This post was co-written with Suzanne Willard and Makoto Uchida from VideoAmp.
In this post, we illustrate how VideoAmp, a media measurement company, worked with the AWS Generative AI Innovation Center (GenAIIC) team to develop a prototype of the VideoAmp Natural Language (NL) Analytics Chatbot to uncover meaningful insights at scale within media analytics data using Amazon Bedrock. The AI-powered analytics solution involved the following components:
- A natural language to SQL pipeline, with a conversational interface, that works with complex queries and media analytics data from VideoAmp
- An automated testing and evaluation tool for the pipeline
VideoAmp background
VideoAmp is a tech-first measurement company that empowers media agencies, brands, and publishers to precisely measure and optimize TV, streaming, and digital media. With a comprehensive suite of measurement, planning, and optimization solutions, VideoAmp offers clients a clear, actionable view of audiences and attribution across environments, enabling them to make smarter media decisions that help them drive better business outcomes. VideoAmp has seen incredible adoption for its measurement and currency solutions with 880% YoY growth, 98% coverage of the TV publisher landscape, 11 agency groups, and more than 1,000 advertisers. VideoAmp is headquartered in Los Angeles and New York with offices across the United States. To learn more, visit www.videoamp.com.
VideoAmp’s AI journey
VideoAmp has embraced AI to enhance its measurement and optimization capabilities. The company has integrated machine learning (ML) algorithms into its infrastructure to analyze vast amounts of viewership data across traditional TV, streaming, and digital services. This AI-driven approach allows VideoAmp to provide more accurate audience insights, improve cross-environment measurement, and optimize advertising campaigns in real time. By using AI, VideoAmp has been able to offer advertisers and media owners more precise targeting, better attribution models, and increased return on investment for their advertising spend. The company’s AI journey has positioned it as a leader in the evolving landscape of data-driven advertising and media measurement.
To take their innovations a step further, VideoAmp is building a brand-new analytics solution powered by generative AI, which will provide their customers with accessible business insights. Their goal for a beta product is to create a conversational AI assistant powered by large language models (LLMs) that allows VideoAmp’s data analysts and non-technical users such as content researchers and publishers to perform data analytics using natural language queries.
Use case overview
VideoAmp is undergoing a transformative journey by integrating generative AI into its analytics. The company aims to revolutionize how customers, including publishers, media agencies, and brands, interact with and derive insights from VideoAmp’s vast repository of data through a conversational AI assistant interface.
Presently, analysis by data scientists and analysts is done manually, requires technical SQL knowledge, and can be time-consuming for complex and high-dimensional datasets. Acknowledging the necessity for streamlined and accessible processes, VideoAmp worked with the GenAIIC to develop an AI assistant capable of comprehending natural language queries, generating and executing SQL queries on VideoAmp’s data warehouse, and delivering natural language summaries of retrieved information. The assistant allows non-technical users to surface data-driven insights, and it reduces research and analysis time for both technical and non-technical users.
Key success criteria for the project included:
- The ability to convert natural language questions into SQL statements, connect to VideoAmp’s provided database, execute statements on VideoAmp performance metrics data, and create a natural language summary of results
- A UI to ask natural language questions and view assistant output, which includes generated SQL queries, reasoning for the SQL statements, retrieved data, and natural language data summaries
- Conversational support for the user to iteratively refine and filter asked questions
- Low latency and cost-effectiveness
- An automated evaluation pipeline to assess the quality and accuracy of the assistant
The team overcame a few challenges during the development process:
- Adapting LLMs to understand the domain aspects of VideoAmp’s dataset – The dataset included highly industry-specific fields and metrics, and required complex queries to effectively filter and analyze. The queries often involved multiple specialized metric calculations, filters selecting from over 30 values, and extensive grouping and ordering.
- Developing an automated evaluation pipeline – The pipeline is able to correctly identify if generated outputs are equivalent to ground truth data, even if they have different column aliasing, ordering, and metric calculations.
Solution overview
The GenAIIC team worked with VideoAmp to create an AI assistant that used Anthropic’s Claude 3 LLMs through Amazon Bedrock. Amazon Bedrock was chosen for this project because it provides access to high-quality foundation models (FMs), including Anthropic’s Claude 3 series, through a unified API. This allowed the team to quickly integrate the most suitable models for different components of the solution, such as SQL generation and data summarization.
Additional features in Amazon Bedrock, including Amazon Bedrock Prompt Management, native support for Retrieval Augmented Generation (RAG) and structured data retrieval through Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, and fine-tuning, enable VideoAmp to quickly expand the analytics solution and take it to production. Amazon Bedrock also offers robust security and adheres to compliance certifications, allowing VideoAmp to confidently expand their AI analytics solution while maintaining data privacy and adhering to industry standards.
