In this new era of emerging AI technologies, we have the opportunity to build AI-powered assistants tailored to specific business requirements. Amazon Q Business, a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprise’s systems.
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. However, ingesting large volumes of enterprise data poses significant challenges, particularly in orchestrating workflows to gather data from diverse sources.
In this post, we propose an end-to-end solution using Amazon Q Business to simplify integration of enterprise knowledge bases at scale.
Enhancing AWS Support Engineering efficiency
The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. For complex customer issues, the process was especially time-consuming, laborious, and at times extended the wait time for customers seeking resolutions. To address this, the team implemented a chat assistant using Amazon Q Business. This solution ingests and processes data from hundreds of thousands of support tickets, escalation notices, public AWS documentation, re:Post articles, and AWS blog posts.
By using Amazon Q Business, which simplifies the complexity of developing and managing ML infrastructure and models, the team rapidly deployed their chat solution. The Amazon Q Business pre-built connectors like Amazon Simple Storage Service (Amazon S3), document retrievers, and upload capabilities streamlined data ingestion and processing, enabling the team to provide swift, accurate responses to both basic and advanced customer queries.
In this post, we propose an end-to-end solution using Amazon Q Business to address similar enterprise data challenges, showcasing how it can streamline operations and enhance customer service across various industries. First we discuss end-to-end large-scale data integration with Amazon Q Business, covering data preprocessing, security guardrail implementation, and Amazon Q Business best practices. Then we introduce the solution deployment using three AWS CloudFormation templates.
Solution overview
The following architecture diagram represents the high-level design of a solution proven effective in production environments for AWS Support Engineering. This solution uses the powerful capabilities of Amazon Q Business. We will walk through the implementation of key components, including configuring enterprise data sources to build our knowledge base, document indexing and boosting, and implementing comprehensive security controls.
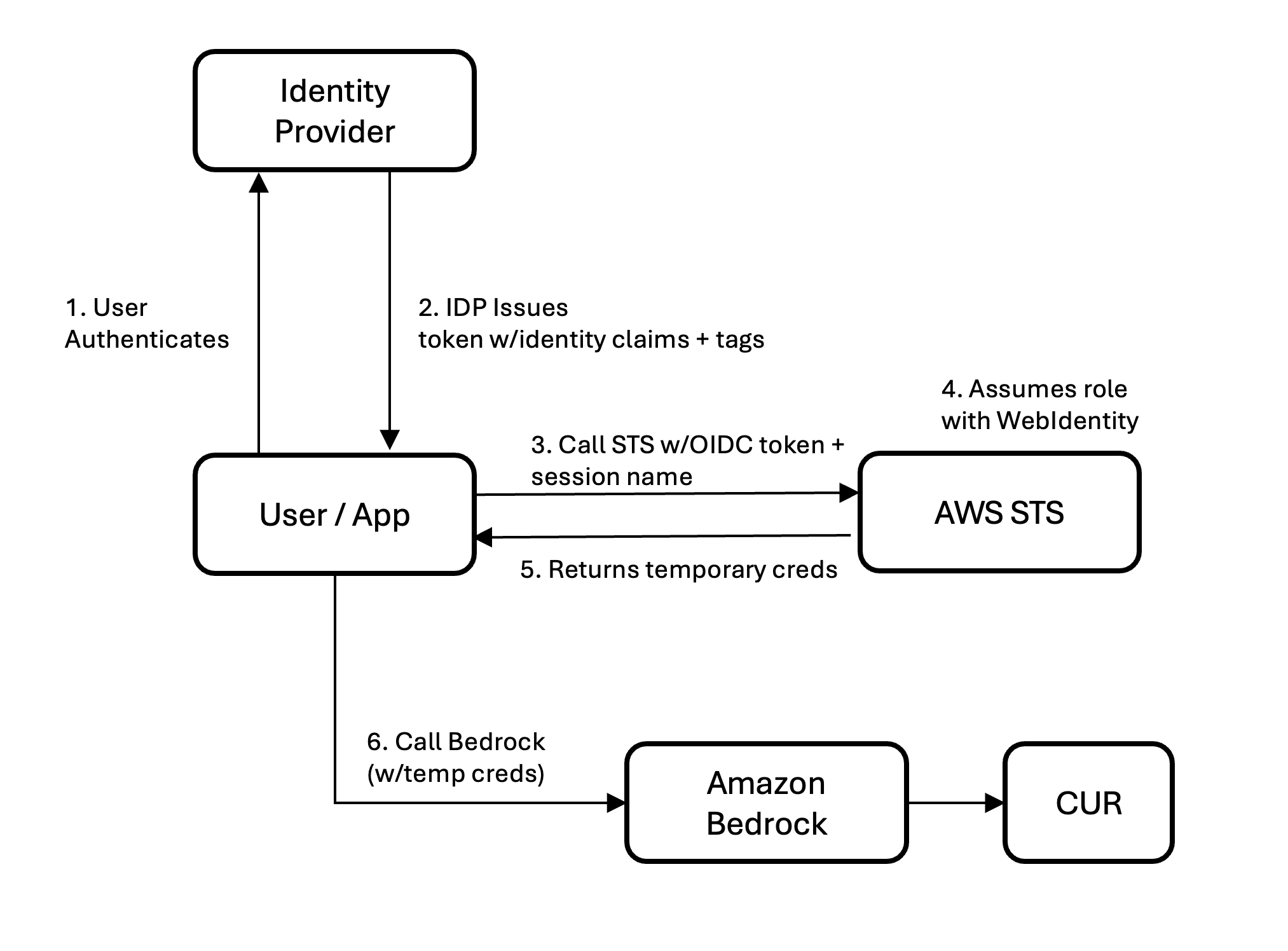
Amazon Q Business supports three users types as part of identity and access management:
Service user – An end-user who accesses Amazon Q Business applications with permissions granted by their administrator to perform their job duties
Service administrator – A user who manages Amazon Q Business resources and determines feature access for service users within the organization
