We’ve witnessed remarkable advances in model capabilities as generative AI companies have invested in developing their offerings. Language models such as Anthropic’s Claude Opus 4 & Sonnet 4, Amazon Nova, and Amazon Bedrock can reason, write, and generate responses with increasing sophistication. But even as these models grow more powerful, they can only work with the information available to them.
No matter how impressive a model might be, it’s confined to the data it was trained on or what’s manually provided in its context window. It’s like having the world’s best analyst locked in a room with incomplete files—brilliant, but isolated from your organization’s most current and relevant information.
This isolation creates three critical challenges for enterprises using generative AI:
- Information silos trap valuable data behind custom APIs and proprietary interfaces
- Integration complexity requires building and maintaining bespoke connectors and glue code for every data source or tool provided to the language model for every data source
- Scalability bottlenecks appear as organizations attempt to connect more models to more systems and tools
Sound familiar? If you’re an AI-focused developer, technical decision-maker, or solution architect working with Amazon Web Services (AWS) and language models, you’ve likely encountered these obstacles firsthand. Let’s explore how the Model Context Protocol (MCP) offers a path forward.
What is the MCP?
The MCP is an open standard that creates a universal language for AI systems to communicate with external data sources, tools, and services. Conceptually, MCP functions as a universal translator, enabling seamless dialogue between language models and the diverse systems where your valuable information resides.
Developed by Anthropic and released as an open source project, MCP addresses a fundamental challenge: how to provide AI models with consistent, secure access to the information they need, when they need it, regardless of where that information lives.

At its core, MCP implements a client-server architecture:
- MCP clients are AI applications like Anthropic’s Claude Desktop or custom solutions built on Amazon Bedrock that need access to external data
- MCP servers provide standardized access to specific data sources, whether that’s a GitHub repository, Slack workspace, or AWS service
- Communication flow between clients and servers follows a well-defined protocol that can run locally or remotely
This architecture supports three essential primitives that form the foundation of MCP:
- Tools – Functions that models can call to retrieve information or perform actions
- Resources – Data that can be included in the model’s context such as database records, images, or file contents
- Prompts – Templates that guide how models interact with specific tools or resources
What makes MCP especially powerful is its ability to work across both local and remote implementations. You can run MCP servers directly on your development machine for testing or deploy them as distributed services across your AWS infrastructure for enterprise-scale applications.
Solving the M×N integration problem
Before diving deeper into the AWS specific implementation details, it’s worth understanding the fundamental integration challenge MCP solves.
Imagine you’re building AI applications that need to access multiple data sources in your organization. Without a standardized protocol, you face what we call the “M×N problem”: for M different AI applications connecting to N different data sources, you need to build and maintain M×N custom integrations.
This creates an integration matrix that quickly becomes unmanageable as your organization adds more AI applications and data sources. Each new system requires multiple custom integrations, with development teams duplicating efforts across projects. MCP transforms this M×N problem into a simpler M+N equation: with MCP, you build M clients and N servers, requiring only M+N implementations. These solutions to the MCP problem are shown in the following diagram.

This approach draws inspiration from other successful protocols that solved similar challenges:
- APIs standardized how web applications interact with the backend
- Language Server Protocol (LSP) standardizes how integrated development environments (IDEs) interact with language-specific tools for coding
In the same way that these protocols revolutionized their domains, MCP is poised to transform how AI applications interact with the diverse landscape of data sources in modern enterprises.
Why MCP matters for AWS users
For AWS customers, MCP represents a particularly compelling opportunity. AWS offers hundreds of services, each with its own APIs and data formats. By adopting MCP as a standardized protocol for AI interactions, you can:
- Streamline integration between Amazon Bedrock language models and AWS data services
- Use existing AWS security mechanisms such as AWS Identity and Access Management (IAM) for consistent access control
- Build composable, scalable AI solutions that align with AWS architectural best practices
MCP and the AWS service landscape
What makes MCP particularly powerful in the AWS context is how it can interface with the broader AWS service landscape. Imagine AI applications that can seamlessly access information from:
- Amazon Simple Storage (Amazon S3) buckets containing documents, images, and unstructured data
- Amazon DynamoDB tables storing structured business information
- Amazon Relational Database Service (Amazon RDS) databases with historical transaction records
- Amazon CloudWatch logs for operational intelligence
- Amazon Bedrock Knowledge Bases for semantic search capabilities
MCP servers act as consistent interfaces to these diverse data sources, providing language models with a unified access pattern regardless of the underlying AWS service architecture. This alleviates the need for custom integration code for each service and enables AI systems to work with your AWS resources in a way that respects your existing security boundaries and access controls.
