In the rapidly evolving world of generative AI image modeling, prompt engineering has become a crucial skill for developers, designers, and content creators. By crafting effective prompts, you can harness the full potential of advanced diffusion transformer text-to-image models, enabling you to produce high-quality images that align closely with your creative vision. Amazon Bedrock offers access to powerful models such as Stable Image Ultra and Stable Diffusion 3 Large, which are designed to transform text descriptions into stunning visual outputs. Stability AI’s newest launch of Stable Diffusion 3.5 Large (SD3.5L) on Amazon SageMaker JumpStart enhances image generation, human anatomy rendering, and typography by producing more diverse outputs and adhering closely to user prompts, making it a significant upgrade over its predecessor.
In this post, we explore advanced prompt engineering techniques that can enhance the performance of these models and facilitate the creation of compelling imagery through text-to-image transformations.
Understanding the Prompt Structure
Prompt engineering is a valuable technique for effectively using generative AI image models. The structure of a prompt directly affects the generated images’ quality, creativity, and accuracy. Stability AI’s latest models enhance productivity by helping users achieve quality results. This guide offers practical prompting tips for the Stable Diffusion 3 family of models, allowing you to refine image concepts quickly and precisely. A well-structured Stable Diffusion prompt typically consists of the following key components:
Subject – This is the main focus of your image. You can provide extensive details, such as the gender of a character, their clothing, and the setting. For example, “A corgi dog sitting on the front porch.”
Generated by SD3 Large
Generated by SD Ultra
Generated by SD3.5 Large
Medium – This refers to the material or technique used in creating the artwork. Examples include “oil paint,” “digital art,” “voxel art,” or “watercolor.” A complete prompt might read: “3D Voxel Art; wide angle shot of a bright and colorful world.”
Generated by SD3 Large
Generated by SD Ultra
Generated by SD3.5 Large
Style – You can specify an art style (such as impressionism, realism, or surrealism). A more detailed prompt could be: “Impressionist painting of a lady in a sun hat in a blooming garden.”
Generated by SD3 Large
Generated by SD Ultra
Generated by SD3.5 Large
Composition and framing – You can describe the desired composition and framing of the image. This could include specifying close-up shots, wide-angle views, or particular compositional techniques. Consider the images generated by the following prompt: “Wide-shot of two friends lying on a hilltop, stargazing against an open sky filled with stars.”
Generated by SD3 Large
Generated by SD Ultra
Generated by SD3.5 Large
Lighting and color:You can describe the lighting or shadows in the scene. Terms like “backlight,” “hard rim light,” and “dynamic shadows” can enhance the feel of the image. Consider the following prompt and images generated with it: “A yellow umbrella left open on a rainy street, surrounded by neon reflections, with hard rim light outlining its shape against the wet pavement, adding a moody glow.”
Generated by SD3 Large
Generated by SD Ultra
Generated by SD3.5 Large
Resolution – Specifying resolution helps control image sharpness. For example: “A winding river through a snowy forest in 4K, illuminated by soft winter sunlight, with tree shadows across the snow and icy reflections.”
Generated by SD3 Large
Generated by SD Ultra
Generated by SD3.5 Large
Treat the SD3 generation of models as a creative partner. By expressing your ideas clearly in natural language, you give the model the best opportunity to generate an image that aligns with your vision.
Prompting techniques
The following are key prompting techniques to employ:
Descriptive language – Unlike previous models that required concise prompts, SD3.5 allows for detailed descriptions. For instance, instead of simply stating “a man and woman,” you can specify intricate details such as clothing styles and background settings. This clarity helps in achieving better adherence to the desired output.
Negative prompts – Negative prompting offers enhanced control over colors and content by removing unwanted elements, textures, or hues from the image. Whereas the main prompt establishes the image’s broad composition, negative prompts allow for honing in on specific elements, yielding a cleaner, more polished result. This added refinement helps keep distractions to a minimum, aligning the final output closely with your intended vision.
Using multiple text encoders –The SD3 generation of models features three text encoders that can accept varied prompts. This allows you to experiment with assigning general themes or styles to one encoder while detailing specific subjects in another.
Tokenization – Perfecting the art of prompt engineering for the Stable Diffusion 3 model family requires a deep understanding of several key concepts and techniques. At the core of effective prompting lies the process of tokenization and token analysis. It’s crucial to comprehend how the SD3 family breaks down your prompt text into individual tokens, because this directly impacts the model’s interpretation and subsequent image generation. By analyzing these tokens, you can identify potential issues such as out-of-vocabulary words that might split into sub-word tokens, multi-word phrases that don’t tokenize together as expected, or ambiguous tokens like “3D” that could be interpreted in multiple ways. For instance, in the prompt “A realistic 3D render of a red apple,” the clarity of tokenization can significantly affect the quality of the output image.