IAM administrator – A user responsible for creating and managing access policies for Amazon Q Business through AWS IAM Identity Center
The following workflow details how a service user accesses the application:
The service user initiates an interaction with the Amazon Q Business application, accessible through the web experience, which is an endpoint URL.
The service user’s permissions are authenticated using IAM Identity Center, an AWS solution that connects workforce users to AWS managed applications like Amazon Q Business. It enables end-user authentication and streamlines access management.
The authenticated service user submits queries in natural language to the Amazon Q Business application.
The Amazon Q Business application generates and returns answers drawing from the enterprise data uploaded to an S3 bucket, which is connected as a data source to Amazon Q Business. This S3 bucket data is continuously refreshed, making sure that Amazon Q Business accesses the most current information for query responses by using a retriever to pull data from the index.
Large-scale data ingestion
Before ingesting the data to Amazon Q Business, the data might need transformation into formats supported by Amazon Q Business. Furthermore, it might contain sensitive data or personally identifiable information (PII) requiring redaction. These data ingestion challenges create a need to orchestrate tasks like transformation, redaction, and secure ingestion.
Data ingestion workflow
To facilitate orchestration, this solution incorporates AWS Step Functions. Step Functions provides a visual workflow service to orchestrate tasks and workloads resiliently and efficiently through built-in AWS integrations and error handling. The solution uses the Step Functions Map state, which allows for parallel processing of multiple items in a dataset, thereby efficiently orchestrating workflows and speeding up overall processing.
The following diagram illustrates an example architecture for ingesting data through an endpoint interfacing with a large corpus.
Step Functions orchestrates AWS services like AWS Lambda and organization APIs like DataStore to ingest, process, and store data securely. The workflow includes the following steps:
The Prepare Map Input Lambda function prepares the required input for the Map state. For example, the Datastore API might require certain input like date periods to query data. This step can be used to define the date periods to be used by the Map state as an input.
The Ingest Data Lambda function fetches data from the Datastore API—which can be in or outside of the virtual private cloud (VPC)—based on the inputs from the Map state. To handle large volumes, the data is split into smaller chunks to mitigate Lambda function overload. This enables Step Functions to manage the workload, retry failed chunks, and isolate failures to individual chunks instead of disrupting the entire ingestion process.
