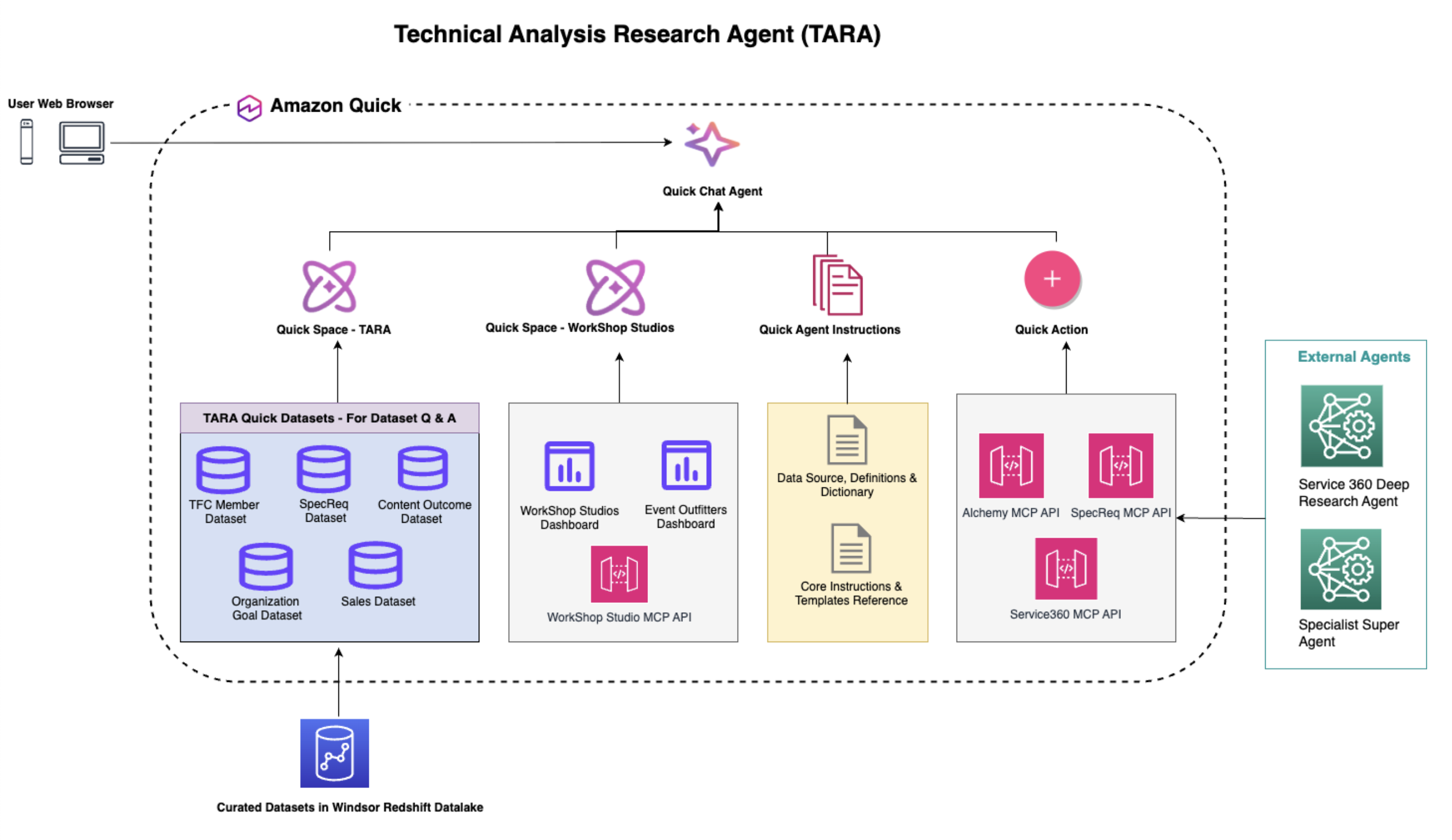
Amazon Bedrock Knowledge Bases offers a fully managed Retrieval Augmented Generation (RAG) feature that connects large language models (LLMs) to internal data sources. It’s a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts. It also provides developers with greater control over the LLM’s outputs, including the ability to include citations and manage sensitive information.
Amazon Bedrock Knowledge Bases has a metadata filtering capability that allows you to refine search results based on specific attributes of the documents, improving retrieval accuracy and the relevance of responses. These metadata filters can be used in combination with the typical semantic (or hybrid) similarity search. Improving document retrieval results helps personalize the responses generated for each user. Dynamic metadata filters allow you to instantly create custom queries based on the varying user profiles or user-inputted responses so the documents retrieved only contain information relevant to the your needs.
In this post, we discuss using metadata filters with Amazon Bedrock Knowledge Bases.