Generated by SD3 Large
Generated by SD Ultra
Generated by SD3.5 Large
Prompt weighting – Prompt weighting and emphasis techniques allow you to fine-tune the importance of specific elements within your prompt. By using syntax like “A photo of a (red:1.2) apple,” you can increase the significance of the color “red” in the generated image. Similarly, emphasizing multiple aspects, as in “A (photorealistic:1.4) (3D render:1.2) of a red apple,” can help achieve a more nuanced result that balances photorealism with 3D rendering qualities. “(photorealistic 1.4)” indicates that the image should be photorealistic, with a weight of 1.4. The higher weight (>1.0) emphasizes that the photorealistic quality is more important than usual. Although you can technically set weights higher than 5.0, it’s advisable to stay within the range of 1.5–2.0 for effective results. This level of control enables you to guide the model’s focus more precisely, resulting in outputs that more closely align with your creative vision.
A photo of a (red:1.2) apple
A (photorealistic:1.4) (3D render:1.2) of a red apple
Practical settings for optimal results
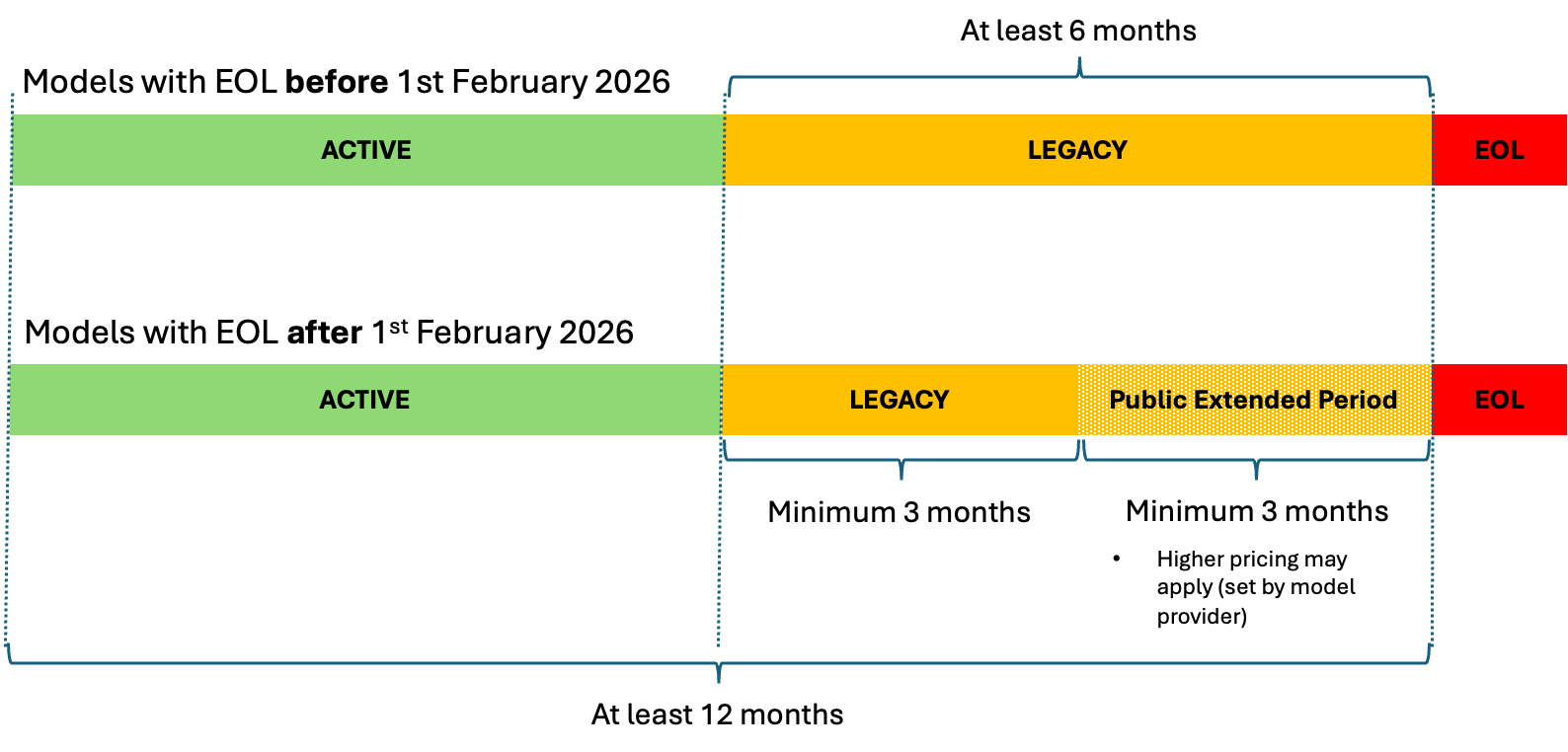
To optimize the performance for these models, several key settings should be adjusted based on user preferences and hardware capabilities. Start with 28 denoising steps to balance image quality and generation time. For the Guidance Scale (CFG), set it between 3.5–4.5 to maintain fidelity to the prompt without creating overly contrasted images. ComfyUI is an open source, node-based application that empowers users to generate images, videos, and audio using advanced AI models, offering a highly customizable workflow for creative projects. In ComfyUI, using the dpmpp_2m sampler along with the sgm_uniform scheduler yields effective results. Additionally, aim for a resolution of approximately 1 megapixel (for example, 1024×1024 for square images) while making sure that dimensions are divisible by 64 for optimal output quality. These settings provide a solid foundation for generating high-quality images while efficiently utilizing your hardware resources, allowing for further adjustments based on specific requirements.