The fetched data is put into an S3 data store bucket for processing.
The Process Data Lambda function redacts sensitive data through Amazon Comprehend. Amazon Comprehend provides real-time APIs, such as DetectPiiEntities and DetectEntities, which use natural language processing (NLP) machine learning (ML) models to identify text portions for redaction. When Amazon Comprehend detects PII, the terms will be redacted and replaced by a character of your choice (such as *). You can also use regular expressions to remove identifiers with predetermined formats.
Finally, the Lambda function creates two separate files:
A sanitized data document in an Amazon Q Business supported format that will be parsed to generate chat responses.
A JSON metadata file for each document containing additional information to customize chat results for end-users and apply boosting techniques to enhance user experience (which we discuss more in the next section).
The following is the sample metadata file:
In the preceding JSON file, the DocumentId for each data document must be unique. All the other attributes are optional; however, the file has additional attributes like services, _created_at, and _last_updated_at with values defined.
The two files are placed in a new S3 folder for Amazon Q to index. Additionally, the raw unprocessed data is deleted from the S3 bucket. You can further restrict access to documents uploaded to an S3 bucket for specific users or groups using Amazon S3 access control lists (ACLs).
Using the Amazon Q Business data source connector feature, we integrated the S3 bucket with our application. This connector functionality enables the consolidation of data from multiple sources into a unified index for the Amazon Q Business application. The service offers various integration options, with Amazon S3 being one of the supported data sources.
Boosting performance
When working with your specific dataset in Amazon Q Business, you can use relevance tuning to enhance the performance and accuracy of search results. This feature allows you to customize how Amazon Q Business prioritizes information within your ingested documents. For example, if your dataset includes product descriptions, customer reviews, and technical specifications, you can use relevance tuning to boost the importance of certain fields. You might choose to prioritize product names in titles, give more weight to recent customer reviews, or emphasize specific technical attributes that are crucial for your business. By adjusting these parameters, you can influence the ranking of search results to better align with your dataset’s unique characteristics and your users’ information needs, ultimately providing more relevant answers to their queries.
For the metadata file used in this example, we focus on boosting two key metadata attributes: _document_title and services. By assigning higher weights to these attributes, we made sure documents with specific titles or services received greater prominence in the search results, improving their visibility and relevance for the users
The following code is the sample CloudFormation template snippet to enable higher weights to _document_title and services:
Amazon Q Business guardrails
Implementing robust security measures is crucial to protect sensitive information. In this regard, Amazon Q Business guardrails or chat controls proved invaluable, offering a powerful solution to maintain data privacy and security.
Amazon Q Business guardrails provide configurable rules designed to control the application’s behavior. These guardrails act as a safety net, minimizing access, processing, or revealing of sensitive or inappropriate information. By defining boundaries for the application’s operations, organizations can maintain compliance with internal policies and external regulations. You can enable global- or topic-level controls, which control how Amazon Q Business responds to specific topics in chat.
The following is the sample CloudFormation template snippet to enable topic-level controls:
This topic-level control blocks the Amazon Q Business chat conversation that has AWS service Amazon Resource Names (ARNs). When similar chat messages have been detected by the Amazon Q Business application, the system will block the responses and return the message “This message is blocked as it contains secure content.”
For information about deploying the Amazon Q Business application with sample boosting and guardrails, refer to the GitHub repo.
The following screenshot shows an example of the Amazon Q Business assistant chat landing page.
The following screenshot illustrates the assistant’s behavior if a user includes text that matches one of the similarity-based examples specified in the guardrail topic control.
Notification system
To enhance data security, you can deploy Amazon Macie classification jobs to scan for sensitive or PII data stored in S3 buckets. The following diagram illustrates a sample notification architecture to alert users on sensitive information that might be inadvertently stored. Macie uses machine learning to automatically discover, classify, and protect sensitive data stored in AWS. It focuses on identifying PII, intellectual property, and other sensitive data types to help organizations meet compliance requirements and protect their data from unauthorized access or breaches.
The workflow includes the following steps:
Macie reviews the data store S3 bucket for sensitive information before being ingested.