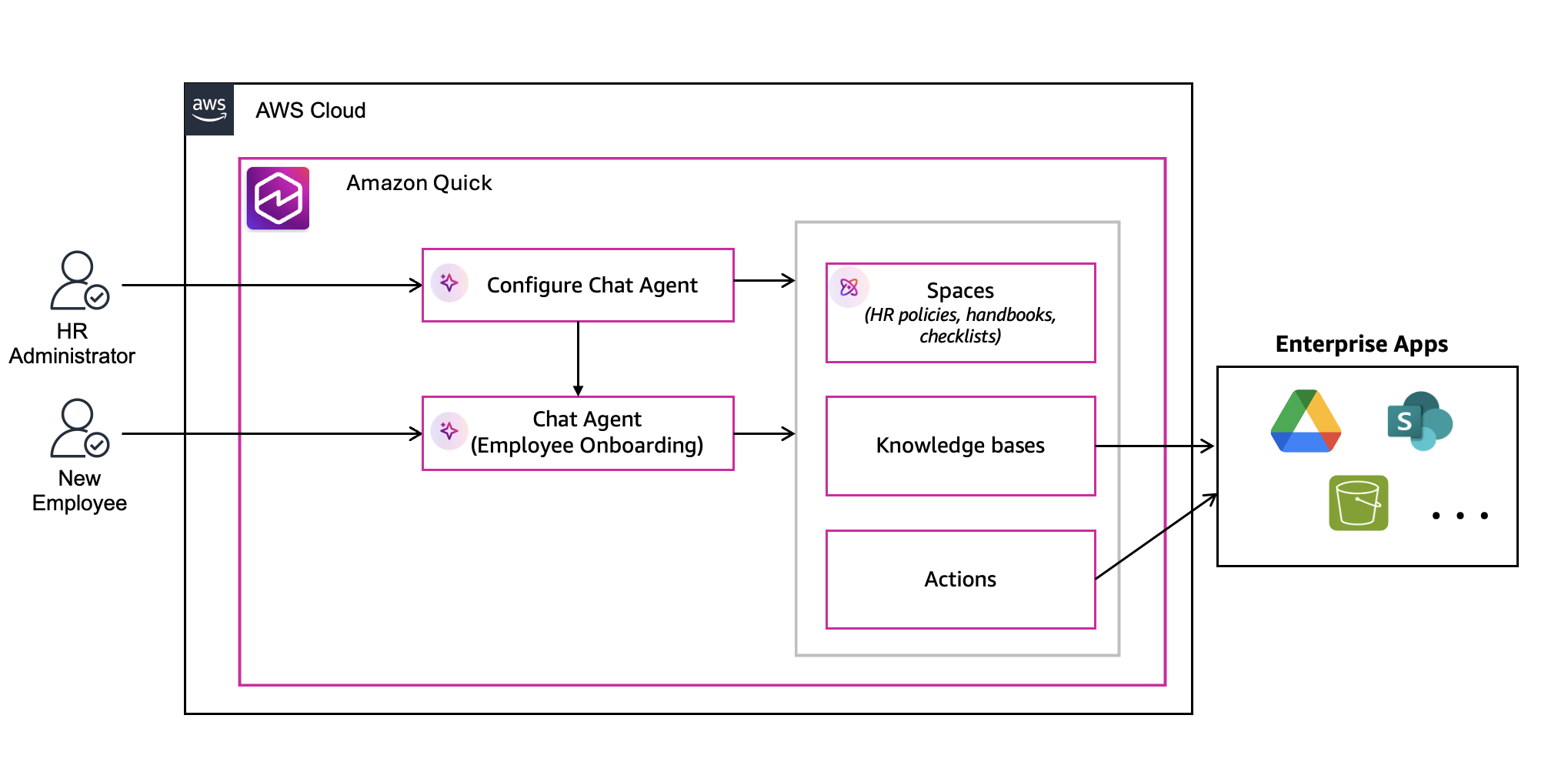
The solution is connected to a data warehouse. It supports a variety of database connections, such as Snowflake, SingleStore, PostgreSQL, Excel and CSV files, and more. The following diagram illustrates the high-level workflow of the solution.

The workflow consists of the following steps:
- The user navigates to the frontend application and asks a question in natural language.
- A Question Rewriter LLM component uses previous conversational context to augment the question with additional details if applicable. This allows follow-up questions and refinements to previous questions.
- A Text-to-SQL LLM component creates a SQL query that corresponds to the user question.
- The SQL query is executed in the data warehouse.
- A Data-to-Text LLM component summarizes the retrieved data for the user.
The rewritten question, generated SQL, reasoning, and retrieved data are returned at each step.