Prompt programming
Treating prompts as a form of programming language can also yield powerful results. By structuring your prompts with components like subjects, styles, and scenes, you create a modular system that’s simple to adjust and extend. For example, using syntax like “A red apple [SUBJ], photorealistic [STYLE], on a wooden table [SCENE]” allows for systematic modifications and experimentation with different elements of the prompt.
Prompt augmentation and tuning
Lastly, prompt augmentation and tuning can significantly enhance the effectiveness of your prompts. This might involve incorporating additional data such as reference images or rough sketches as conditioning inputs alongside your text prompts. Furthermore, fine-tuning models on carefully curated datasets of prompt-image pairs can improve the associations between textual descriptions and visual outputs, leading to more accurate and refined results. With these advanced techniques, you can push the boundaries of what’s possible with SD3.5, creating increasingly sophisticated and tailored images that truly bring your ideas to life.
Responsible and ethical AI with Amazon Bedrock
When working with Stable Diffusion models through Amazon Bedrock, Amazon Bedrock Guardrails can intercept and evaluate user prompts before they reach the image generation pipeline. This allows for filtering and moderation of input text to prevent the creation of harmful, offensive, or inappropriate images. The system offers configurable content filters that can be adjusted to different strength levels, giving fine-tuned control over what types of image content are permitted to be generated. Organizations can define denied topics specific to image generation, such as blocking requests for violent imagery or explicit content. Word filters can be set up to detect and block specific phrases or terms that may lead to undesirable image outputs. Additionally, sensitive information filters can be applied to protect personally identifiable information (PII) from being incorporated into generated images. This multi-layered approach helps prevent misuse of Stable Diffusion models, maintain compliance with regulations around AI-generated imagery, and provide a consistently safe user experience when using these powerful image generation capabilities. By implementing Amazon Bedrock Guardrails, organizations can confidently deploy Stable Diffusion models while mitigating risks and adhering to ethical AI principles.
Conclusion
In the dynamic realm of generative AI image modeling, understanding prompt engineering is essential for developers, designers, and content creators looking to unlock the full potential of models like Stable Diffusion 3.5 Large. This advanced model, available on Amazon Bedrock, enhances image generation by producing diverse outputs that closely align with user prompts. Effective prompting involves understanding the structure of prompts, which typically includes key components such as the subject, medium, style, and resolution. By clearly defining these elements and employing techniques like prompt weighting and chaining, you can refine your creative vision and achieve high-quality results.
Additionally, the process of tokenization plays a crucial role in how prompts are interpreted by the model. Analyzing tokens can help identify potential issues that may affect output quality. You can also enhance your prompts through modular programming approaches and by incorporating additional data like reference images. By fine-tuning models on datasets of prompt-image pairs, creators can improve the associations between text and visuals, leading to more accurate results.
This post provided practical tips and techniques to optimize performance and elevate the creative possibilities within Stable Diffusion 3.5 Large, empowering you to produce compelling imagery that resonates with their artistic intent. To get started, see Stability AI in Amazon Bedrock. To explore what’s available on SageMaker JumpStart, see Stability AI builds foundation models on Amazon SageMaker.
About the Authors
Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area working with GENAI Model providers and helping customer optimize their GENAI workloads on AWS. She helps enterprise customers grow by understanding their goals and challenges, and guides them on how they can architect their applications in a cloud-native manner while ensuring resilience and scalability. She’s passionate about machine learning technologies and environmental sustainability.
Sanwal Yousaf is a Solutions Engineer at Stability AI. His work at Stability AI focuses on working with enterprises to architect solutions using Stability AI’s Generative models to solve pressing business problems. He is passionate about creating accessible resources for people to learn and develop proficiency with AI.