If Macie detects sensitive information, it publishes its findings to Amazon EventBridge.
An EventBridge rule invokes the Rectify & Notify Lambda function.
The Lambda function processes the alert, remediates it by removing the affected files from the S3 bucket, and sends a notification using Amazon Simple Notification Service (Amazon SNS) to the subscribed email addresses.
This system enables rapid response to potential security alerts, allowing for immediate action to protect sensitive data.
The Macie detection and subsequent notification system can be demonstrated by uploading a new file to the S3 bucket, such as sample-file-with-credentials.txt, containing the PII data types monitored by Macie, such as fake temporary AWS credentials. After the file is uploaded to Amazon S3 and the scheduled Macie detection job discovers it, the Lambda function immediately removes the file and sends the following notification email to the SNS topic subscribers:
The notification contains the full Macie finding event, which is omitted from the preceding excerpt. For more information on Macie finding events format, refer to Amazon EventBridge event schema for Macie findings.
Additionally, the findings are visible on the Macie console, as shown in the following screenshot.
Additional recommendations
To further enhance the security and reliability of the Amazon Q Business application, we recommend implementing the following measures. These additional security and logging implementations make sure the data is protected, alerts are sent in response to potential warnings, and timely actions can be taken for security incidents.
Amazon CloudWatch logging for Amazon Q Business – You can use Amazon CloudWatch logging for Amazon Q Business to save the logs for the data source connectors and document-level errors, focusing particularly on failed ingestion jobs. This practice is vital from a security perspective because it allows monitoring and quick identification of issues in the data ingestion process. By tracking failed jobs, potential data loss or corruption can be mitigated, maintaining the reliability and completeness of the knowledge base.
Unauthorized access monitoring on Amazon S3 – You can implement EventBridge rules to monitor mutating API actions on the S3 buckets. These rules are configured to invoke SNS notifications when such actions are performed by unauthorized users. Enable Amazon S3 server access logging to store detailed access records in a designated bucket, which can be analyzed using Amazon Athena for deeper insights. This approach provides real-time alerts for immediate response to potential security breaches, while also maintaining a detailed audit trail for thorough security analysis, making sure that only authorized entities can modify critical data.
Prerequisites
In the following sections, we walk through implementing the end-to-end solution. For this solution to work, the following prerequisites are needed:
A new or existing AWS account that will be the data collection account
Corresponding AWS Identity and Access Management (IAM) permissions to create S3 buckets and deploy CloudFormation stacks
Configure the data ingestion
In this post, we demonstrate the solution using publicly available documentation as our sample dataset. In your implementation, you can adapt this solution to work with your organization’s specific content sources, such as support tickets, JIRA issues, internal wikis, or other relevant documentation.
Deploy the following CloudFormation template to create the data ingestion resources:
S3 data bucket
Ingestion Lambda function
Processing Lambda function
Step Functions workflow
The data ingestion workflow in this example fetches and processes public data from the Amazon Q Business and Amazon SageMaker official documentation in PDF format. Specifically, the Ingest Data Lambda function downloads the raw PDF documents, temporarily stores them in Amazon S3, and passes their Amazon S3 URLs to the Process Data Lambda function, which performs the PII redaction (if enabled) and stores the processed documents and their metadata to the S3 path indexed by the Amazon Q Business application.
You can adapt the Step Functions Lambda code for ingestion and processing according to your own internal data, making sure that the documents and metadata are in a valid format for Amazon Q Business to index, and are properly redacted for PII data.
Configure IAM Identity Center
You can only have one IAM Identity Center instance per account. If your account already has an Identity Center instance, skip this step and proceed to configuring the Amazon Q Business application.
Deploy the following CloudFormation template to configure IAM Identity Center.
You will need to add details for a user such as user name, email, first name, and surname.
After deploying the CloudFormation template, you will receive an email where you will need to accept the invitation and change the password for the user.
Before logging in, you will need to deploy the Amazon Q Business application.
Configure the Amazon Q Business application
Deploy the following CloudFormation template to configure the Amazon Q Business application.