AI assistant workflow details
In this section, we discuss the components of the AI assistant workflow in more detail.
Rewriter
After the user asks the question, the current question and the previous questions the user asked in the current session are sent to the Question Rewriter component, which uses Anthropic’s Claude 3 Sonnet model. If deemed necessary, the LLM uses context from the previous questions to augment the current user question to make it a standalone question with context included. This enables multi-turn conversational support for the user, allowing for natural interactions with the assistant.
For example, if a user first asked, “For the week of 09/04/2023 – 09/10/2023, what were the top 10 ranked original national broadcast shows based on viewership for households with 18+?”, followed by, “Can I have the same data for one year later”, the rewriter would rewrite the latter question as “For the week of 09/03/2024 – 09/09/2024, what were the top 10 ranked original national broadcast shows based on viewership for households with 18+?”
Text-to-SQL
The rewritten user question is sent to the Text-to-SQL component, which also uses Anthropic’s Claude 3 Sonnet model. The Text-to-SQL component uses information about the database in its prompt to generate a SQL query corresponding to the user question. It also generates an explanation of the query.
The text-to-SQL prompt addressed several challenges, such as industry-specific language in user questions, complex metrics, and several rules and defaults for filtering. The prompt was developed through several iterations, based on feedback and guidance from the VideoAmp team, and manual and automated evaluation.
The prompt consisted of four overarching sections: context, SQL instructions, task, and examples. During the development phase, database schema and domain- or task-specific knowledge were found to be critical, so one major part of the prompt was designed to incorporate them in the context. To make this solution reusable and scalable, a modularized design of the prompt/input system is employed, making it generic so it can be applied to other use cases and domains. The solution can support Q&A with multiple databases by dynamically switching/changing the corresponding context with an orchestrator if needed.
The context section contains the following details:
- Database schema
- Sample categories for relevant data fields such as television networks to aid the LLM in understanding what fields to use for identifiers in the question
- Industry term definitions
- How to calculate different types of metrics or aggregations
- Default values or fields should be selected if not specified
- Other domain- or task-specific knowledge
The SQL instructions contain the following details:
- Dynamic insertion of today’s date as a reference for terms, such as “last 3 quarters”
- Instructions on usage of sub-queries
- Instructions on when to retrieve additional informational columns not specified in the user question
- Known SQL syntax and database errors to avoid and potential fixes
In the task section, the LLM is given a detailed step-by-step process to formulate SQL queries based on the context. A step-by-step process is required for the LLM to correctly think through and assimilate the required context and rules. Without the step-by-step process, the team found that the LLM wouldn’t adhere to all instructions provided in the previous sections.
In the examples section, the LLM is given several examples of user questions, corresponding SQL statements, and explanations.
In addition to iterating on the prompt content, different content organization patterns were tested due to long context. The final prompt was organized with markdown and XML.
SQL execution
After the Text-to-SQL component outputs a query, the query is executed against VideoAmp’s data warehouse using database connector code. For this use case, only read queries for analytics are executed to protect the database from unexpected operations like updates or deletes. The credentials for the database are securely stored and accessed using AWS Secrets Manager and AWS Key Management Service (AWS KMS).
Data-to-Text
The data retrieved by the SQL query is sent to the Data-to-Text component, along with the rewritten user question. The Data-to-Text component, which uses Anthropic’s Claude 3 Haiku model, produces a concise summary of the retrieved data and answers the user question.
The final outputs are displayed on the frontend application as shown in the following screenshots (protected data is hidden).


Evaluation framework workflow details
The GenAIIC team developed a sophisticated automated evaluation pipeline for VideoAmp’s NL Analytics Chatbot, which directly informed prompt optimization and solution improvements and was a critical component in providing high-quality results.
The evaluation framework comprises of two categories:
- SQL query evaluation – Generated SQL queries are evaluated for overall closeness to the ground truth SQL query. A key feature of the SQL evaluation component was the ability to account for column aliasing and ordering differences when comparing statements and determine equivalency.
- Retrieved data evaluation – The retrieved data is compared to ground truth data to determine an exact match, after a few processing steps to account for column, formatting, and system differences.
The evaluation pipeline also produces detailed reports of the results and discrepancies between generated data and ground truth data.
Dataset
The dataset used for the prototype solution was hosted in a data warehouse and consisted of performance metrics data such as viewership, ratings, and rankings for television networks and programs. The field names were industry-specific, so a data dictionary was included in the text-to-SQL prompt as part of the schema. The credentials for the database are securely stored and accessed using Secrets Manager and AWS KMS.
