Generative AI has emerged as a transformative force, captivating industries with its potential to create, innovate, and solve complex problems. However, the journey from a proof of concept to a production-ready application comes with challenges and opportunities. Moving from proof of concept to production is about creating scalable, reliable, and impactful solutions that can drive business value and user satisfaction.
One of the most promising developments in this space is the rise of Retrieval Augmented Generation (RAG) applications. RAG is the process of optimizing the output of a foundation model (FM), so it references a knowledge base outside of its training data sources before generating a response.
The following diagram illustrates a sample architecture.
In this post, we explore the movement of RAG applications from their proof of concept or minimal viable product (MVP) phase to full-fledged production systems. When transitioning a RAG application from a proof of concept to a production-ready system, optimization becomes crucial to make sure the solution is reliable, cost-effective, and high-performing. Let’s explore these optimization techniques in greater depth, setting the stage for future discussions on hosting, scaling, security, and observability considerations.
Optimization techniques
The diagram below illustrates the tradeoffs to consider for a production-ready RAG application.
The success of a production-ready RAG system is measured by its quality, cost, and latency. Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. For example, consider the use case of generating personalized marketing content for a luxury fashion brand. The brand might be willing to absorb the higher costs of using a more powerful and expensive FMs to achieve the highest-quality classifications, because misclassifications could lead to customer dissatisfaction and damage the brand’s reputation. Consider another use case of generating personalized product descriptions for an ecommerce site. The retailer might be willing to accept slightly longer latency to reduce infrastructure and operational costs, as long as the generated descriptions remain reasonably accurate and compelling. The optimal balance of quality, cost, and latency can vary significantly across different applications and industries.
Let’s look into practical guidelines on how you can enhance the overall quality of your RAG workflow, including the quality of the retriever and quality of the result generator using Amazon Bedrock Knowledge Bases and other features of Amazon Bedrock. Amazon Bedrock Knowledge Bases provides a fully managed capability that helps you implement the entire RAG workflow from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows.
Evaluation framework
An effective evaluation framework is crucial for assessing and optimizing RAG systems as they move from proof of concept to production. These frameworks typically include overall metrics for a holistic assessment of the entire RAG pipeline, as well as specific diagnostic metrics for both the retrieval and generation components. This allows for targeted improvements in each phase of the system. By implementing a robust evaluation framework, developers can continuously monitor, diagnose, and enhance their RAG systems, achieving optimal performance across quality, cost, and latency dimensions as the application scales to production levels. Amazon Bedrock Evaluations can help you evaluate your retrieval or end-to-end RAG workflow in Amazon Bedrock Knowledge Bases. In the following sections, we discuss these specific metrics in different phases of the RAG workflow in more detail.
Retriever quality
For better retrieval performance, the way the data is stored in the vector store has a big impact. For example, your input document might include tables within the PDF. In such cases, using an FM to parse the data will provide better results. You can use advanced parsing options supported by Amazon Bedrock Knowledge Bases for parsing non-textual information from documents using FMs. Many organizations store their data in structured formats within data warehouses and data lakes. Amazon Bedrock Knowledge Bases offers a feature that lets you connect your RAG workflow to structured data stores. This fully managed out-of-the-box RAG solution can help you natively query structured data from where it resides.
Another important consideration is the way your source document is split up into chunks. If your document would benefit from inherent relationships within your document, it might be wise to use hierarchical chunking, which allows for more granular and efficient retrieval. Some documents benefit from semantic chunking by preserving the contextual relationship in the chunks, helping make sure that the related information stays together in logical chunks. You can also use your own custom chunking strategy for your RAG application’s unique requirements.
RAG applications process user queries by searching across a large set of documents. However, in many situations, you might need to retrieve documents with specific attributes or content. You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. Amazon Bedrock Knowledge Bases now also supports auto generated query filters, which extend the existing capability of manual metadata filtering by allowing you to narrow down search results without the need to manually construct complex filter expressions. This improves retrieval accuracy by making sure the documents are relevant to the query.
Generator quality
Writing an effective query is just as important as any other consideration for generation accuracy. You can add a prompt providing instructions to the FM to provide an appropriate answer to the user. For example, a legal tech company would want to provide instructions to restrict the answers to be based on the input documents and not based on general information known to the FM. Query decomposition by splitting the input query into multiple queries is also helpful in retrieval accuracy. In this process, the subqueries with less semantic complexity might find more targeted chunks. These chunks can then be pooled and ranked together before passing them to the FM to generate a response.
Reranking, as a post-retrieval step, can significantly improve response quality. This technique uses LLMs to analyze the semantic relevance between the query and retrieved documents, reordering them based on their pertinence. By incorporating reranking, you make sure that only the most contextually relevant information is used for generation, leading to more accurate and coherent responses.