In the remaining sections of this post, we explore how MCP works with AWS services, examine specific implementation examples, and provide guidance for technical decision-makers considering adopt MCP in their organizations.
How MCP works with AWS services, particularly Amazon Bedrock
Now that we’ve shown the fundamental value proposition of MCP, we dive into how it integrates with AWS services, with a special focus on Amazon Bedrock. This integration creates a powerful foundation for building context-aware AI applications that can securely access your organization’s data and tools.
Amazon Bedrock and language models
Amazon Bedrock represents the strategic commitment by AWS to make foundation models (FMs) accessible, secure, and enterprise-ready. It’s a fully managed service that provides a unified API across multiple leading language models, including:
- Anthropic’s Claude
- Meta’s Llama
- Amazon Titan and Amazon Nova
What makes Amazon Bedrock particularly compelling for enterprise deployments is its integration with the broader AWS landscape. You can run FMs with the same security, compliance, and operational tools you already use for your AWS workloads. This includes IAM for access control and CloudWatch for monitoring.
At the heart of the versatility of Amazon Bedrock is the Converse API—the interface that enables multiturn conversations with language models. The Converse API includes built-in support for what AWS calls “tool use,” allowing models to:
- Recognize when they need information outside their training data
- Request that information from external systems using well-defined function calls
- Incorporate the returned data into their responses
This tool use capability in the Amazon Bedrock Converse API dovetails perfectly with MCP’s design, creating a natural integration point.
MCP and Amazon Bedrock integration architecture
Integrating MCP with Amazon Bedrock involves creating a bridge between the model’s ability to request information (through the Converse API) and MCP’s standardized protocol for accessing external systems.
Integration flow walkthrough
To help you understand how MCP and Amazon Bedrock work together in practice, we walk through a typical interaction flow, step-by-step:
- The user initiates a query through your application interface:
"What were our Q1 sales figures for the Northwest region?"
- Your application forwards the query to Amazon Bedrock through the Converse API:
- Amazon Bedrock processes the query and determines that it needs financial data that isn’t in its training data
- Amazon Bedrock returns a
toolUsemessage, requesting access to a specific tool:
- Your MCP client application receives this
toolUsemessage and translates it into an MCP protocol
tool call - The MCP client routes the request to the appropriate MCP server (in this case, a server connected to your
financial database) - The MCP server executes the tool, retrieving the requested data from your systems:
- The tool results are returned through the MCP protocol to your client application
- Your application sends the results back to Amazon Bedrock as a
toolResultmessage:
- Amazon Bedrock generates a final response incorporating the tool results:
- Your application returns the final response to the user
This entire process, illustrated in the following diagram, happens in seconds, giving users the impression of a seamless conversation with an AI that has direct access to their organization’s data. Behind the scenes, MCP is handling the complex work of securely routing requests to the right tools and data sources.

In the next section, we explore a practical implementation example that shows how to connect an MCP server to Amazon Bedrock Knowledge Bases, providing a blueprint for your own implementations.