Solution overview
The following code is an example metadata filter for Amazon Bedrock Knowledge Bases. Logical operators (such as AND or OR) can be nested to combine other logical operators and filter conditions. For more information, refer to the Retrieve API.
For our use case, we use an example of a travel website where the user answers a few questions about their travel preferences (including desired destination, preferred activities, and traveling companions) and then the system retrieves relevant documents.
We exclusively focus on the retrieval portion of RAG in this post. We provide the upstream components, including document ingestion and query formatting, as static data instead of code. The downstream generation component is out of scope for this post.
Prerequisites
To follow along with this post, you should understand basic retrieval techniques such as similarity search.
Additionally, you need an Amazon Bedrock knowledge base populated with documents and metadata. For instructions, see Create an Amazon Bedrock knowledge base. We have provided example documents and metadata in the accompanying GitHub repo for you to upload.
The associated notebook contains the required library imports and environment variables. Make sure you run the notebook using an AWS Identity and Access Management (IAM) role with the correct permissions for Amazon Simple Storage Service (Amazon S3) and Amazon Bedrock (AmazonS3FullAccess and AmazonBedrockFullAccess, respectively). We recommend running the notebook locally or in Amazon SageMaker. Then you can run the following code to test your AWS and knowledge base connection:
Create a dynamic filter
The “value” field within the filter needs to be updated at request time. This means overwriting the retrieval_config object, as shown in the following figure. The placeholder values in the filter get overwritten with the user data at runtime.
Because the retrieval_config object is a nested hierarchy of logical conditions (a tree), you can implement a breadth first search to identify and replace all the “value” field values (where “value” is the key and “<UNKNOWN>” is the placeholder value) with the corresponding value from the user data. See the following code:
Option 1: Create a retriever each time
To define the retrieval_config parameter dynamically, you can instantiate AmazonKnowledgeBasesRetriever each time. This integrates into a larger LangChain centric code base. See the following code:
Option 2: Access the underlying Boto3 API
The Boto3 API is able to directly retrieve with a dynamic retrieval_config. You can take advantage of this by accessing the object that AmazonKnowledgeBasesRetriever wraps. This is slightly faster but is less pythonic because it relies on LangChain implementation details, which may change without notice. This requires additional code to adapt the output to the proper format for a LangChain retriever. See the following code:
Results
Begin by reading in the user data. This example data contains user answers to an online questionnaire about travel preferences. The user_data fields must match the metadata fields.
Here is a preview of the user_data.json file from which certain fields will be extracted as values for filters.
Test the code with filters turned on and off. Only use a few filtering criteria because restrictive filters might return zero documents.
Finally, run both retrieval chains through both sets of filters for each user:
When analyzing the results, you can see that the first half of the documents are identical to the second half. In addition, when metadata filters aren’t used, the documents retrieved are occasionally for the wrong location. For example, trip ID 2 is to Paris, but the retriever pulls documents about London.
Excerpt of output table for reference:
Retrieval Approach
Filter
Trip ID
Destination
Page Content
Metadata
Option_0
TRUE
2
Paris, France
As a 70-year-old retiree, I recently had the pleasure of visiting Paris for the first time. It was a trip I had been looking forward to for years, and I was not disappointed. Here are some of my favorite attractions and activities that I would recommend to other seniors visiting the city. First on my list is the Eiffel Tower…
{‘location’: {‘s3Location’: {‘uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/Paris_6.txt‘}, ‘type’: ‘S3’}, ‘score’: 0.48863396, ‘source_metadata’: {‘x-amz-bedrock-kb-source-uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/Paris_6.txt‘, ‘travelling_with_children’: ‘no’, ‘activities_interest’: [‘museums’, ‘palaces’, ‘strolling’, ‘boat tours’, ‘neighborhood tours’], ‘companion’: ‘unknown’, ‘x-amz-bedrock-kb-data-source-id’: {YOUR_KNOWLEDGE_BASE_ID}, ‘stay_duration’: ‘unknown’, ‘preferred_month’: [‘unknown’], ‘travelling_with_pets’: ‘unknown’, ‘age’: [’71’, ’80’], ‘x-amz-bedrock-kb-chunk-id’: ‘1%3A0%3AiNKlapMBdxcT3sYpRK-d’, ‘desired_destination’: ‘Paris, France’}}