Adjusting inference parameters, such as temperature and top-k/p sampling, can help in further refining the output.
You can use Amazon Bedrock Knowledge Bases to configure and customize queries and response generation. You can also improve the relevance of your query responses with a reranker model in Amazon Bedrock.
Overall quality
The key metrics for retriever quality are context precision, context recall, and context relevance. Context precision measures how well the system ranks relevant pieces of information from the given context. It considers the question, ground truth, and context. Context recall provides the percentage of ground truth claims or key information covered by the retrieved context. Context relevance measures whether the retrieved passages or chunks are relevant for answering the given query, excluding extraneous details. Together, these three metrics offer insight into how effectively the retriever is able to surface the most relevant and focused source material to support a high-quality response.
Generator quality can be assessed through several key metrics. Context utilization examines how effectively the generator uses relevant information from the provided source material. Noise sensitivity gauges the generator’s propensity to include inaccurate details from the retrieved content. Hallucination measures the extent to which the generator produces incorrect claims not present in the source data. Self-knowledge reflects the proportion of accurate statements generated that can’t be found in the retrieved chunks. Finally, faithfulness evaluates how closely the generator’s output aligns with the information contained in the source material.
For measuring the overall generation quality, the key metrics include measuring the precision, recall, and answer similarity. Precision suggests the proportion of the correct claims in model’s response, whereas recall suggests the proportion of the ground truth claims covered by the model’s response. Answer similarity compares the meaning and content of a generated answer with a reference or ground truth answer. It evaluates how closely the generated answer matches the intended meaning of the ground truth answer.
Establishing a feedback loop with an evaluation framework against these quality metrics allows for continuous improvement, where the system can learn from user interactions and refine its performance over time. By optimizing these quality metrics, the RAG system can be designed to deliver reliable, cost-effective, and high-performing results for users.
For a demonstration on how you can use a RAG evaluation framework in Amazon Bedrock to compute RAG quality metrics, refer to New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock.
Responsible AI
Implementing responsible AI practices is crucial for maintaining ethical and safe deployment of RAG systems. This includes using guardrails to filter harmful content, deny certain topics, mask sensitive information, and ground responses in verified sources to reduce hallucinations.
You can use Amazon Bedrock Guardrails for implementing responsible AI policies. Along with protecting against toxicity and harmful content, it can also be used for Automated Reasoning checks, which helps you protect against hallucinations.
Cost and latency
Cost considers the compute resources and infrastructure required to run the system, and latency evaluates the response times experienced by end-users. To optimize cost and latency, implement caching strategies to reduce the need for expensive model inferences. Efficient query batching can also improve overall throughput and reduce resource usage. Balance performance and resource usage to find the ideal configuration that meets your application’s requirements.
Use tools like Amazon Bedrock Knowledge Bases so you can take advantage of fully managed support for the end-to-end RAG workflow. It supports many of the advanced RAG capabilities we discussed earlier. By addressing these optimization techniques, you can transition your RAG-powered proof of concept to a robust, production-ready system that delivers high-quality, cost-effective, and low-latency responses to your users.
For more information on building RAG applications using Amazon Bedrock Knowledge Bases, refer to Building scalable, secure, and reliable RAG applications using Amazon Bedrock Knowledge Bases.
Hosting and scaling
When it comes to hosting your web application or service, there are several approaches to consider. The key is to choose a solution that can effectively host your database and compute infrastructure. This could include server-based options like Amazon Elastic Compute Cloud (Amazon EC2), managed services like Amazon Relational Database Service (Amazon RDS) and Amazon DynamoDB, or serverless approaches such as AWS Amplify and Amazon Elastic Container Service (Amazon ECS). For a practical approach to building an automated AI assistant using Amazon ECS, see Develop a fully automated chat-based assistant by using Amazon Bedrock agents and knowledge bases.
In addition to the server or compute layer, you will also need to consider an orchestration tool, testing environments, and a continuous integration and delivery (CI/CD) pipeline to streamline your application deployment. Having a feedback loop established based on the quality metrics along with a CI/CD pipeline is an important first step to creating self-healing architectures.
As your application grows, you will need to make sure your infrastructure can scale to meet the increasing demand. This can involve containerization with Docker or choosing serverless options, implementing load balancing, setting up auto scaling, and choosing between on-premises, cloud, or hybrid solutions. It also includes unique scaling requirements of your frontend application and backend generative AI workflow, as well as the use of content delivery networks (CDNs) and disaster recovery and backup strategies.