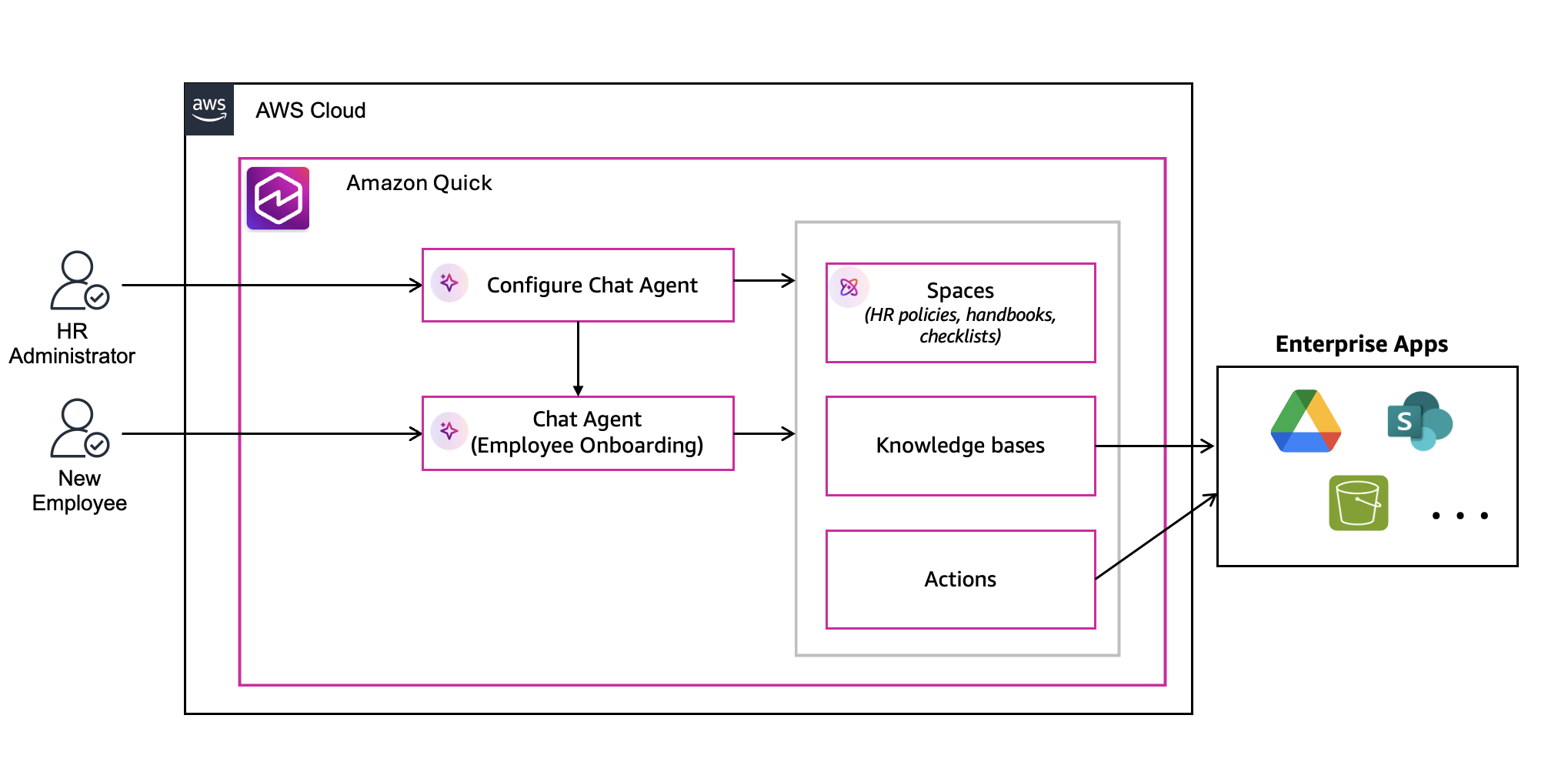
Practical implementation example: Amazon Bedrock Knowledge Bases integration
As you might recall from our earlier discussion of strategic use cases, enterprise knowledge bases represent one of the most valuable applications of MCP on AWS. Now, we explore a concrete implementation of MCP that connects language models to Amazon Bedrock Knowledge Bases. The code for the MCP server can be found in the AWS Labs MCP code repository and for the client in the same AWS Labs MCP samples directory on GitHub. This example brings to life the “universal translator” concept we introduced earlier, demonstrating how MCP can transform the way AI systems interact with enterprise knowledge repositories.
Understanding the challenge
Enterprise knowledge bases contain vast repositories of information—from documentation and policies to technical guides and product specifications. Traditional search approaches are often inadequate when users ask natural language questions, failing to understand context or identify the most relevant content.
Amazon Bedrock Knowledge Bases provide vector search capabilities that improve upon traditional keyword search, but even this approach has limitations:
- Manual filter configuration requires predefined knowledge of metadata structures
- Query-result mismatch occurs when users don’t use the exact terminology in the knowledge base
- Relevance challenges arise when similar documents compete for attention
- Context switching between searching and reasoning disrupts user experience
The MCP server we explore addresses these challenges by creating an intelligent layer between language models and knowledge bases.