Results
A set of test questions were evaluated by the GenAIIC and VideoAmp teams, focusing on three metrics:
- Accuracy – Different accuracy metrics were analyzed, but exact matches between retrieved data and ground truth data were prioritized
- Latency – LLM generation latency, excluding the time taken to query the database
- Cost – Average cost per user question
Both the evaluation pipeline and human review reported high accuracies on the dataset, whereas costs and latencies remained low. Overall, the results were well-aligned with VideoAmp expectations. VideoAmp anticipates this solution will make it simple for users to handle complex data queries with confidence through intuitive natural language interactions, reducing the time to business insights.
Conclusion
In this post, we shared how the GenAIIC team worked with VideoAmp to build a prototype of the VideoAmp NL Analytics Chatbot, an end-to-end generative AI data analytics interface using Amazon Bedrock and Anthropic’s Claude 3 LLMs. The solution is equipped with a variety of state-of-the-art LLM-based techniques, such as question rewriting, text-to-SQL query generation, and summarization of data in natural language. It also includes an automated evaluation module for evaluating the correctness of generated SQL statements and retrieved data. The solution achieved high accuracy on VideoAmp’s evaluation samples. Users can interact with the solution through an intuitive AI assistant interface with conversational capabilities.
VideoAmp will soon be launching their new generative AI-powered analytics interface, which enables customers to analyze data and gain business insights through natural language conversation. Their successful work with the GenAIIC team will allow VideoAmp to use generative AI technology to swiftly deliver valuable insights for both technical and non-technical customers.
This is just one of the ways AWS enables builders to deliver generative AI-based solutions. You can get started with Amazon Bedrock and see how it can be integrated in example code bases. The GenAIIC is a group of science and strategy experts with comprehensive expertise spanning the generative AI journey, helping you prioritize use cases, build a roadmap, and move solutions into production. If you’re interested in working with the GenAIIC, reach out to them today.
About the authors
 Suzanne Willard is the VP of Engineering at VideoAmp where she founded and leads the GenAI program, establishing the strategic vision and execution roadmap. With over 20 years experience she is driving innovation in AI technologies, creating transformative solutions that align with business objectives and set the company apart in the market.
Suzanne Willard is the VP of Engineering at VideoAmp where she founded and leads the GenAI program, establishing the strategic vision and execution roadmap. With over 20 years experience she is driving innovation in AI technologies, creating transformative solutions that align with business objectives and set the company apart in the market.
 Makoto Uchida is a senior architect at VideoAmp in the AI domain, acting as area technical lead of AI portfolio, responsible for defining and driving AI product and technical strategy in the content and ads measurement platform PaaS product. Previously, he was a software engineering lead in generative and predictive AI Platform at a major hyperscaler public Cloud service. He has also engaged with multiple startups, laying the foundation of Data/ML/AI infrastructures.
Makoto Uchida is a senior architect at VideoAmp in the AI domain, acting as area technical lead of AI portfolio, responsible for defining and driving AI product and technical strategy in the content and ads measurement platform PaaS product. Previously, he was a software engineering lead in generative and predictive AI Platform at a major hyperscaler public Cloud service. He has also engaged with multiple startups, laying the foundation of Data/ML/AI infrastructures.
 Shreya Mohanty is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she partners with customers across industries to design and implement high-impact GenAI-powered solutions. She specializes in translating customer goals into tangible outcomes that drive measurable impact.
Shreya Mohanty is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she partners with customers across industries to design and implement high-impact GenAI-powered solutions. She specializes in translating customer goals into tangible outcomes that drive measurable impact.
 Long Chen is a Sr. Applied Scientist at AWS Generative AI Innovation Center. He holds a Ph.D. in Applied Physics from University of Michigan – Ann Arbor. With more than a decade of experience for research and development, he works on innovative solutions in various domains using generative AI and other machine learning techniques, ensuring the success of AWS customers. His interest includes generative models, multi-modal systems and graph learning.
Long Chen is a Sr. Applied Scientist at AWS Generative AI Innovation Center. He holds a Ph.D. in Applied Physics from University of Michigan – Ann Arbor. With more than a decade of experience for research and development, he works on innovative solutions in various domains using generative AI and other machine learning techniques, ensuring the success of AWS customers. His interest includes generative models, multi-modal systems and graph learning.
 Amaran Asokkumar is a Deep Learning Architect at AWS, specializing in infrastructure, automation, and AI. He leads the design of GenAI-enabled solutions across industry segments. Amaran is passionate about all things AI and helping customers accelerate their GenAI exploration and transformation efforts.
Amaran Asokkumar is a Deep Learning Architect at AWS, specializing in infrastructure, automation, and AI. He leads the design of GenAI-enabled solutions across industry segments. Amaran is passionate about all things AI and helping customers accelerate their GenAI exploration and transformation efforts.
 Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.