQL syntax. You can connect to Postgres, MySQL, and more without having to change your code every time.
In this post, there is an InvokeSQLQuery tool that allows the agent to execute arbitrary SQL statements. Although almost all database specific tasks, such as looking up schemas and tables, can be accomplished through InvokeSQLQuery, it’s better to provide SQLAlchemy implementations for specific tasks, such as GetDatabaseSchemas, which gets every schema in the database, greatly reducing the time it takes for the agent to generate the correct query. Think of it as giving the agent a shortcut to getting the information it needs. The agents can make errors in querying the database through the InvokeSQLQuery tool. The InvokeSQLQuery tool will respond with the error that it encountered back to the agent, and the agent can perform self-correction to correct the query. This flow is shown in the following diagram.

Reflection and long-term learning using memory
Although self-correction is an important feature of the agent, the agent must be able to learn through its mistakes to avoid the same mistake in the future. Otherwise, the agent will continue to make the mistake, greatly reducing effectiveness and efficiency. The agent maintains a hierarchical memory structure, as shown in the following figure. The agent decides how to structure its memory. Here is an example on how it may structure it.

The agent can reflect on its execution, learn best practices and error avoidance, and save it into long-term memory. Long-term memory is implemented through a hierarchical memory structure with Amazon DynamoDB. The agent maintains a main memory that has pointers to other memories it has. Each memory is represented as a record in a DynamoDB table. As the agent learns through its execution and encounters errors, it can update its main memory and create new memories by maintaining an index of memories in the main memory. It can then tap onto this memory in the future to avoid errors and even improve the efficiency of queries by caching facts.
Prerequisites
Before you get started, make sure you have the following prerequisites:
- An AWS account with an AWS Identity and Access Management (IAM) user with permissions to deploy the CloudFormation template
- The AWS Command Line Interface (AWS CLI) installed and configured for use
- Python 3.11 or later
- Amazon Bedrock model access to Anthropic’s Claude 3.5 Sonnet
Deploy the solution
The full code and instructions are available in GitHub in the Readme file.
- Clone the code to your working environment:
git clone https://github.com/aws-samples/aws-field-samples.git
- Move to
ConverseSqlAgentfolder - Follow the steps in the Readme file in the GitHub repo
Cleanup
To dispose of the stack afterwards, invoke the following command:
cdk destroy
Conclusion
The development of robust text-to-SQL capabilities is a critical challenge in natural language processing and database management. Although current approaches have made progress, there remains room for improvement, particularly with complex queries and database structures. The introduction of the ConverseSQLAgent, a custom agent implementation using Amazon Bedrock and Converse API, presents a promising solution to this problem. The agent’s architecture, featuring planning and carry-over, execution and tool use, self-correction through SQLAlchemy, and reflection-based long-term learning, demonstrates its ability to understand natural language queries, develop and execute SQL plans, and continually improve its capabilities. As businesses seek more intuitive ways to access and manage data, solutions such as the ConverseSQLAgent hold the potential to bridge the gap between natural language and structured database queries, unlocking new levels of productivity and data-driven decision-making. To dive deeper and learn more about generative AI, check out these additional resources:
- Amazon Bedrock
- Amazon Bedrock Knowledge Bases
- Generative AI use cases
- Amazon Bedrock Agents
- Carry out a conversation with the Converse API operations
About the authors
 Pavan Kumar is a Solutions Architect at Amazon Web Services (AWS), helping customers design robust, scalable solutions on the cloud across multiple industries. With a background in enterprise architecture and software development, Pavan has contributed to creating solutions to handle API security, API management, microservices, and geospatial information system use cases for his customers. He is passionate about learning new technologies and solving, automating, and simplifying customer problems using these solutions.
Pavan Kumar is a Solutions Architect at Amazon Web Services (AWS), helping customers design robust, scalable solutions on the cloud across multiple industries. With a background in enterprise architecture and software development, Pavan has contributed to creating solutions to handle API security, API management, microservices, and geospatial information system use cases for his customers. He is passionate about learning new technologies and solving, automating, and simplifying customer problems using these solutions.
 Abdullah Siddiqui is a Partner Sales Solutions Architect at Amazon Web Services (AWS) based out of Toronto. He helps AWS Partners and customers build solutions using AWS services and specializes in resilience and migrations. In his spare time, he enjoys spending time with his family and traveling.
Abdullah Siddiqui is a Partner Sales Solutions Architect at Amazon Web Services (AWS) based out of Toronto. He helps AWS Partners and customers build solutions using AWS services and specializes in resilience and migrations. In his spare time, he enjoys spending time with his family and traveling.
 Parag Srivastava is a Solutions Architect at Amazon Web Services (AWS), helping enterprise customers with successful cloud adoption and migration. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.
Parag Srivastava is a Solutions Architect at Amazon Web Services (AWS), helping enterprise customers with successful cloud adoption and migration. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.