Architecture overview
At a high level, our MCP server for Amazon Bedrock Knowledge Bases follows a clean, well-organized architecture that builds upon the client-server pattern we outlined previously. The server exposes two key interfaces to language models:
- A knowledge bases resource that provides discovery capabilities for available knowledge bases
- A query tool that enables dynamic searching across these knowledge bases

Remember the M×N integration problem we discussed earlier? This implementation provides a tangible example of how MCP solves it – creating a standardized interface between a large language model and your Amazon Bedrock Knowledge Base repositories.
Knowledge base discovery resource
The server begins with a resource that enables language models to discover available knowledge bases:
This resource serves as both documentation and a discovery mechanism that language models can use to identify available knowledge bases before querying them.
Querying knowledge bases with the MCP tool
The core functionality of this MCP server resides in its QueryKnowledgeBases tool:
What makes this tool powerful is its flexibility in querying knowledge bases with natural language. It supports several key features:
- Configurable result sizes – Adjust the number of results based on whether you need focused or comprehensive information
- Optional reranking – Improve relevance using language models (such as reranking models from Amazon or Cohere)
- Data source filtering – Target specific sections of the knowledge base when needed
Reranking is disabled by default in this implementation but can be quickly enabled through environment variables or direct parameter configuration.
Enhanced relevance with reranking
A notable feature of this implementation is the ability to rerank search results using language models available through Amazon Bedrock. This capability allows the system to rescore search results based on deeper semantic understanding:
Reranking is particularly valuable for queries where semantic similarity might not be enough to determine the
most relevant content. For example, when answering a specific question, the most relevant document isn’t necessarily
the one with the most keyword matches, but the one that directly addresses the question being asked.
Full interaction flow
This section walks through a complete interaction flow to show how all these components work
together:
- The user asks a question to a language model such as Anthropic’s Claude through an application:
- The language model recognizes it needs to access the knowledge base and calls the MCP tool:
- The MCP server processes the request by querying the knowledge base with the specified parameters
- The MCP server returns formatted results to the language model, including content, location, and relevance scores:
- The language model incorporates these results into its response to the user:
This interaction, illustrated in the following diagram, demonstrates the seamless fusion of language model capabilities with enterprise knowledge, enabled by the MCP protocol. The user doesn’t need to specify complex search parameters or know the structure of the knowledge base—the integration layer handles these details automatically.

Looking ahead: The MCP journey continues
As we’ve explored throughout this post, the Model Context Protocol provides a powerful framework for connecting language models to your enterprise data and tools on AWS. But this is just the beginning of the journey.
The MCP landscape is rapidly evolving, with new capabilities and implementations emerging regularly. In future posts in this series, we’ll dive deeper into advanced MCP architectures and use cases, with a particular focus on remote MCP implementation.
The introduction of the new Streamable HTTP transport layer represents a significant advancement for MCP, enabling truly enterprise-scale deployments with features such as:
- Stateless server options for simplified scaling
- Session ID management for request routing
- Robust authentication and authorization mechanisms for secure access control
- Horizontal scaling across server nodes
- Enhanced resilience and fault tolerance
These capabilities will be essential as organizations move from proof-of-concept implementations to production-grade MCP deployments that serve multiple teams and use cases.
We invite you to follow this blog post series as we continue to explore how MCP and AWS services can work together to create more powerful, context-aware AI applications for your organization.
Conclusion
As language models continue to transform how we interact with technology, the ability to connect these models to enterprise data and systems becomes increasingly critical. The Model Context Protocol (MCP) offers a standardized, secure, and scalable approach to integration.
Through MCP, AWS customers can:
- Establish a standardized protocol for AI-data connections
- Reduce development overhead and maintenance costs
- Enforce consistent security and governance policies
- Create more powerful, context-aware AI experiences
The Amazon Bedrock Knowledge Bases implementation we explored demonstrates how MCP can transform simple retrieval into intelligent discovery, adding value far beyond what either component could deliver independently.
Getting started
Ready to begin your MCP journey on AWS? Here are some resources to help you get started:
Learning resources:
- AWS Labs MCP client and server code repository
- Model Context Protocol documentation
- Amazon Bedrock Developer Guide
- MCP servers repository
Implementation steps:
- Identify a high-value use case where AI needs access to enterprise data
- Select the appropriate MCP servers for your data sources
- Set up a development environment with local MCP implementations
- Integrate with Amazon Bedrock using the patterns described in this post
- Deploy to production with appropriate security and scaling considerations
Remember that MCP offers a “start small, scale incrementally” approach. You can begin with a single server connecting to one data source, then expand your implementation as you validate the value and establish patterns for your organization.
