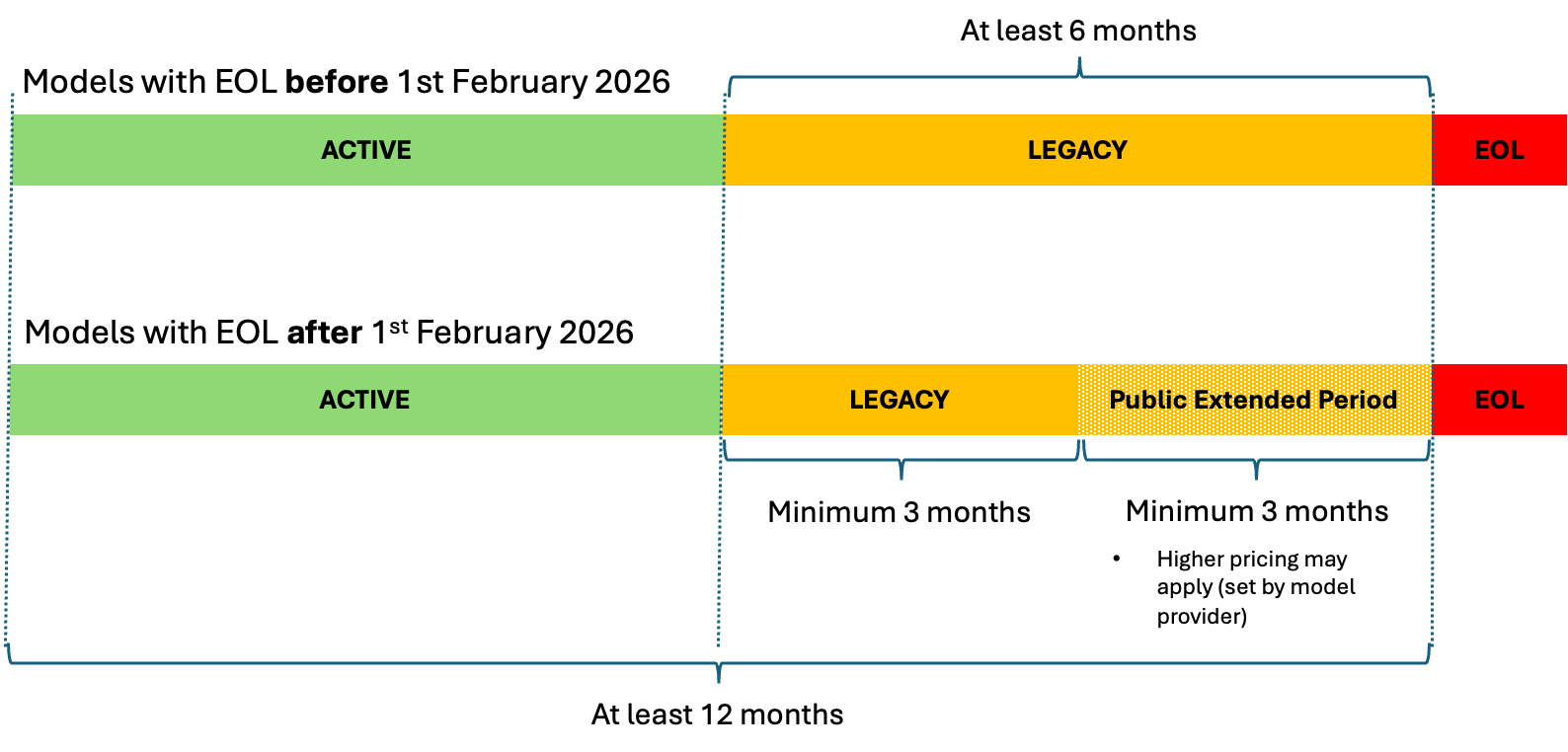
Today, we are happy to announce the availability of Binary Embeddings for Amazon Titan Text Embeddings V2 in Amazon Bedrock Knowledge Bases and Amazon OpenSearch Serverless. With support for binary embedding in Amazon Bedrock and a binary vector store in OpenSearch Serverless, you can use binary embeddings and binary vector store to build Retrieval Augmented Generation (RAG) applications in Amazon Bedrock Knowledge Bases, reducing memory usage and overall costs.