Option_0
TRUE
2
Paris, France
As a 35-year-old traveling with my two dogs, I found Paris to be a pet-friendly city with plenty of attractions and activities for pet owners. Here are some of my top recommendations for traveling with pets in Paris: The Jardin des Tuileries is a beautiful park located between the Louvre Museum and the Place de la Concorde…
{‘location’: {‘s3Location’: {‘uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/Paris_9.txt‘}, ‘type’: ‘S3’}, ‘score’: 0.474106, ‘source_metadata’: {‘x-amz-bedrock-kb-source-uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/Paris_9.txt‘, ‘travelling_with_children’: ‘no’, ‘activities_interest’: [‘parks’, ‘museums’, ‘river cruises’, ‘neighborhood exploration’], ‘companion’: ‘pets’, ‘x-amz-bedrock-kb-data-source-id’: {YOUR_KNOWLEDGE_BASE_ID}, ‘stay_duration’: ‘unknown’, ‘preferred_month’: [‘unknown’], ‘travelling_with_pets’: ‘yes’, ‘age’: [’30’, ’31’, ’32’, ’33’, ’34’, ’35’, ’36’, ’37’, ’38’, ’39’, ’40’], ‘x-amz-bedrock-kb-chunk-id’: ‘1%3A0%3Aj52lapMBuHB13c7-hl-4’, ‘desired_destination’: ‘Paris, France’}}
Option_0
TRUE
2
Paris, France
If you are looking for something a little more active, I would suggest visiting the Bois de Boulogne. This large park is located on the western edge of Paris and is a great place to go for a walk or a bike ride with your pet. The park has several lakes and ponds, as well as several gardens and playgrounds…
{‘location’: {‘s3Location’: {‘uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/Paris_5.txt‘}, ‘type’: ‘S3’}, ‘score’: 0.45283788, ‘source_metadata’: {‘x-amz-bedrock-kb-source-uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/Paris_5.txt‘, ‘travelling_with_children’: ‘no’, ‘activities_interest’: [‘strolling’, ‘picnic’, ‘walk or bike ride’, ‘cafes and restaurants’, ‘art galleries and shops’], ‘companion’: ‘pet’, ‘x-amz-bedrock-kb-data-source-id’: ‘{YOUR_KNOWLEDGE_BASE_ID}, ‘stay_duration’: ‘unknown’, ‘preferred_month’: [‘unknown’], ‘travelling_with_pets’: ‘yes’, ‘age’: [’40’, ’41’, ’42’, ’43’, ’44’, ’45’, ’46’, ’47’, ’48’, ’49’, ’50’], ‘x-amz-bedrock-kb-chunk-id’: ‘1%3A0%3AmtKlapMBdxcT3sYpSK_N’, ‘desired_destination’: ‘Paris, France’}}
Option_0
FALSE
2
Paris, France
{ “metadataAttributes”: { “age”: [ “30” ], “desired_destination”: “London, United Kingdom”, “stay_duration”: “unknown”, “preferred_month”: [ “unknown” ], “activities_interest”: [ “strolling”, “sightseeing”, “boating”, “eating out” ], “companion”: “pets”, “travelling_with_children”: “no”, “travelling_with_pets”: “yes” } }
{‘location’: {‘s3Location’: {‘uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/London_2.txt.metadata (1).json’}, ‘type’: ‘S3’}, ‘score’: 0.49567315, ‘source_metadata’: {‘x-amz-bedrock-kb-source-uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/London_2.txt.metadata (1).json’, ‘x-amz-bedrock-kb-chunk-id’: ‘1%3A0%3A5tKlapMBdxcT3sYpYq_r’, ‘x-amz-bedrock-kb-data-source-id’: {YOUR_KNOWLEDGE_BASE_ID}}}
Option_0
FALSE
2
Paris, France
As a 35-year-old traveling with my two dogs, I found Paris to be a pet-friendly city with plenty of attractions and activities for pet owners. Here are some of my top recommendations for traveling with pets in Paris: The Jardin des Tuileries is a beautiful park located between the Louvre Museum and the Place de la Concorde…
{‘location’: {‘s3Location’: {‘uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/Paris_9.txt‘}, ‘type’: ‘S3’}, ‘score’: 0.4741059, ‘source_metadata’: {‘x-amz-bedrock-kb-source-uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/Paris_9.txt‘, ‘travelling_with_children’: ‘no’, ‘activities_interest’: [‘parks’, ‘museums’, ‘river cruises’, ‘neighborhood exploration’], ‘companion’: ‘pets’, ‘x-amz-bedrock-kb-data-source-id’: {YOUR_KNOWLEDGE_BASE_ID}, ‘stay_duration’: ‘unknown’, ‘preferred_month’: [‘unknown’], ‘travelling_with_pets’: ‘yes’, ‘age’: [’30’, ’31’, ’32’, ’33’, ’34’, ’35’, ’36’, ’37’, ’38’, ’39’, ’40’], ‘x-amz-bedrock-kb-chunk-id’: ‘1%3A0%3Aj52lapMBuHB13c7-hl-4’, ‘desired_destination’: ‘Paris, France’}}
Option_0
FALSE
2
Paris, France
If you are looking for something a little more active, I would suggest visiting the Bois de Boulogne. This large park is located on the western edge of Paris and is a great place to go for a walk or a bike ride with your pet. The park has several lakes and ponds, as well as several gardens and playgrounds…