We encourage you to try the MCP with AWS services today. Start with a simple implementation, perhaps connecting a language model to your documentation or code repositories, and experience firsthand the power of context-aware AI.
Share your experiences, challenges, and successes with the community. The open source nature of MCP means that your contributions—whether code, use cases, or feedback—can help shape the future of this important protocol.
In a world where AI capabilities are advancing rapidly, the difference between good and great implementations often comes down to context. With MCP and AWS, you have the tools to make sure your AI systems have the right context at the right time, unlocking their full potential for your organization.
This blog post is part of a series exploring the Model Context Protocol (MCP) on AWS. In our next installment, we’ll explore the world of agentic AI, demonstrating how to build autonomous agents using the open-source Strands Agents SDK with MCP to create intelligent systems that can reason, plan, and execute complex multi-step workflows. We’ll also explore advanced implementation patterns, remote MCP architectures, and discover additional use cases for MCP.
About the authors
 Aditya Addepalli is a Delivery Consultant at AWS, where he works to lead, architect, and build applications directly with customers. With a strong passion for Applied AI, he builds bespoke solutions and contributes to the ecosystem while consistently keeping himself at the edge of technology. Outside of work, you can find him meeting new people, working out, playing video games and basketball, or feeding his curiosity through personal projects.
Aditya Addepalli is a Delivery Consultant at AWS, where he works to lead, architect, and build applications directly with customers. With a strong passion for Applied AI, he builds bespoke solutions and contributes to the ecosystem while consistently keeping himself at the edge of technology. Outside of work, you can find him meeting new people, working out, playing video games and basketball, or feeding his curiosity through personal projects.
 Elie Schoppik leads live education at Anthropic as their Head of Technical Training. He has spent over a decade in technical education, working with multiple coding schools and starting one of his own. With a background in consulting, education, and software engineering, Elie brings a practical approach to teaching Software Engineering and AI. He’s shared his insights at a variety of technical conferences as well as universities including MIT, Columbia, Wharton, and UC Berkeley.
Elie Schoppik leads live education at Anthropic as their Head of Technical Training. He has spent over a decade in technical education, working with multiple coding schools and starting one of his own. With a background in consulting, education, and software engineering, Elie brings a practical approach to teaching Software Engineering and AI. He’s shared his insights at a variety of technical conferences as well as universities including MIT, Columbia, Wharton, and UC Berkeley.
 Jawhny Cooke is a Senior Anthropic Specialist Solutions Architect for Generative AI at AWS. He specializes in integrating and deploying Anthropic models on AWS infrastructure. He partners with customers and AI providers to implement production-grade generative AI solutions through Amazon Bedrock, offering expert guidance on architecture design and system implementation to maximize the potential of these advanced models.
Jawhny Cooke is a Senior Anthropic Specialist Solutions Architect for Generative AI at AWS. He specializes in integrating and deploying Anthropic models on AWS infrastructure. He partners with customers and AI providers to implement production-grade generative AI solutions through Amazon Bedrock, offering expert guidance on architecture design and system implementation to maximize the potential of these advanced models.
 Kenton Blacutt is an AI Consultant within the GenAI Innovation Center. He works hands-on with customers helping them solve real-world business problems with cutting edge AWS technologies, especially Amazon Q and Bedrock. In his free time, he likes to travel, experiment with new AI techniques, and run an occasional marathon.
Kenton Blacutt is an AI Consultant within the GenAI Innovation Center. He works hands-on with customers helping them solve real-world business problems with cutting edge AWS technologies, especially Amazon Q and Bedrock. In his free time, he likes to travel, experiment with new AI techniques, and run an occasional marathon.
 Mani Khanuja is a Principal Generative AI Specialist Solutions Architect, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Principal Generative AI Specialist Solutions Architect, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
 Nicolai van der Smagt is a Senior Specialist Solutions Architect for Generative AI at AWS, focusing on third-party model integration and deployment. He collaborates with AWS’ biggest AI partners to bring their models to Amazon Bedrock, while helping customers architect and implement production-ready generative AI solutions with these models.
Nicolai van der Smagt is a Senior Specialist Solutions Architect for Generative AI at AWS, focusing on third-party model integration and deployment. He collaborates with AWS’ biggest AI partners to bring their models to Amazon Bedrock, while helping customers architect and implement production-ready generative AI solutions with these models.