Amazon Bedrock is a fully managed service that provides a single API to access and use various high-performing foundation models (FMs) from leading AI companies. Amazon Bedrock also offers a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Using Amazon Bedrock Knowledge Bases, FMs and agents can retrieve contextual information from your company’s private data sources for RAG. RAG helps FMs deliver more relevant, accurate, and customized responses.
Amazon Titan Text Embeddings models generate meaningful semantic representations of documents, paragraphs, and sentences. Amazon Titan Text Embeddings takes as an input a body of text and generates a 1,024 (default), 512, or 256 dimensional vector. Amazon Titan Text Embeddings are offered through latency-optimized endpoint invocation for faster search (recommended during the retrieval step) and throughput-optimized batch jobs for faster indexing. With Binary Embeddings, Amazon Titan Text Embeddings V2 will represent data as binary vectors with each dimension encoded as a single binary digit (0 or 1). This binary representation will convert high-dimensional data into a more efficient format for storage and computation.
Amazon OpenSearch Serverless is a serverless deployment option for Amazon OpenSearch Service, a fully managed service that makes it simple to perform interactive log analytics, real-time application monitoring, website search, and vector search with its k-nearest neighbor (kNN) plugin. It supports exact and approximate nearest-neighbor algorithms and multiple storage and matching engines. It makes it simple for you to build modern machine learning (ML) augmented search experiences, generative AI applications, and analytics workloads without having to manage the underlying infrastructure.
The OpenSearch Serverless kNN plugin now supports 16-bit (FP16) and binary vectors, in addition to 32-bit floating point vectors (FP32). You can store the binary embeddings generated by Amazon Titan Text Embeddings V2 for lower costs by setting the kNN vector field type to binary. The vectors can be stored and searched in OpenSearch Serverless using PUT and GET APIs.
This post summarizes the benefits of this new binary vector support across Amazon Titan Text Embeddings, Amazon Bedrock Knowledge Bases, and OpenSearch Serverless, and gives you information on how you can get started. The following diagram is a rough architecture diagram with Amazon Bedrock Knowledge Bases and Amazon OpenSearch Serverless.
You can lower latency and reduce storage costs and memory requirements in OpenSearch Serverless and Amazon Bedrock Knowledge Bases with minimal reduction in retrieval quality.
We ran the Massive Text Embedding Benchmark (MTEB) retrieval data set with binary embeddings. On this data set, we reduced storage, while observing a 25-times improvement in latency. Binary embeddings maintained 98.5% of the retrieval accuracy with re-ranking, and 97% without re-ranking. Compare these results to the results we got using full precision (float32) embeddings. In end-to-end RAG benchmark comparisons with full-precision embeddings, Binary Embeddings with Amazon Titan Text Embeddings V2 retain 99.1% of the full-precision answer correctness (98.6% without reranking). We encourage customers to do their own benchmarks using Amazon OpenSearch Serverless and Binary Embeddings for Amazon Titan Text Embeddings V2.
OpenSearch Serverless benchmarks using the Hierarchical Navigable Small Worlds (HNSW) algorithm with binary vectors have unveiled a 50% reduction in search OpenSearch Computing Units (OCUs), translating to cost savings for users. The use of binary indexes has resulted in significantly faster retrieval times. Traditional search methods often rely on computationally intensive calculations such as L2 and cosine distances, which can be resource-intensive. In contrast, binary indexes in Amazon OpenSearch Serverless operate on Hamming distances, a more efficient approach that accelerates search queries.
In the following sections we’ll discuss the how-to for binary embeddings with Amazon Titan Text Embeddings, binary vectors (and FP16) for vector engine, and binary embedding option for Amazon Bedrock Knowledge Bases To learn more about Amazon Bedrock Knowledge Bases, visit Knowledge Bases now delivers fully managed RAG experience in Amazon Bedrock.