{‘location’: {‘s3Location’: {‘uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/Paris_5.txt‘}, ‘type’: ‘S3’}, ‘score’: 0.45283788, ‘source_metadata’: {‘x-amz-bedrock-kb-source-uri’: ‘s3://{YOUR_S3_BUCKET}/travel_reviews_titan/Paris_5.txt‘, ‘travelling_with_children’: ‘no’, ‘activities_interest’: [‘strolling’, ‘picnic’, ‘walk or bike ride’, ‘cafes and restaurants’, ‘art galleries and shops’], ‘companion’: ‘pet’, ‘x-amz-bedrock-kb-data-source-id’: {YOUR_KNOWLEDGE_BASE_ID}, ‘stay_duration’: ‘unknown’, ‘preferred_month’: [‘unknown’], ‘travelling_with_pets’: ‘yes’, ‘age’: [’40’, ’41’, ’42’, ’43’, ’44’, ’45’, ’46’, ’47’, ’48’, ’49’, ’50’], ‘x-amz-bedrock-kb-chunk-id’: ‘1%3A0%3AmtKlapMBdxcT3sYpSK_N’, ‘desired_destination’: ‘Paris, France’}}
Clean up
To avoid incurring additional charges, be sure to delete your knowledge base, OSS/vector store and the underlying S3 bucket.
Conclusion
Enabling dynamic filtering through Knowledge Base’s metadata filtering enhances document retrieval in RAG systems by tailoring outputs to user-specific needs, significantly improving the relevance and accuracy of LLM-generated responses. In the travel website example, filters make sure that retrieved documents closely matched user preferences.
This approach can be applied to other use cases, such as customer support, personalized recommendations, and content curation, where context-sensitive information retrieval is essential. Properly configured filters are crucial for maintaining accuracy across different applications, making this feature a powerful tool for refining LLM outputs in diverse scenarios.
Be sure to take advantage of this powerful and flexible solution in your application. For more information on metadata in Amazon Bedrock Knowledge Bases, see Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy. Also, Amazon Bedrock Knowledge Bases now provides autogenerated query filters.
Security Best Practices
For AWS IAM Policies:
Apply least-privilege permissions by being explicit with IAM actions and listing only required permissions rather than using wildcards
Use temporary credentials with IAM roles for workloads
Avoid using wildcards (*) in the Action element as this grants access to all actions for specific AWS services
Remove wildcards from the Resource element and explicitly list the specific resources that IAM entities should access
Review AWS managed policies carefully before using them and consider using customer managed policies if AWS managed policies grant more permissions than needed
For more detailed security best practices for AWS IAM, see Security best practices in IAM.
For Amazon S3:
Block Public Access unless explicitly required, make sure S3 buckets are not publicly accessible by using the S3 Block Public Access feature and implementing appropriate bucket policies
Enable encryption for data at rest (all S3 buckets have default encryption) and enforce encryption for data in transit using HTTPS/TLS
Grant only the minimum permissions required using IAM policies, bucket policies, and disable ACLs (Access Control Lists) which are no longer recommended for most modern use cases
Enable server access logging, AWS CloudTrail, and use AWS security services like GuardDuty, Macie, and IAM Access Analyzer to monitor and detect potential security issues
For more detailed security best practices for Amazon S3, see Security best practices for Amazon S3.
For Amazon Bedrock:
Use IAM roles and policies to control access to Bedrock resources and APIs.
Implement VPC endpoints to access Bedrock securely from within your VPC.
Encrypt data at rest and in transit when working with Bedrock to protect sensitive information.
Monitor Bedrock usage and access patterns using AWS CloudTrail for auditing purposes.
For more information on security in Amazon Bedrock, see Security in Amazon Bedrock.
For Amazon SageMaker:
Use IAM roles to control access to SageMaker resources and limit permissions based on job functions.
Encrypt SageMaker notebooks, training jobs, and endpoints using AWS KMS keys for data protection.
Implement VPC configurations for SageMaker resources to restrict network access and enhance security.
Use SageMaker private endpoints to access APIs without traversing the public internet.
About the Authors
Haley Tien is a Deep Learning Architect at AWS Generative AI Innovation Center. She has a Master’s degree in Data Science and assists customers in building generative AI solutions on AWS to optimize their workloads and achieve desired outcomes.
Adam Weinberger is a Applied Scientist II at AWS Generative AI Innovation Center. He has 10 years of experience in data science and machine learning. He holds a Master’s of Information and Data Science from the University of California, Berkeley.
Dan Ford is a Applied Scientist II at AWS Generative AI Innovation Center, where he helps public sector customers build state-of-the-art GenAI solutions.