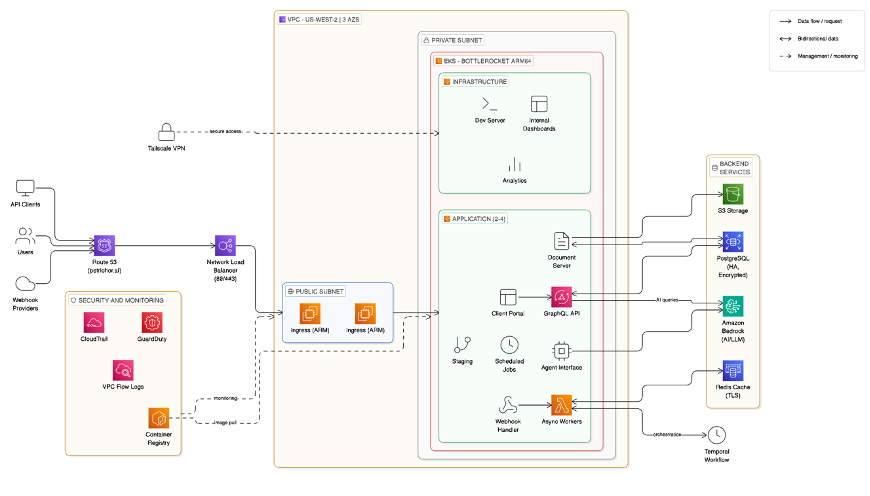
The following is a sample architecture for a secure and scalable RAG-based web application. This architecture uses Amazon ECS for hosting the service, Amazon CloudFront as a CDN, AWS WAF as a firewall, and Amazon MemoryDB for providing a semantic cache.
By carefully considering these aspects of hosting and scaling your infrastructure, you can build a resilient and adaptable system to support your growing web application or service. Stay tuned for more detailed information on these topics in upcoming blog posts.
Data privacy, security, and observability
Maintaining data privacy and security is of utmost importance. This includes implementing security measures at each layer of your application, from encrypting data in transit to setting up robust authentication and authorization controls. It also involves focusing on compute and storage security, as well as network security. Compliance with relevant regulations and regular security audits are essential. Securing your generative AI system is another crucial aspect. By default, Amazon Bedrock Knowledge Bases encrypts the traffic using AWS managed AWS Key Management Service (AWS KMS) keys. You can also choose customer managed KMS keys for more control over encryption keys. For more information on application security, refer to Safeguard a generative AI travel agent with prompt engineering and Amazon Bedrock Guardrails.
Comprehensive logging, monitoring, and maintenance are crucial to maintaining a healthy infrastructure. This includes setting up structured logging, centralized log management, real-time monitoring, and strategies for system updates and migrations.
By addressing these critical areas, you can build a secure and resilient infrastructure to support your growing web application or service. Stay tuned for more in-depth coverage of these topics in upcoming blog posts.
Conclusion
To successfully transition a RAG application from a proof of concept to a production-ready system, you should focus on optimizing the solution for reliability, cost-effectiveness, and high performance. Key areas to address include enhancing retriever and generator quality, balancing cost and latency, and establishing a robust and secure infrastructure.
By using purpose-built tools like Amazon Bedrock Knowledge Bases to streamline the end-to-end RAG workflow, organizations can successfully transition their RAG-powered proofs of concept into high-performing, cost-effective, secure production-ready solutions that deliver business value.
References
New Amazon Bedrock capabilities enhance data processing and retrieval
New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock
Prevent factual errors from LLM hallucinations with mathematically sound Automated Reasoning checks
Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy
Amazon Bedrock Knowledge Bases now supports advanced parsing, chunking, and query reformulation giving greater control of accuracy in RAG based applications
A Developer’s Guide to Advanced Chunking and Parsing with Amazon Bedrock
Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training
Improve speed and reduce cost for generative AI workloads with a persistent semantic cache in Amazon MemoryDB
Improve RAG accuracy with fine-tuned embedding models on Amazon SageMaker
Develop a fully automated chat-based assistant by using Amazon Bedrock agents and knowledge bases
Safeguard a generative AI travel agent with prompt engineering and Amazon Bedrock Guardrails
Building scalable, secure, and reliable RAG applications using Amazon Bedrock Knowledge Bases
Evaluate the reliability of Retrieval Augmented Generation applications using Amazon Bedrock
About the Author
Vivek Mittal is a Solution Architect at Amazon Web Services, where he helps organizations architect and implement cutting-edge cloud solutions. With a deep passion for Generative AI, Machine Learning, and Serverless technologies, he specializes in helping customers harness these innovations to drive business transformation. He finds particular satisfaction in collaborating with customers to turn their ambitious technological visions into reality.
Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.