Generate Binary Embeddings with Amazon Titan Text Embeddings V2
Amazon Titan Text Embeddings V2 now supports Binary Embeddings and is optimized for retrieval performance and accuracy across different dimension sizes (1024, 512, 256) with text support for more than 100 languages. By default, Amazon Titan Text Embeddings models produce embeddings at Floating Point 32 bit (FP32) precision. Although using a 1024-dimension vector of FP32 embeddings helps achieve better accuracy, it also leads to large storage requirements and related costs in retrieval use cases.
To generate binary embeddings in code, add the right embeddingTypes parameter in your invoke_model API request to Amazon Titan Text Embeddings V2:
As in the request above, we can request either the binary embedding alone or both binary and float embeddings. The preceding embedding above is a 1024-length binary vector similar to:
array([0, 1, 1, …, 0, 0, 0], dtype=int8)
For more information and sample code, refer to Amazon Titan Embeddings Text.
Configure Amazon Bedrock Knowledge Bases with Binary Vector Embeddings
You can use Amazon Bedrock Knowledge Bases, to take advantage of the Binary Embeddings with Amazon Titan Text Embeddings V2 and the binary vectors and Floating Point 16 bit (FP16) for vector engine in Amazon OpenSearch Serverless, without writing a single line of code. Follow these steps:
On the Amazon Bedrock console, create a knowledge base. Provide the knowledge base details, including name and description, and create a new or use an existing service role with the relevant AWS Identity and Access Management (IAM) permissions. For information on creating service roles, refer to Service roles. Under Choose data source, choose Amazon S3, as shown in the following screenshot. Choose Next.
Configure the data source. Enter a name and description. Define the source S3 URI. Under Chunking and parsing configurations, choose Default. Choose Next to continue.
Complete the knowledge base setup by selecting an embeddings model. For this walkthrough, select Titan Text Embedding v2. Under Embeddings type, choose Binary vector embeddings. Under Vector dimensions, choose 1024. Choose Quick Create a New Vector Store. This option will configure a new Amazon Open Search Serverless store that supports the binary data type.
You can check the knowledge base details after creation to monitor the data source sync status. After the sync is complete, you can test the knowledge base and check the FM’s responses.
Conclusion
As we’ve explored throughout this post, Binary Embeddings are an option in Amazon Titan Text Embeddings V2 models available in Amazon Bedrock and the binary vector store in OpenSearch Serverless. These features significantly reduce memory and disk needs in Amazon Bedrock and OpenSearch Serverless, resulting in fewer OCUs for the RAG solution. You’ll also experience better performance and improvement in latency, but there will be some impact on the accuracy of the results compared to using the full float data type (FP32). Although the drop in accuracy is minimal, you have to decide if it suits your application. The specific benefits will vary based on factors such as the volume of data, search traffic, and storage requirements, but the examples discussed in this post illustrate the potential value.
Binary Embeddings support in Amazon Open Search Serverless, Amazon Bedrock Knowledge Bases, and Amazon Titan Text Embeddings v2 are available today in all AWS Regions where the services are already available. Check the Region list for details and future updates. To learn more about Amazon Knowledge Bases, visit the Amazon Bedrock Knowledge Bases product page. For more information regarding Amazon Titan Text Embeddings, visit Amazon Titan in Amazon Bedrock. For more information on Amazon OpenSearch Serverless, visit the Amazon OpenSearch Serverless product page. For pricing details, review the Amazon Bedrock pricing page.
Give the new feature a try in the Amazon Bedrock console today. Send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS contacts and engage with the generative AI builder community at community.aws.
About the Authors
Shreyas Subramanian is a principal data scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks.
Ron Widha is a Senior Software Development Manager with Amazon Bedrock Knowledge Bases, helping customers easily build scalable RAG applications.
Satish Nandi is a Senior Product Manager with Amazon OpenSearch Service. He is focused on OpenSearch Serverless and has years of experience in networking, security and AI/ML. He holds a bachelor’s degree in computer science and an MBA in entrepreneurship. In his free time, he likes to fly airplanes and hang gliders and ride his motorcycle.
Vamshi Vijay Nakkirtha is a Senior Software Development Manager working on the OpenSearch Project and Amazon OpenSearch Service. His primary interests include distributed systems.