You will need to add details such as the IAM Identity Center stack name deployed previously and the S3 bucket name provisioned by the data ingestion stack.
After you deploy the CloudFormation template, complete the following steps to manage user access:
On the Amazon Q Business console, choose Applications in the navigation pane.
Choose the application you provisioned (workshop-app-01).
Under User access, choose Manage user access.
On the Users tab, choose the user you specified when deploying the CloudFormation stack.
Choose Edit subscription.
Under New subscription, choose Business Lite or Business Pro.
Choose Confirm and then Confirm
Now you can log in using the user you have specified. You can find the URL for the web experience under Web experience settings.
If you are unable to log in, make sure that the user has been verified.
Sync the data source
Before you can use the Amazon Q Business application, the data source needs to be synchronized. The application’s data source is configured to sync hourly. It might take some time to synchronize.
When the synchronization is complete, you should now be able to access the application and ask questions.
Clean up
After you’re done testing the solution, you can delete the resources to avoid incurring additional charges. See the Amazon Q Business pricing page for more information. Follow the instructions in the GitHub repository to delete the resources and corresponding CloudFormation templates. Make sure to delete the CloudFormation stacks provisioned as follows:
Delete the Amazon Q Business application stack.
Delete the IAM Identity Center stack.
Delete the data ingestion
For each deleted stack, check for any resources that were skipped in the deletion process, such as S3 buckets.
Delete any skipped resources on the console.
Conclusion
In this post, we demonstrated how to build a knowledge base solution by integrating enterprise data with Amazon Q Business using Amazon S3. This approach helps organizations improve operational efficiency, reduce response times, and gain valuable insights from their historical data. The solution uses AWS security best practices to promote data protection while enabling teams to create a comprehensive knowledge base from various data sources.
Whether you’re managing support tickets, internal documentation, or other business content, this solution can handle multiple data sources and scale according to your needs, making it suitable for organizations of different sizes. By implementing this solution, you can enhance your operations with AI-powered assistance, automated responses, and intelligent routing of complex queries.
Try this solution with your own use case, and let us know about your experience in the comments section.
About the Author
Omar Elkharbotly is a Senior Cloud Support Engineer at AWS, specializing in Data, Machine Learning, and Generative AI solutions. With extensive experience in helping customers architect and optimize their cloud-based AI/ML/GenAI workloads, Omar works closely with AWS customers to solve complex technical challenges and implement best practices across the AWS AI/ML/GenAI service portfolio. He is passionate about helping organizations leverage the full potential of cloud computing to drive innovation in generative AI and machine learning.
Vania Toma is a Principal Cloud Support Engineer at AWS, focused on Networking and Generative AI solutions. He has deep expertise in resolving complex, cross-domain technical challenges through systematic problem-solving methodologies. With a customer-obsessed mindset, he leverages emerging technologies to drive innovation and deliver exceptional customer experiences.
Bhavani Kanneganti is a Principal Cloud Support Engineer at AWS. She specializes in solving complex customer issues on the AWS Cloud, focusing on infrastructure-as-code, container orchestration, and generative AI technologies. She collaborates with teams across AWS to design solutions that enhance the customer experience. Outside of work, Bhavani enjoys cooking and traveling.
Mattia Sandrini is a Senior Cloud Support Engineer at AWS, specialized in Machine Learning technologies and Generative AI solutions, helping customers operate and optimize their ML workloads. With a deep passion for driving performance improvements, he dedicates himself to empowering both customers and teams through innovative ML-enabled solutions. Away from his technical pursuits, Mattia embraces his passion for travel and adventure.
Kevin Draai is a Senior Cloud Support Engineer at AWS who specializes in Serverless technologies and development within the AWS cloud. Kevin has a passion for creating solutions through code while ensuring it is built on solid infrastructure. Outside of work, Kevin enjoys art and sport.
Tipu Qureshi is a Senior Principal Engineer leading AWS. Tipu supports customers with designing and optimizing their cloud technology strategy as a senior principal engineer in AWS Support & Managed Services. For over 15 years, he has designed, operated and supported diverse distributed systems at scale with a passion for operational excellence. He currently works on generative AI and operational excellence.